使用Spark开发应用程序,并将作业提交到服务器
2024-09-07 20:50:58
1、pycharm编写spark应用程序
由于一些原因在windows上配置未成功(应该是可以配置成功的)、我是在linux上直接使用pycharm,在linux的好处是,环境可能导致的一切问题不复存在
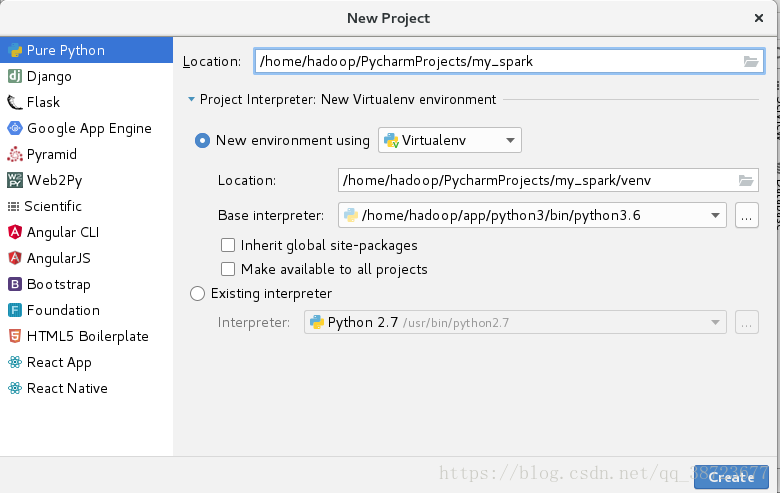
111 新建一个普通python工程
编程环境使用spark使用的python环境
222 配置spark环境
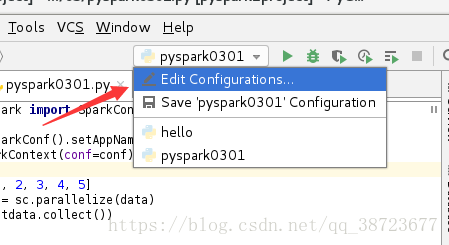
进入下图
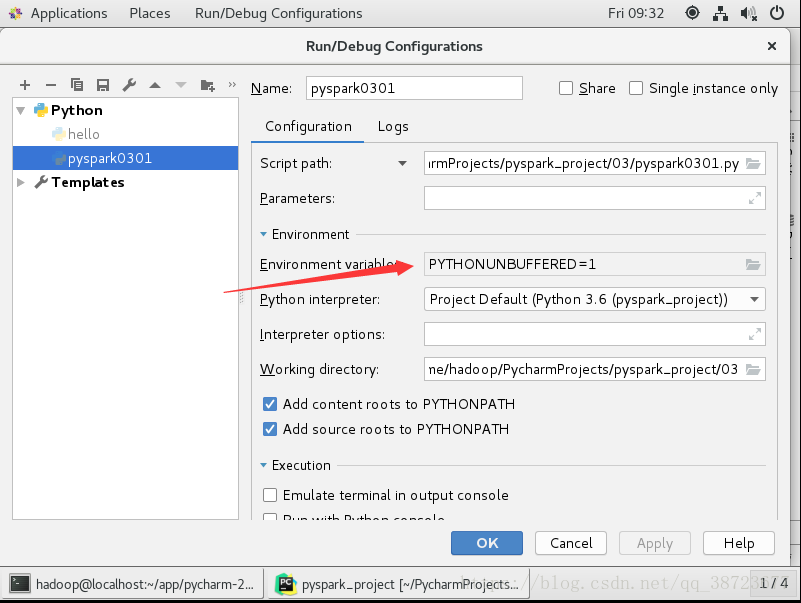
添加2个相应属性
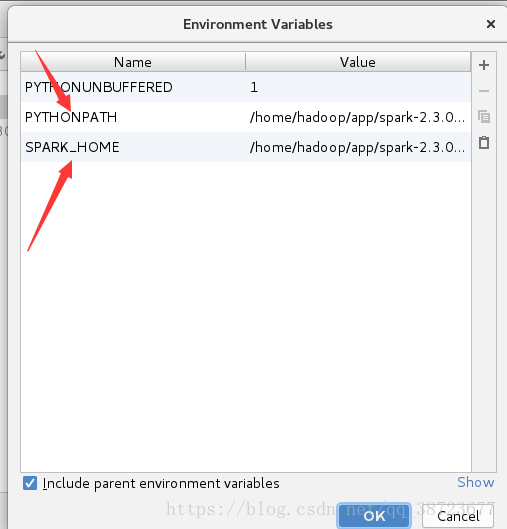
PYTHON_PATH为spark安装目录下的python的路径
我的:/home/hadoop/app/spark-2.3.0-bin-2.6.0-cdh5.7.0/python
SPARK_HOMR为spark安装目录
我的:/home/hadoop/app/spark-2.3.0-bin-2.6.0-cdh5.7.0
完成后
导入两个包进入setting

