(一)REDIS之常见数据结构及操作
(一)基本数据结构
1.1 String结构:
String底层结构是动态字符串,可修改指定位置数据,通过预分配冗余空间减少内存的频繁分配,实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。字符串最大长度为512M(512*1024*1024个字符)。
type key
object encoding key
object refcount key
编码格式:
int: 保存long型数据,最大表示2的64位(8个字节)的有符号整数
|
type (Redis_STRING) |
|---|
|
encoding (OBJ_ENCODING_INT) |
|
lru |
|
refcount |
|
ptr(100) |
Redis启动时会预先建立10000个分别存储0—9999的Redis变量作为共享对象,这就意味着如果set字符串的键值在0-10000之间的话,则可以直接指向共享对象,而不需要在建立新对象,此时键值不占空间。
emstr:代表embstr格式的SDS(Simple Dynamic String),保存长度小于44字节的字符串。
|
type (Redis_STRING) |
|---|
|
encoding (OBJ_ENCODING_INT) |
| lru |
| refcount |
| ptr(100) |
| len |
| alloc |
| flags |
| buf("abc) |
raw:保存长度大于44字节的字符串。
|
1 int |
Long类型整数时,RedisObject中的ptr指针直接赋值为整数数据,不再额外的指针指向整数了,节省了指针的空间开销。 |
|---|---|
|
2 embstr |
当保存的是字符串数组并且长度小于44字节时,embstr类型将会调用内存的分配函数,只分配一块连续的内存,空间中一次包含 redisObject与sdshdr两个数据结构让元数据、指针和sds是一块连续的内存区域,这就可以避免内存碎片 |
|
3 raw |
当字符串大于44字节时,sds的数据量变得大了,会给sds分配多的空间并用指针指向sds结构,raw类型将会调用两次内存分配函数, 分配两块内存空间。分别给redisObject和sdshdr |
C语言字符串与SDS的区别:
| 区别 | C语言 | SDS |
|---|---|---|
| 字符串长度处理 | 需要从头开始遍历,直到遇到‘\0'为止,时间复杂度为O(n) | 记录当前字符串的长度,直接读取即可,时间复杂度O(1) |
| 内存重新分配 | 分配内存空间超过后,会导致数组下标越级或者内存分配溢出 |
空间预分配: SDS修改后,长度小于1M,那么每次扩容就会增加一倍。如果大于1M,那么将分配1M的使用空间。 惰性空间释放: SDS缩短时并不会回收多余的内存空间,而是使用Free字段将多出来的空间记录下来。如果后续有变更操作,就直接使用Free中记录的空间,减少内存的分配。 |
| 二进制安全 | 二进制数据并不是规则的字符串格式,可能会包换一些特殊的字符,比如'\n'.前面提到过,C中字符串遇到的'\n'会结束,那么之后的字符读取就读不上了 | 根据len长度来判断字符串结束,二进制安全的问题得以解决。 |
1.2 hash数据结构:
config get hash*
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
config set hash-max-ziplist-entries 512
config set hash-max-ziplist-value 64
编码格式:
1ziplist : Ziplist是一种紧凑的编码格式,通过牺牲读写性能来换取内存空间的利用率,一般用于字段个数少,且字段是较小的场景。压缩列表内存利用率极高的原因是因为其连续内存的特性。在访问的时候,通过每个元素的长度,计算偏移量来进行前后访问。
ziplist结构:
| zlbytes | zlatil | zllen | entry1 | entry2 | ... | entryN | zlend |
|---|
ziplist 的entry组成:
|
prevrawlensize 上一个节点的长度所占的字节数 |
|---|
|
prevrawlen 上一个节点所占的长度 |
|
lensize 编码当前节点长度len所需要的字节数 |
|
len 当前节点长度 |
|
当前节点的header大小 headersize= lensize + prevrawlensize headersize |
|
encoding 当前节点的编码方式 |
|
当前节点指针 p |
压缩列表与java中的链表的区别:普通的双向链表有两个指针,在存储数量很小的情况下,很有可能指针占用的内存相对于数据来说比较大。而Ziplist是没有维护双向链表的,通过存储上一个entry的长度和当前entry的长度,就可以推算下一个元素在什么地方。 此外链表在内存中一般不是连续的,遍历访问相对麻烦。但是Ziplist根据偏移量信息可以访问到上一个或下一个节点。最后,Ziplist保存了len,和String类型的sds类似,获取链表长度无需遍历整个链表,复杂度为O(1).
