三大常用集群leader选举+哨兵模式原理
2024-10-12 10:57:15
一,Zookeeper集群的leader选举 Zookeeper的选举机制两个触发条件:集群启动阶段和集群运行阶段leader挂机(这2种场景下选举的流程基本一致)
1,Zookeeper集群中的follower检测到leader挂机,然后把自己的状态置为LOOKING,开始进行leader选举。
2,每台服务器选举自己为leader,然后把自己的选票通过广播通知其他服务器。
3,每台服务器接收来自其他服务器的选票,并进行合法性校验,主要有两点校验,选举轮次校验和服务器的状态的校验。
4,处理选票。每台服务器都会将自己的选票与其他服务器的选票进行PK,PK的规则如下:
第一个规则:首先进行ZXID的PK,大者获胜。
第二条规则:如果ZXID相等,则进行myid的PK,大者获胜
经过PK以后,如果当前服务器PK失败,则会把自己的选票重新投给胜者,然后把更新后的选票通过广播通知其他服务器。
5,统计选票。根据超过半数的原则,每台服务器都会统计leader的选票,如果超过半数,则结束选举。
6,更新服务器状态。follower把自己的状态更新为FOLLOWING,leader把自己的状态更新为LEADING。
OK,这就是Zookeeper的leader选举机制。经过若干轮选举以后,Zookeeper集群继续对外提供服务。由于选票PK首先比较的是ZXID,所以Zookeeper能够保证leader的数据是最新的。
备注:在ZAB协议中,每个事务都有一个编号ZXID,ZXID由两部分组成,高32位是epoch,低32位为递增计数器。
epoch:选举周期,也就是每换一次Leader,epoch的值加一;
计数器:随事务的到来每次加一,每当换一次Leader,计数器会清零,从零开始加;
当我们搭建zookeeper的集群时,我们需要手动创建一个myid的文件,这个文件里面我们随便写入一个数字,但zk集群里面每个节点的数字都不能相同 二,kafka集群的controller选举
kafka集群保证高可用性
kafka通过Zookeeper管理集群配置、选举leader、consumer group发生变化时进行rebalance。
kafka选举leader
Kafka选举leader的过程是这样的:kafka的所有broker,在Zookeeper的/controller路径下创建临时节点,成功创建的那个broker就会成为leader,其他的broker就会成为follower。
当leader挂机时,临时节点会被删除,这是其他节点通过Zookeeper的watch机制,会监听到leader的变化,然后所有的follower会再次进行leader选举。
kafka的选举其实就是创建临时节点,这和Zookeeper分布式锁的实现原理基本相同。 三,redis集群的主从切换
redis主从切换和redis集群的理解。
redis集群是通过主从切换来保证高可用性的。
redis主从切换有2种方式:手动切换和自动切换。
自动切换,redis主从自动切换需要哨兵模式的支持,哨兵模式简单来说就是:监控master和slave,在master出现故障的时候,自动将slave切换成master,master恢复以后,作为新master的slave对外提供服务。 哨兵模式工作机制+原理 哨兵模式架构
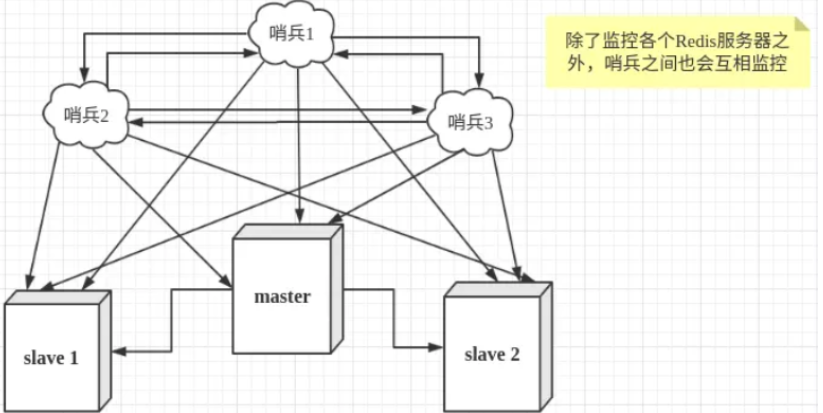
哨兵功能:监控各个服务器+其他哨兵
哨兵模式是Redis的高可用解决方案,哨兵节点是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。 哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过sentinel代理访问redis的主节点,当redis的主节点挂掉时,哨兵会第一时间感知到,并且在slave节点中重新选出来一个新的master,然后将新的master信息通知给client端,从而实现高可用。这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息
哨兵主要任务:
(1)监控:哨兵会不断地检查你的Master和Slave是否运作正常。 (2)提醒:当被监控的某个Redis节点出现问题时,哨兵可以通过 API 向管理员或者其他应用程序发送通知。 (3)自动故障迁移:当一个Master不能正常工作时,哨兵会进行自动故障迁移操作,将失效Master的其中一个Slave升级为新的Master,并让失效Master的其他Slave改为复制新的Master;当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用新Master代替失效Master。
哨兵工作原理:
1、心跳机制:
(1)Sentinel 与 Redis Node:Redis Sentinel 是一个特殊的 Redis 节点。在哨兵模式创建时,需要通过配置指定 Sentinel 与 Redis Master Node 之间的关系,然后 Sentinel 会从主节点上获取所有从节点的信息,之后 Sentinel 会定时向主节点和从节点发送 info 命令获取其拓扑结构和状态信息。 (2)Sentinel与Sentinel:基于 Redis 的订阅发布功能, 每个 Sentinel 节点会向主节点的 sentinel:hello 频道上发送该 Sentinel 节点对于主节点的判断以及当前 Sentinel 节点的信息 ,同时每个 Sentinel 节点也会订阅该频道, 来获取其他 Sentinel 节点的信息以及它们对主节点的判断 通过以上两步所有的 Sentinel 节点以及它们与所有的 Redis 节点之间都已经彼此感知到,之后每个 Sentinel 节点会向主节点、从节点、以及其余 Sentinel 节点定时发送 ping 命令作为心跳检测, 来确认这些节点是否可达 2、判断master节点是否下线:
