YOLO v6:一个硬件友好的目标检测算法
2024-10-12 10:42:15
本文来自公众号“AI大道理”
YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。
YOLOv6支持模型训练、推理及多平台部署等全链条的工业应用需求,并在网络结构、训练策略等算法层面进行了多项改进和优化,在 COCO 数据集上,YOLOv6 在精度和速度方面均超越其他同体量算法。
YOLOv6是如何改进的呢?

添加图片注释,不超过 140 字(可选)
一、YOLOV6的改进
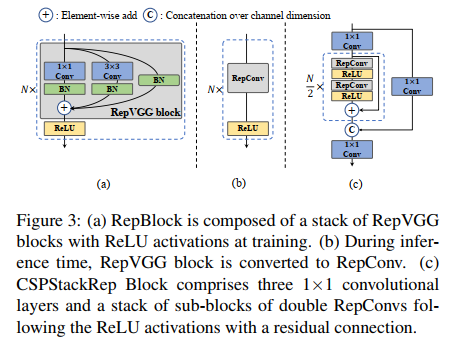
1、backbone:RepBlock+结构重参数化(小型模型)、CSPStackRep Block(大型模型)
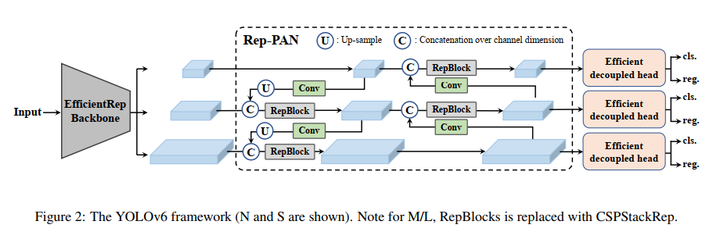
2、neck:Rep PAN
3、head:Decoupled Head
4、标签分配:TAL
5、anchor-free
6、损失函数:VariFocal Loss+SIOU
7、Self-distillation
8、量化+RepOpt-VGG+RepOptimizer+梯度重参数化
编辑切换为居中
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
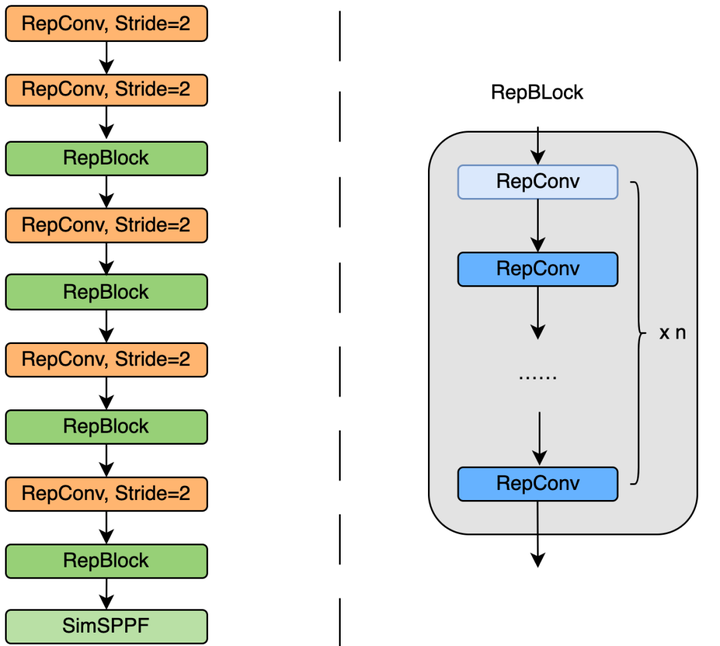
1、EfficientRep backbone
小模型:
在训练中使用 Rep block,如图 3a。
在推理时使用 RepConv,3x3 卷积 + ReLU 堆积而成的结构,如图 3b。
大模型:
使用 CSPStackRep block 来得到中/大模型,如图 3c,3 个 1x1 conv + 2 个 RepVGG(训练) / RepConv(测试) + 1 个残差通道。
编辑
添加图片注释,不超过 140 字(可选)
受到硬件感知神经网络设计思想的启发,基于 RepVGG style 设计了可重参数化、更高效的骨干网络 EfficientRep Backbone 。