1.3 list结构:
在低版本的Redis中,list采用的底层数据结构是ziplist+linkedList, 高版本中采用的时quicklist,而quicklist也用到了ziplist。
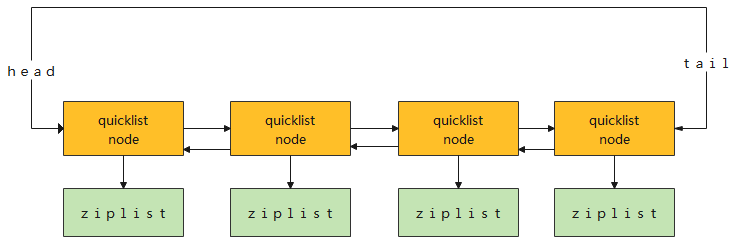
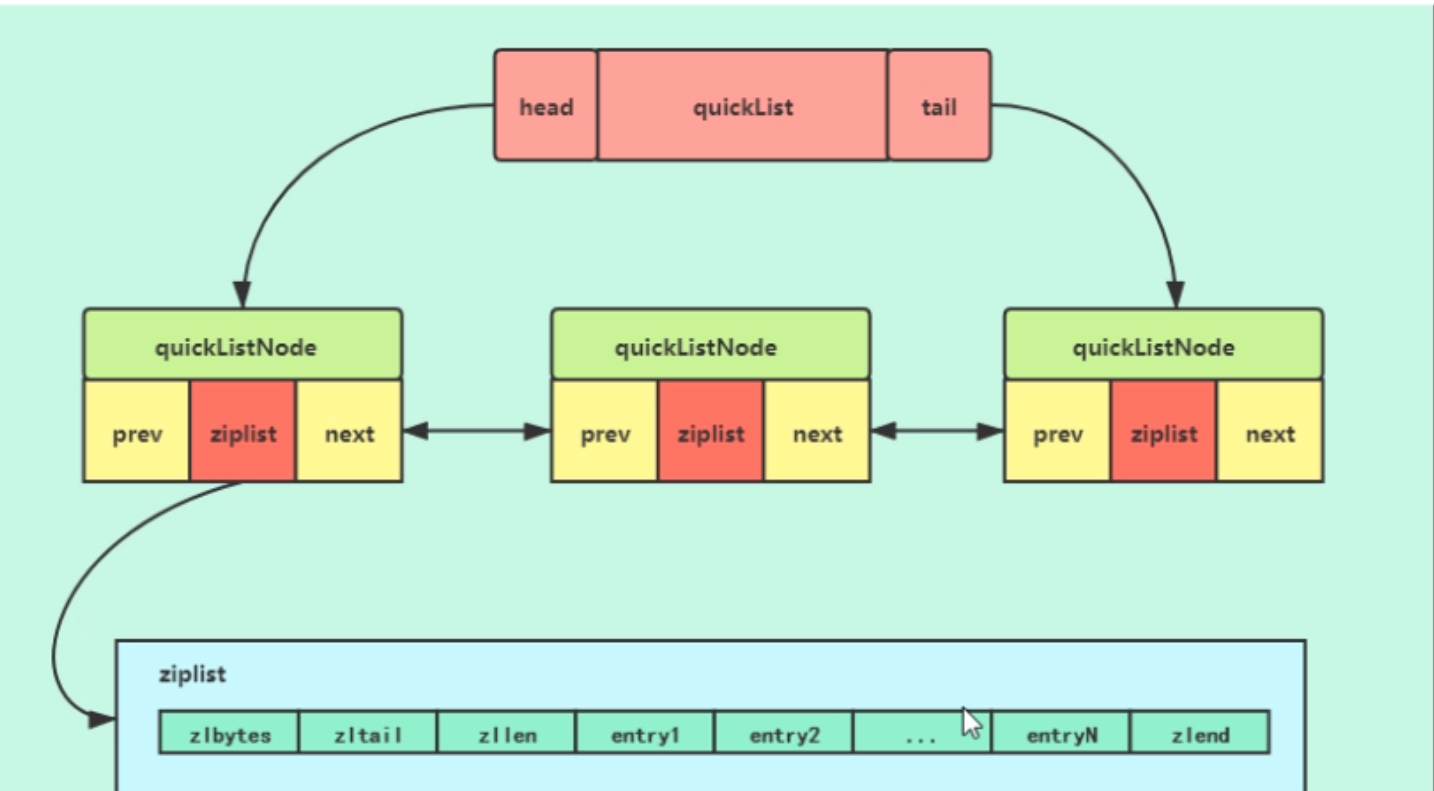
1.4 set结构:
Redis用intset或者hashtable存储set的。如果元素都是整数类型,就用intset存储。如果不是整数类型,就用hashtable(数组+链表)。key是元素的值,value为null.