(1)每个 sentinel 哨兵节点每隔1s 向所有的master、slave以及其他 sentinel 节点发送一个PING命令,作用是通过心跳检测,检测主从服务器的网络连接状态 (2)如果 master 节点回复 PING 命令的时间超过 down-after-milliseconds 设定的阈值(默认30s),则这个 master 会被 sentinel 标记为主观下线,修改其 flags 状态为SRI_S_DOWN (3)当sentinel 哨兵节点将 master 标记为主观下线后,会向其余所有的 sentinel 发送sentinel is-master-down-by-addr消息,询问其他sentinel是否同意该master下线 发送命令:sentinel is-master-down-by-addr <ip> <port> <current_epoch> <runid> ip:主观下线的服务ip port:主观下线的服务端口 current_epoch:sentinel的纪元 runid:*表示检测服务下线状态,如果是sentinel的运行id,表示用来选举领头sentinel (4)每个sentinel收到命令之后,会根据发送过来的 ip和port 检查自己判断的结果,回复自己是否认为该master节点已经下线了 回复内容主要包含三个参数(由于上面发送的runid参数是*,这里先忽略后两个参数) down_state(1表示已下线,0表示未下线) leader_runid(领头sentinal id) leader_epoch(领头sentinel纪元)。 (5)sentinel收到回复之后,如果同意master节点进入主观下线的sentinel数量大于等于quorum,则master会被标记为客观下线,即认为该节点已经不可用。 (6)在一般情况下,每个 Sentinel 每隔 10s 向所有的Master,Slave发送 INFO 命令。当Master 被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次。作用:发现最新的集群拓扑结构 3、基于Raft算法选举领头sentinel: 到现在为止,已经知道了master客观下线,那就需要一个sentinel来负责故障转移,那到底是哪个sentinel节点来做这件事呢?需要通过选举实现,具体的选举过程如下: (1)判断客观下线的sentinel节点向其他 sentinel 节点发送 SENTINEL is-master-down-by-addr ip port current_epoch runid 注意:这时的runid是自己的run id,每个sentinel节点都有一个自己运行时id (2)目标sentinel回复是否同意master下线并选举领头sentinel,选择领头sentinel的过程符合先到先得的原则。举例:sentinel1判断了客观下线,向sentinel2发送了第一步中的命令,sentinel2回复了sentinel1,说选你为领头,这时候sentinel3也向sentinel2发送第一步的命令,sentinel2会直接拒绝回复 (3)当sentinel发现选自己的节点个数超过 majority 的个数的时候,自己就是领头节点 (4)如果没有一个sentinel达到了majority的数量,等一段时间,重新选举 4、故障转移: 有了领头sentinel之后,下面就是要做故障转移了,故障转移的一个主要问题和选择领头sentinel问题差不多,到底要选择哪一个slaver节点来作为master呢?按照我们一般的常识,我们会认为哪个slave节点中的数据和master中的数据相识度高哪个slaver就是master了,其实哨兵模式也差不多是这样判断的,不过还有别的判断条件,详细介绍如下: (1)在进行选择之前需要先剔除掉一些不满足条件的slaver,这些slaver不会作为变成master的备选 剔除列表中已经下线的从服务
剔除有5s没有回复sentinel的info命令的slave
剔除与已经下线的主服务连接断开时间超过 down-after-milliseconds * 10 + master宕机时长 的slaver
(2)选主过程: ① 选择优先级最高的节点,通过sentinel配置文件中的replica-priority配置项,这个参数越小,表示优先级越高 ② 如果第一步中的优先级相同,选择offset最大的,offset表示主节点向从节点同步数据的偏移量,越大表示同步的数据越多 ③ 如果第二步offset也相同,选择run id较小的
最新文章
- Linux下的ctrl常用组合键
- oracle11g RAC1执行脚本结果
- tsql语句分析工具 转
- Android常见的控件
- NGINX将PHP带参数的URL地址重定向二级或多级域名访问
- [PHP] php实现文件下载
- 变态跳台阶-一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
- Mime Types
- 使用spring.net 1.3.2框架部署在虚拟目录上发生错误
- jira汉化
- test--2
- this的学习
- [转]Ubuntu 16.04安装有道词典
- 转载:SDWebImage支持URL不变时更新图片内容
- Websphere设置JVM时区解决程序、日志时间快8小时问题
- String,StringBuilder和StringBuffer的特点和使用场景
- 7.25 8figting!
- CentOS 6.5中配置RabbitMQ
- Arduino UNO仿真开发环境设置和仿真运行
- oracle常用函数总结