YOLOv5/YOLOX 使用的 Backbone 和 Neck 都基于 CSPNet 搭建,采用了多分支的方式和残差结构。对于 GPU 等硬件来说,这种结构会一定程度上增加延时,同时减小内存带宽利用率。
YOLOv6引入了 RepVGG style 结构。
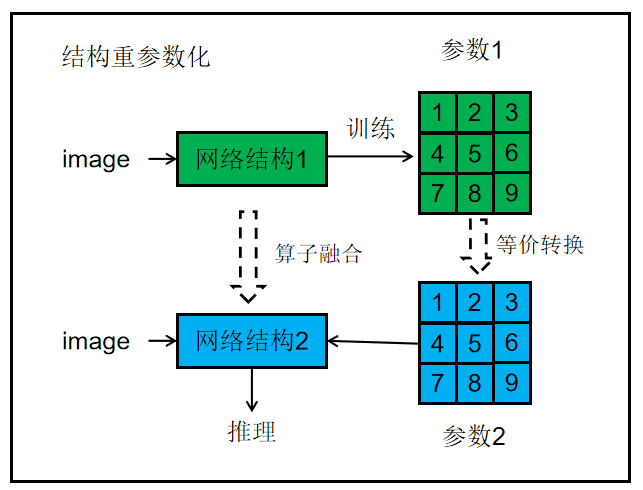
结构重参数化。
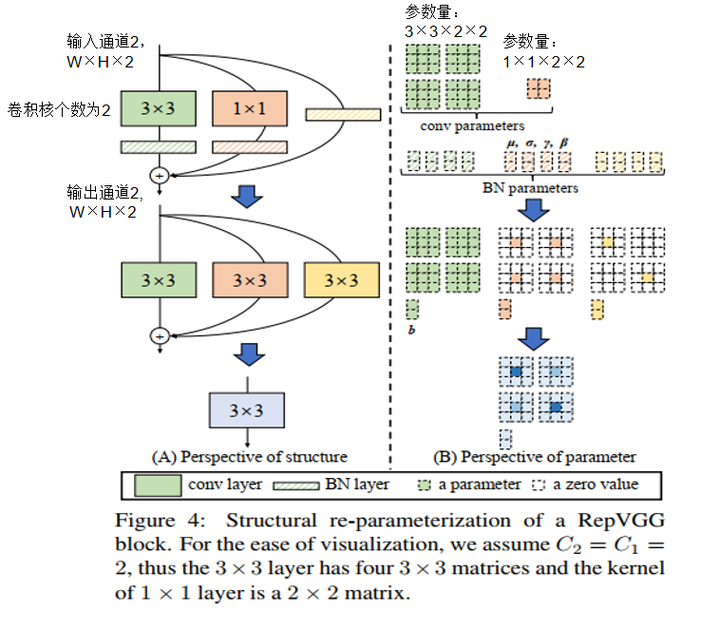
RepVGG Style 结构是一种在训练时具有多分支拓扑,而在实际部署时可以等效融合为单个 3x3 卷积的一种可重参数化的结构。通过融合成的 3x3 卷积结构,可以有效利用计算密集型硬件计算能力。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑切换为居中
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
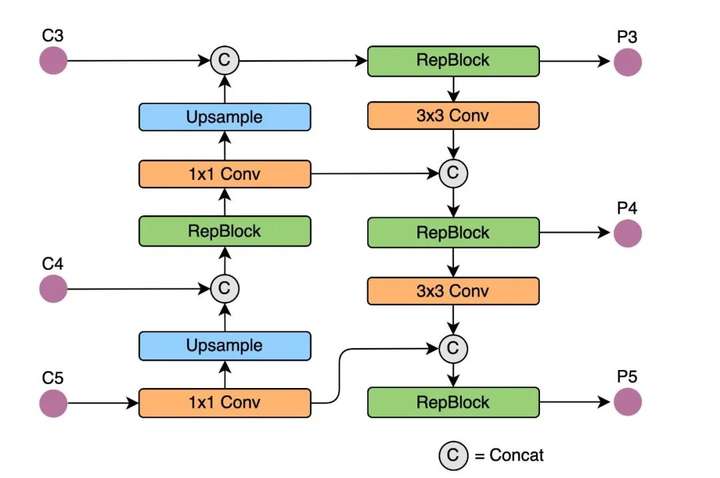
2、Rep PAN
Rep-PAN 基于 PAN 拓扑方式,用 RepBlock 替换了 YOLOv5 中使用的 CSP-Block,同时对整体 Neck 中的算子进行了调整。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
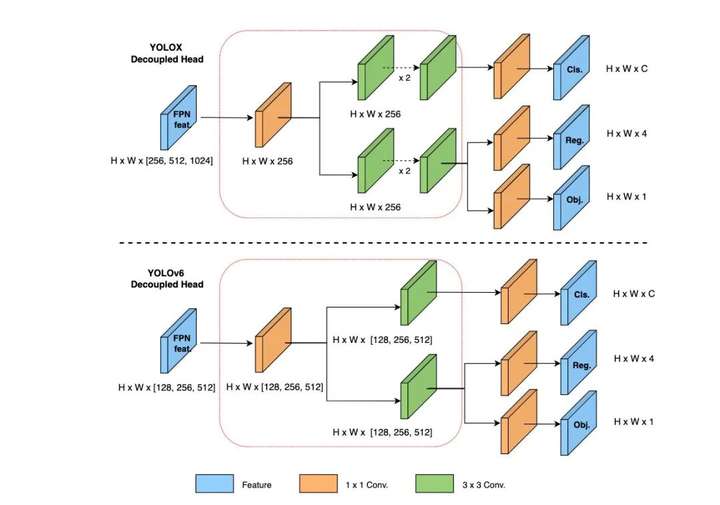
3、Decoupled Head
YOLOv6 采用了解耦检测头(Decoupled Head)结构,并对其进行了精简设计。
原始 YOLOv5 的检测头是通过分类和回归分支融合共享的方式来实现的,而 YOLOX 的检测头则是将分类和回归分支进行解耦,同时新增了两个额外的 3x3 的卷积层,虽然提升了检测精度,但一定程度上增加了网络延时。
YOLOv6对解耦头进行了精简设计,同时综合考虑到相关算子表征能力和硬件上计算开销这两者的平衡,采用 Hybrid Channels 策略重新设计了一个更高效的解耦头结构,在维持精度的同时降低了延时,缓解了解耦头中 3x3 卷积带来的额外延时开销。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