config get set*
"set-max-intset-entries"
"512"
1.5 zset结构:
config get zset*
1) "zset-max-ziplist-entries"
2) "128"
3) "zset-max-ziplist-value"
4) "64"
编码方式 :
1 ziplst
2 skiplist: 跳表是一种以空间换时间的结构,由于链表,无法进行二分查找,因此借鉴数据库索引的思想,提取出链表中的关键节点(索引),先在关键节点上查找,在进入下层链表查找。提取多层关键节点,就形成了跳表。使用场景一般是在数据量较大,读多写少的情况下使用。原因是新增或者删除需要把所有索引都更新一遍,维护成本比较高。
跳表=链表+多级索引(两两取首)。时间复杂度O(logN),空间复杂度O(N)
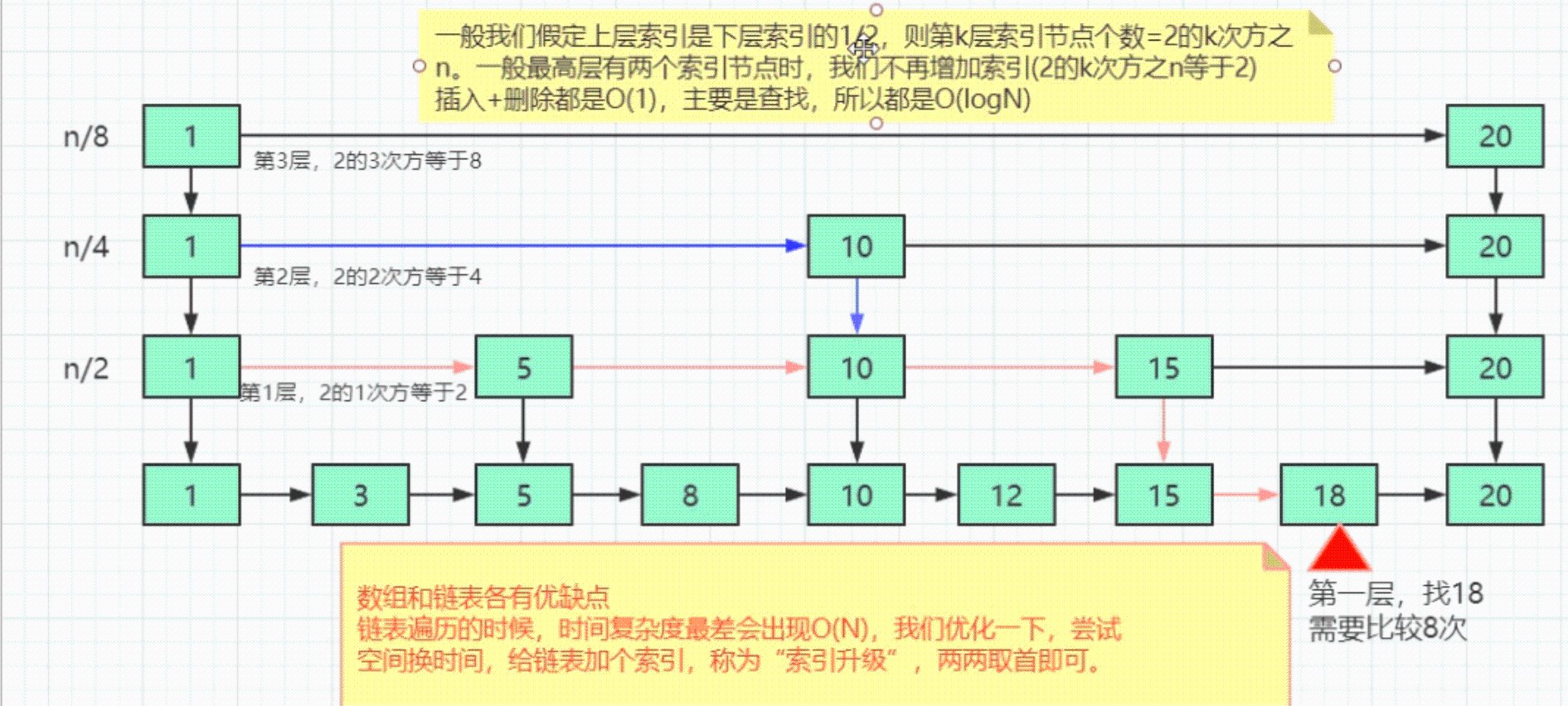
总结:
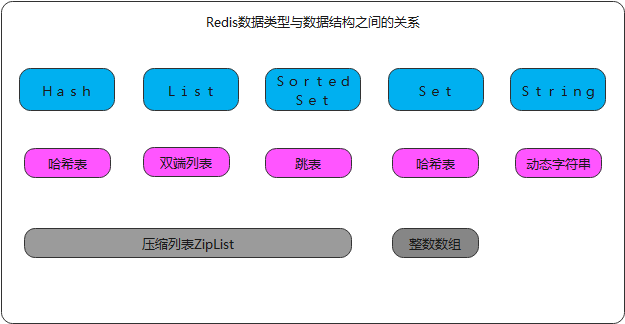
1 字符串:int:8个字节的长整型。embstr:小于等于44个字节的字符串。raw:大于44个字节的字符串。
2 哈希:当哈希类型的元素个数小于hash-max-ziplist-entries配置(默认512个),并且所有值都小于hash-max-ziplist-value配置(默认64字节时),使用ziplist作为底层实现。否则用hashtable作为底层实现。
3 列表:当列表的元素小于list-max-ziplist-entries配置(512个),同时列表的每个元素的值都小于list-max-ziplist-value配置(默认64字节时),使用ziplist作为底层实现。否则会使用quickList作为底层实现(低版本用lnkedlist+ziplist)
4 集合:当元素集合中的元素都是整数且个数小于set-max-intset-entries配置(默认512个)时,使用intset作为集合内部的底层实现,从而减少内存的使用。否则使用hashtable作为底层实现。
5 有序集合:当有序集合的元素个数小于zset-max-ziplist-entries配置(默认128个),同时每隔元素的值都小于zset-max-ziplist-value(64字节)时,用ziplist作为底层实现以减少内存的使用。否则skiplist作为底层实现。
|
名称 |
时间复杂度 |
|---|---|
|
哈希表 |
O(1) |
|
跳表 |
O(logN) |
|
双向链表 |
O(N) |
|
压缩列表 |
O(N) |
|
整数数组 |
O(N) |
(二)常用操作命令:
2.1 字符串类型数据常用操作:
应用场景:分布式锁; 计数器; 分布式全局唯一ID;
