网站爬取-案例三:今日头条抓取(ajax抓取JS数据)
2024-10-21 09:32:21
今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方法不太一样,对它的抓取需要抓取后台传来的JSON数据,先来看一下今日头条的源码结构:我们抓取文章的标题,详情页的图片链接试一下:

看到上面的源码了吧,抓取下来没有用,那么我看下它的后台数据:‘
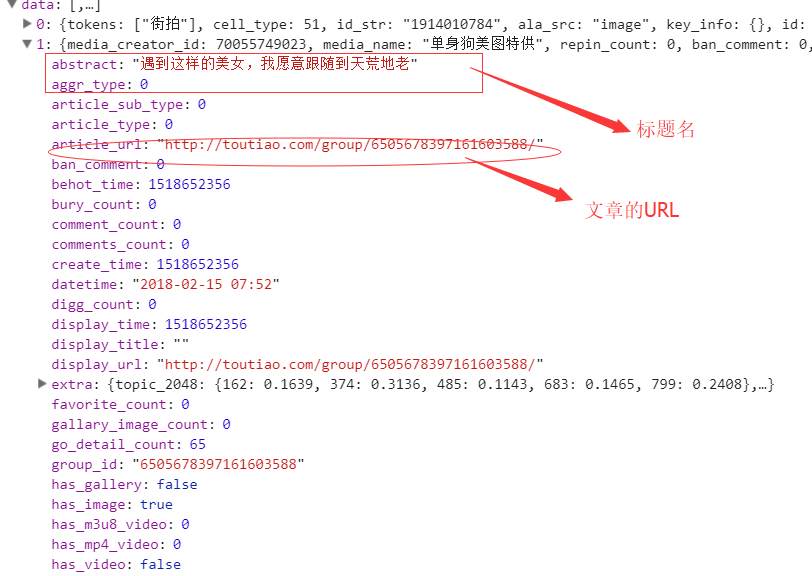
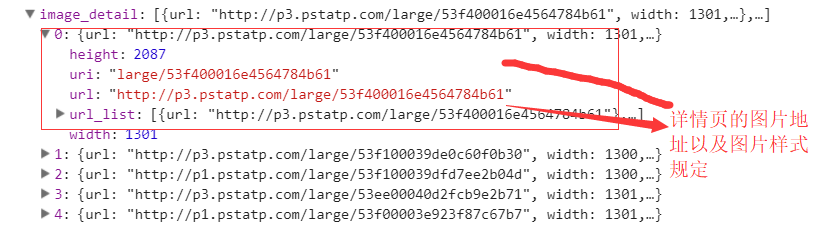
所有的数据都在后台的JSON展示中,所以我们需要通过接口对数据进行抓取


提取网页JSON数据
执行函数结果,如果你想大量抓取记得开启多进程并且存入数据库:

看下结果:

总结一下:网上好多抓取今日头条的案例都是先抓去指定主页,获取文章的URL再通过详情页,接着在详情页上抓取,但是现在的今日头条的网站是这样的,在主页的接口数据中就带有详情页的数据,通过点击跳转携带数据的方式将数据传给详情页的页面模板,这样开发起来方便节省了不少时间并且减少代码量
最新文章
- golang实现冒泡排序
- python集合类型set
- B’QConf(北京软件质量大会)记
- SyntaxError: Non-UTF-8 code starting with '\xba' in file 错误的解决方法!!
- SharePoint2013TimerJob计时器发送邮件
- ViewFilpper
- git - 简明指南(转)
- POJ 2585 Window Pains 题解
- jmeter3.3测试需要登录的接口(java)
- Android Studio JNI javah遇到的问题
- [Swift]LeetCode241. 为运算表达式设计优先级 | Different Ways to Add Parentheses
- numpy交换列
- 华为路由器帧中继 FR 实验
- day37协程与线程套接字通讯
- Nginx的安装与部署
- sql 语句的limit的用法
- 前端开发周报: CSS 布局方式方式与JavaScript数据结构和算法
- asp.net mvc流程图4.6以前
- 如何寻找linux下相关软件
- hashCode()方法 和 hash()方法