4、anchor-free
采用Anchor-free 无锚范式,也就是 box regression 分支是预测 anchor point 到 bbox 的四个边的距离。
YOLOv6 采用了更简洁的 Anchor-free 检测方法。由于 Anchor-based检测器需要在训练之前进行聚类分析以确定最佳 Anchor 集合,这会一定程度提高检测器的复杂度;
同时,在一些边缘端的应用中,需要在硬件之间搬运大量检测结果的步骤,也会带来额外的延时。
而 Anchor-free 无锚范式因其泛化能力强,解码逻辑更简单,在近几年中应用比较广泛。
添加图片注释,不超过 140 字(可选)
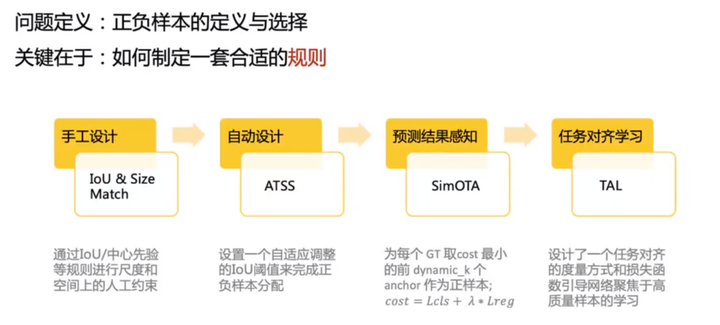
5、标签分配
为了获得更多高质量的正样本,YOLOv6 引入了 SimOTA 算法动态分配正样本,进一步提高检测精度。
YOLOv5 的标签分配策略是基于 Shape 匹配,并通过跨网格匹配策略增加正样本数量,从而使得网络快速收敛,但是该方法属于静态分配方法,并不会随着网络训练的过程而调整。
近年来,也出现不少基于动态标签分配的方法,此类方法会根据训练过程中的网络输出来分配正样本,从而可以产生更多高质量的正样本,继而又促进网络的正向优化。
例如,OTA通过将样本匹配建模成最佳传输问题,求得全局信息下的最佳样本匹配策略以提升精度,但 OTA 由于使用了Sinkhorn-Knopp 算法导致训练时间加长,而 SimOTA算法使用 Top-K 近似策略来得到样本最佳匹配,大大加快了训练速度。
故 YOLOv6 采用了SimOTA 动态分配策略,并结合无锚范式,在 nano 尺寸模型上平均检测精度提升 1.3% AP。
SimOTA定义的计算公式如下:
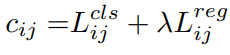
编辑
添加图片注释,不超过 140 字(可选)