|
操作 |
命令 | 作用 | 参数 |
|---|---|---|---|
|
单元素操作:Redis2.6.12+版本支持设置value值时, 同时设置过期时间,此操作为原子操作; 【PSETEX】:Redis2.6.0+版本支持,可将过期时间精确到毫秒; |
SET | 设置value值,支持选项 | key value [expiration EX seconds/PX milliseconds] [NX/XX] |
| SETNX | key不存在才允许设置 | key value | |
| SETEX | 设置value及过期时间(秒) | key seconds value | |
| PSETEX | 设置value及过期时间(毫 秒) | key milliseconds value | |
| GET | 查询指定key | key | |
| GETSET | 查询返回旧值设置新值 | key value | |
| APPEND | value追加字符串 | key value | |
| STRLEN | 查询value长度 | key | |
|
批量操作:MGET、MSET是Redis命令中的Boss, 因为执行这两个命令是绝不会失败的。 【MSET】操作具有原子性,不存在部分key更新成功而部分key更新失败的情况; 【MGET】如果value不是String类型,将返回nil; |
MSET | 批量设置 | key value [key value ...] |
| MGET | 批量查询 | key [key ...] | |
|
指定范围处理: 【SETRANGE、GETRANGE】 在操作对象较小时,时间复杂度近似看成O(1); 【SETRANGE】在特定情况下会造成服务器阻塞(value不存在或很小+偏移量offset很大),具体阻塞时长与服务器有关; |
SETRANGE | 设置指定偏移量位置的字符 | key offset value |
| GETRANGE | 查询指定区间字符串 | key start end【@LBN;offset大于len将自动以len为准】 | |
|
递增操作 |
INCR/DECR | 递增/1递减1 | key |
| INCRBY/DECRBY | 递增n/递减n | key increment(支持负数) | |
| INCRBYFLOAT | 递增浮点值 | key increment(支持负数) | |
|
位操作 |
SETBIT | 指定偏移量bit位置设置值 | key offset value【0=< offset< 2^32】 |