包位置为spark安装目录下python目录下lib里

2、正式编写
创建一个python文件
from pyspark import SparkConf, SparkContext
# 创建SparkConf:设置的是spark的相关信息
conf = SparkConf().setAppName("spark0301").setMaster("local[2]")
# 创建SparkContext
sc = SparkContext(conf=conf)
# 业务逻辑
data = [1, 2, 3, 4, 5]
# 转成RDD
distdata = sc.parallelize(data)
print(distdata.collect())
# 好的习惯
sc.stop()在linux系统用户家根目录创建一个script

将代码放入spark0301.py中
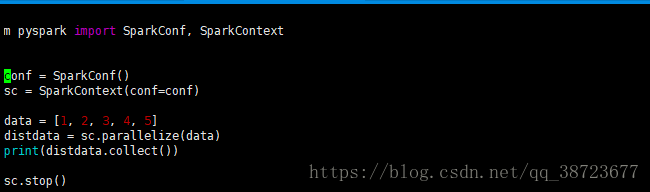
将appname和master去掉,官网说不要硬编码,会被自动赋值
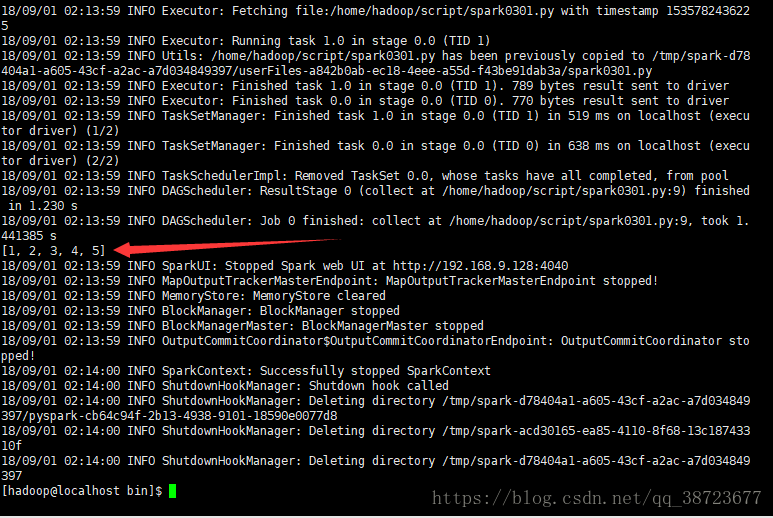
然后进入spark安装目录下bin目录运行
./spark-submit --master local[2] --name spark0301 /home/hadoop/script/spark0301.py
因为速度太快结束网站是看不到的
最新文章
- git 代码更新
- WordPress数据库优化技巧
- JavaScript、全选反选-课堂笔记
- AI (Adobe Illustrator)详细用法(一)
- (转)win32Application和win32ApplicationConsole
- C# UserControl 判断DesignMode
- asp.net操作cookie类
- 【MySQL】(4)操作数据表中的记录
- redis入门(05)redis的key命令
- Sql server2012转sql server2008步骤经验总结(转)
- python布尔类型和逻辑运算
- Netty入门(二)之PC聊天室
- java编程感悟01
- 【转载】vc编译exe的体积最小优化
- poj3320 Jessica's Reading Problem
- Java凝视模板
- GetHashCode作用
- Linux定时备份数据到百度云盘
- require.js vs browserify
- C#关系运算符