对于每一个预测框,分别计算其与真实框的IOU和类别损失,然后加权得到总体损失。然后将各个框和真实框的iou排序,将所有框的iou相加取整,得到正样本的类别个数。 比如,下图中,取整后的结果为2,那就选取前两个作为正样本。
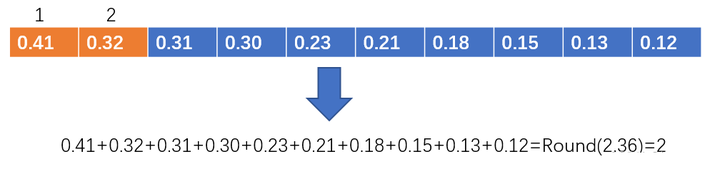
编辑切换为居中
添加图片注释,不超过 140 字(可选)
不同的 label assignment 方法的效果对比,实验基于 YOLOv6-N:
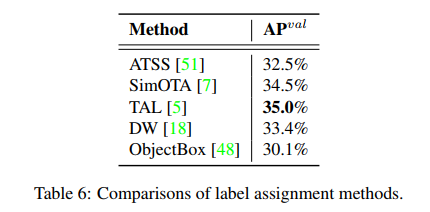
编辑
添加图片注释,不超过 140 字(可选)
Task alignment learning 任务对齐学习(TAL)首次在TOOD 中提出,其中设计了一个统一的分类分数和预测框质量的统一度量。用此度量替换IoU以分配对象标签。
在一定程度上,缓解了任务(分类和预测框回归)的错位问题。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
6、VariFocal Loss

编辑切换为居中
添加图片注释,不超过 140 字(可选)
YOLOv6选择VariFocal Loss作为分类损失。
Focal Loss改进了传统的交叉熵损失,解决了正负样本或硬易样本之间的类不平衡问题。
为了解决训练和推理之间质量估计和分类使用不一致的问题,Quality Focal Loss(QFL)进一步扩展了Focal Loss,并将分类评分和定位质量联合表示出来进行分类监督。
而VariFocal Loss (VFL)来源于Focal Loss,但它不对称地处理正样本和负样本。
通过考虑不同重要程度的正样本和负样本,它平衡了来自两个样本的学习信号。
Poly Loss将常用的分类损失分解为一系列加权多项式基。它在不同的任务和数据集上调整多项式系数,通过实验证明了其优于交叉熵损失和焦点损失。
YOLOv6最终采用了VFL 。
添加图片注释,不超过 140 字(可选)
7、SIOU
YOLOv6选择SIoU /GIoU 损失作为回归损失。
为了进一步提升回归精度,YOLOv6 采用了 SIoU边界框回归损失函数来监督网络的学习。