| BITOP | 对一个或多个key执行逻辑操作,并将结果保存到destkey | operation destkey key [key ...]【AND, OR, XOR, NOT】 | |
| GETBIT | 查询指定偏移位置的bit值 | key offset | |
| BITCOUNT | 统计指定区间bit为1的数量 | key [start end]【@LBN】 | |
| BITFIELD | 操作多字节位域 | key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP/SAT/FAIL] | |
| BITPOS | 查询指定区间第一个被设置成1的bit位的位置 | key bit [start] [end]【@LBN】 |
2.2 list类型数据的基本操作
List可用于构建队列(右进左出/先进先出)、栈(右进右出/先进后出); 存储相关数据,比如文章的相关文章ID,可用于文章推荐; 高级使用:quicklist快速链表;
| 操作 | 命令 | 功能 | 参数 |
|---|---|---|---|
| 新增元素 | LPUSH / RPUSH | (批量)添加元素 | key value [value ...] |
| LPUSHX / RPUSHX | 向已存在的list中添加单个元素 | key value | |
| RPOPLPUSH | 弹出source尾压入dest头部 | source destination | |
| BRPOPLPUSH | 阻塞式弹出source压入dest | source destination timeou | |
| 弹出元素 | LPOP / RPOP | 弹出元素 | key |
| BLPOP / BRPOP | 阻塞式弹出元素 | key [key ...] timeout | |
| 处理指定位置的元素 | LSET | 指定位置设置元素 | key index value |
| LINDEX | 查询指定位置元素 | key index | |
| LRANGE | 查询指定区间元素 | key start stop | |
| LTRIM | 保留指定区间元素 | key start stop | |
| LREM | 移除前/后count次的value元素 | key count value |
2.3 set类型数据的基本操作
类似Java的HashSet,键值无序唯一,可用于去重;
应用场景:微信小程序抽奖、微信朋友圈点赞、微博好友关注社交关系、qq内推可能认识的人。
set类型数据操作注意事项:set 类型不允许数据重复,如果添加的数据在 set 中已经存在,将只保留一份。
set 虽然与hash的存储结构相同,但是无法启用hash中存储值的空间.