目标检测网络的训练一般需要至少定义两个损失函数:分类损失和边界框回归损失,而损失函数的定义往往对检测精度以及训练速度产生较大的影响。
近年来,常用的边界框回归损失包括IoU、GIoU、CIoU、DIoU loss等等,这些损失函数通过考虑预测框与目标框之前的重叠程度、中心点距离、纵横比等因素来衡量两者之间的差距,从而指导网络最小化损失以提升回归精度,但是这些方法都没有考虑到预测框与目标框之间方向的匹配性。
SIoU 损失函数通过引入了所需回归之间的向量角度,重新定义了距离损失,有效降低了回归的自由度,加快网络收敛,进一步提升了回归精度。
SIOU应用于YOLOv6-N和YOLOv6-T,而其他的则使用GIoU。
添加图片注释,不超过 140 字(可选)
8、Self-distillation
为了进一步提高模型的准确性,同时不引入太多额外的计算成本,YOLOv6采用经典的知识蒸馏技术来最小化教师模型和学生模型之间预测的KL散度。
通过限制教师模型是预先训练的学生模型,因此称之为自我蒸馏。
kl-散度通常用于度量数据分布之间的差异。然而,在目标检测中有两个子任务,其中只有分类任务可以直接利用基于kl-散度的知识精馏。
由于DFL损失,我们也可以在预测框回归上执行它。
知识蒸馏损失可以表述为:
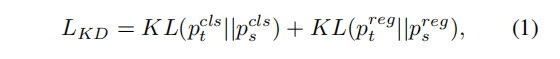
编辑
添加图片注释,不超过 140 字(可选)
其中
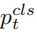
添加图片注释,不超过 140 字(可选)
和分别为教师模型和学生模型的类别预测,因此和为预测框回归预测。总体损失函数现在可以表述为:
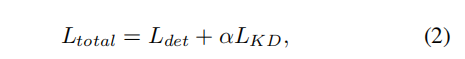
编辑
添加图片注释,不超过 140 字(可选)
其中,Ldet是用预测和标签计算出的检测损失。
引入超参数α来平衡两个损失。在训练的早期阶段,从教师模型那里得到的软标签更容易学习。随着训练的继续,学生模型的表现将与教师模型相匹配,这样硬标签将对学生更有帮助。
在此基础上,将余弦权值衰减应用于α,以动态调整来自教师的硬标签和软标签的信息。