| 操作 | 作用 | 命令 |
|---|---|---|
| 增删改 | 添加数据 | sadd key member1 [member2] |
| 获取全部数据 | smembers key | |
| 删除数据 | srem key member1 [member2] | |
| 获取长度、判断是否存在 | 获取集合数据总量 | scard key |
| 判断集合中是否包含指定数据 | sismember key member | |
| 随机获取元素 | 随机获取集合中指定数量的数据 | srandmember key [count] |
|
随机获取集中的某个数据并将该 数据移除集合 |
spop key [count] | |
| 求两个集合的交、并、差集 | 求两个集合的交集 | sinter key1 [key2 …] |
| 求两个集合的并集 | sunion key1 [key2 …] | |
| 求两个集合的差集 | sdiff key1 [key2 …] | |
| 求两个集合的交、并、差集并存储到指定集合中 |
交集 | sunionstore destination key1 [key2 …] |
| 并集 | sunionstore destination key1 [key2 …] | |
| 差集 | sdiffstore destination key1 [key2 …] | |
| 将指定数据从原始集合中移动到目标集合中 | smove source destination member |
2.4 hash类型数据的基本操作
类似Java的HashMap,数组+链表,结构是<rediskey , <hashkey1, hashvalue1>>; 字典key、value都只能是字符串(数字在redis里面是以 sds 字符串形式存在);
使用渐进式rehash策略:高性能,不堵塞服务;而HashMap的rehash是一次性hash,很耗时; 【优点】支持按需存取指定字段; 【缺点】hash结构存储消耗高于单个字符串;
应用场景:记录一个对象的多个属性,如员工的姓名/生日/职级,文章的点赞数/阅读数/收藏数;
| 操作 | 命令 | 参数 |
|---|---|---|
| field不存在才设置hash中指定field的值 | HSETNX | key field value |
| 批量设置hash值 | HMSET | key field value [field value ...] |
| 查询hash中指定字段的值 | HGET | key field |
| 批量查询指定field的value | HMGET | key field [field ...] |
| 查询所有field-value列表 | HGETALL | key |
| 查询hash的field数量 | key | key |
| 查询所有value列表 | HVALS | key |
| 查询hash的field数量 | HLEN | key |
| 移除hash中指定field字段 | HDEL | key field [field ...] |
| 判断hash中是否存在指定field | HEXISTS | key field |
| 查询hash中filed关联的value字符串的长度 | HSTRLEN | key field |
| 增加hash中指定field的值 | HINCRBY | key field increment |
| 增加hash中指定field的值 | HINCRBYFLOAT | key field increment |
| 基于游标迭代hashes | HSCAN | key cursor [MATCH pattern] [COUNT count] |
2.5 zset类型数据的基本操作:

统计:
1 聚合统计:统计多个集合元素的聚合结果,就是前面讲解过的交差并等集合统计。(mysql的聚合函数)
2 排序统计:zrank key member 、zrevrank key member
3 二值统计:集合元素的值只有0和1两种,见bitmap。(用String类型作为底层数据结构实现的一种统计二值状态的数据类型,实质是二进制的ascii编码。具体命令见String的位操作)
4 基数统计:指统计一个集合中不重复的元素个数,见hyperloglog。
hyperLogLog:通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身。通过一定的概率统计方法预估基数值,同时保证误差在一定范围内,
由于不存储数据因此可以大大节约内存。hyperLogLog就是一种概率算法的实现。(PFADD、PFCOUNT、PFMERGE)。
2.6 Bitmap
public class BitmapClient {
public static void main(String[] args) {
RedissonService redissonService = new RedissonService();
RedissonClient redissonClient = redissonService.getRedissonClient();
RBitSet rBitSet1 =redissonClient.getBitSet("2017-01-11");
rBitSet1.delete();
//i代表学生的学号,rBitSet1: 0-99
for(int i = 0; i <= 99; i++){
//设置为true表示学号为i的学生在key的那天签过到
rBitSet1.set(i,true);
}
RBitSet rBitSet2 =redissonClient.getBitSet("2017-01-12");
rBitSet2.delete();
//rBitSet2: 80-129
for(int i = 0; i <= 49; i++){
rBitSet2.set(i+80,true);
}
RBitSet rBitSet4 =redissonClient.getBitSet(rBitSet1.getName() + "&"+rBitSet2.getName());
rBitSet4.delete();
rBitSet4.or(rBitSet1.getName());
rBitSet4.and(rBitSet2.getName());
System.out.println("连续两天都来的学生数目:"+rBitSet4.cardinality());
rBitSet4.delete();
rBitSet4.or(rBitSet1.getName(),rBitSet2.getName());
System.out.println("两天总共有多少学生签到:"+rBitSet4.cardinality());
rBitSet4.delete();
rBitSet4.xor(rBitSet2.getName(),rBitSet1.getName());
System.out.println("只来一天的学生总数:"+rBitSet4.cardinality());
}
连续两天都来的学生数目:20
两天总共有多少学生签到:130
只来一天的学生总数:110
2.7 HyperLogLog
public class HyperLogLogClient {
public static void main(String[] args) {
RedissonService redissonService = new RedissonService();
RedissonClient redissonClient = redissonService.getRedissonClient();
RHyperLogLog rHyperLogLog =redissonClient.getHyperLogLog("2018-02");
rHyperLogLog.delete();
for(int i = 1; i <= 100; i++){
rHyperLogLog.add("my ip is : " + new Random().nextInt(100));
}
System.out.println(rHyperLogLog.count());
RHyperLogLog rHyperLogLog1 =redissonClient.getHyperLogLog("2018-03");
rHyperLogLog1.delete();
for(int i = 1; i <= 50; i++){
rHyperLogLog1.add("my ip is : "+ new Random().nextInt(50));
}
System.out.println(rHyperLogLog1.count());
System.out.println(rHyperLogLog.countWith(rHyperLogLog1.getName()));
}
}
打印输出:
65
29
76
2.8 GEO
主要分为三步:
将三维的地球变为二维的坐标
在将二维的坐标转换为一维的点快
最后将一维的点块转换为二进制在通过base32编码。
geoadd 用于存储指定的地理空间位置,可以将一个或多个经度、纬度、位置名称添加到指定的key中,语法如下:
geoadd key longitude latitude member {longitude latitude member ...}
geopos 用于从给定的key里返回所有指定的名称(member)的位置(经度和维度),不存在的返回nil,
geopos key member [member ...]
geohash 用于返回保存的地理位置的坐标
geohash key member [member ...]
geodist用于返回两个给定位置的距离
geodist key member1 member2 [m|km|ft|mi]
georadius 用于给定的经纬度为中心,返回键包含的元素中,与中心距离不超过给定最大距离的所有元素位置。
georadius key longitude latitude num [m|km|ft|mi] WITHDIST WITHCOORD COUNT num1 WITHHASH [desc]
WITHDIST:返回位置元素的同时,将位置元素与中心的距离一并返回。距离的单位和给定的范围保持一致。
WITHCOORD:将位置元素的经度和维度也一并返回。
WITHHASH:以52位有符号的形式,返回位置元素经过原始geohash编码的有序集合分值。这个选项主要用于底层应用或者调试,实际作用不大。
COUNT:限定返回的记录数。
georadiusbymember 同于找出指定范围内的元素,中心点是由给定的位置元素决定。
最新文章
- Conquer and Divide经典例子之汉诺塔问题
- 第三方登录分享功能-ShareSDK for iOS适配问题记录
- php设计模式 观察者模式
- TMS320C54x系列DSP的CPU与外设——第8章 流水线
- gVIM 简洁配置 in Windows
- 2014年辛星完全解读Javascript第八节 json
- SQL Where语句中AND与OR的计算次序 .
- Emberjs View and Route
- POJ3185 The Water Bowls(反转法or dfs 爆搜)
- Windows WDDM显卡驱动框架及GPUView工具的使用(1)
- 对STM32的NVIC_PriorityGroupConfig使用及优先级分组方式理解(转)
- CDQ分治 陌上花开(三维偏序)
- Windows Server 2016-Hyper-V 2016新增功能
- ORACLE not available如何解决
- A - Points and Segments CodeForces - 429E
- Thymeleaf学习记录(1)--启动模板及建立Demo
- Mysql删除重复记录,保留id最小的一条
- 3.1Python的判断选择语句
- 合并两个dt
- 2018-2019-2 网络对抗技术 20165202 Exp1 PC平台逆向破解
热门文章
- C++语言程序设计实验一 类与对象
- vue中input触发方法中调用ajax,导致input失去焦点问题
- C++数组(二):二维数组
- 洛谷 P4048更新题面
- SpringBoot 块形式的配置文件写法(简单示例)
- 【Java】取n工作日后的日期(仅排除周六周日)
- JustAuth-第三方登录组件
- 下载接口时出现:Try to run this command from the system terminal. Make sure that you use the correct version of 'pip' installed for your Python interpreter located at 'D:\python\demo\venv\Scripts\...的错误
- Kubernetes--Pod节点选择器nodeSelector(标签)
- GridView.RowCellClick Event