为了解决在训练和推理过程中假量化器的不一致性问题,有必要在重新优化器上建立QAT。此外,在YOLOv6框架内采用了通道蒸馏(后来称为CW蒸馏),这也是一种自蒸馏的方法,其中教师网络是在fp32精度上的学生模型。
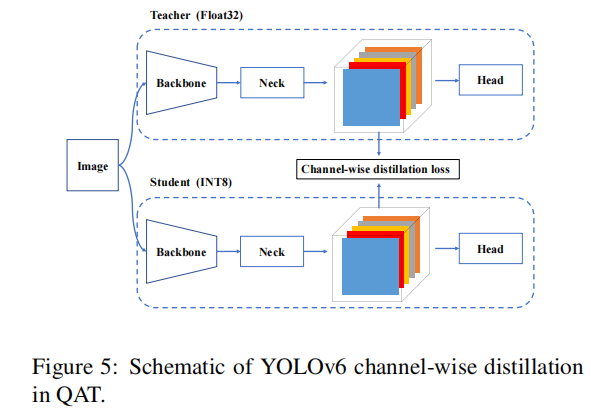
编辑
添加图片注释,不超过 140 字(可选)
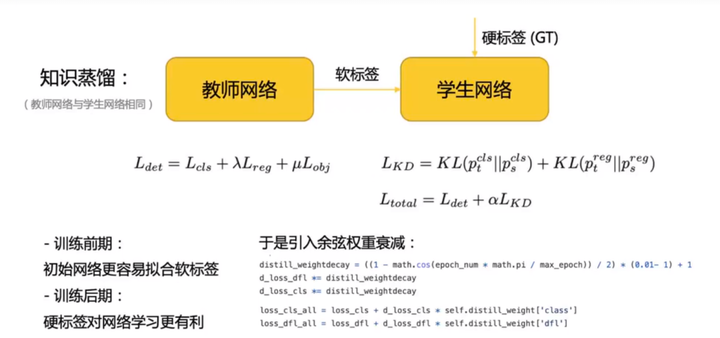
编辑切换为居中
添加图片注释,不超过 140 字(可选)
学生网络前期侧重学习软标签,后期学习硬标签。
添加图片注释,不超过 140 字(可选)
9、量化
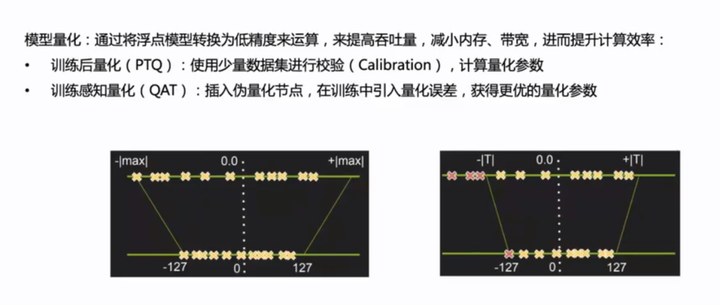
编辑切换为居中
添加图片注释,不超过 140 字(可选)
YOLov6的量化问题:
yolov6在结构中大量使用了重参数结构,导致数据分布过差,PTQ精度急剧下降。另外,重参数化结构网络无法直接使用QAT进行微调提升量化性能。
因为Deploy部署的模型无BN,不利于训练;Train模式进行QAT之后无法进行分支融合。
YOLOv6又是怎么做的呢?
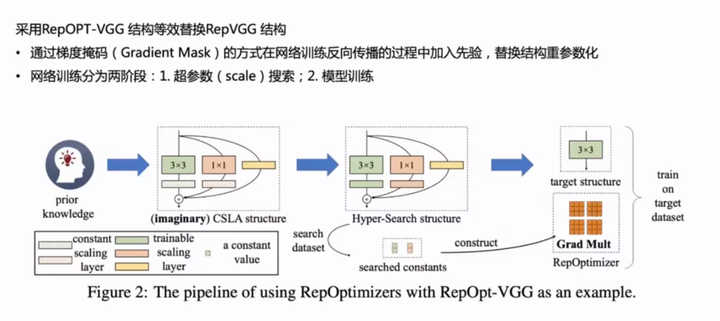
一、RepOpt-VGG 网络+梯度重参数化
思路一:RepVGG推理的时候由于速度的要求采用单路网络,训练的时候能否将推理模型的单路网络训练的效果拔高呢?(Deploy部署的模型无BN,仅仅是不利于训练,还是能训练,能否从这里进行改善。看起来可行。)
YOLOv6用了RepOpt-VGG 网络,这个工作与 RepVGG 相当于是两个不同的改进方向,一个是单网络变多分支来提高训练效果,另一个则是还是单网络通过训练手段提高训练效果。即:
RepVGG + 常规的优化器=VGG + RepOptimizer。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑切换为居中
添加图片注释,不超过 140 字(可选)
RepOPT结果改善了数据分布,有效提升了PTQ量化精度。
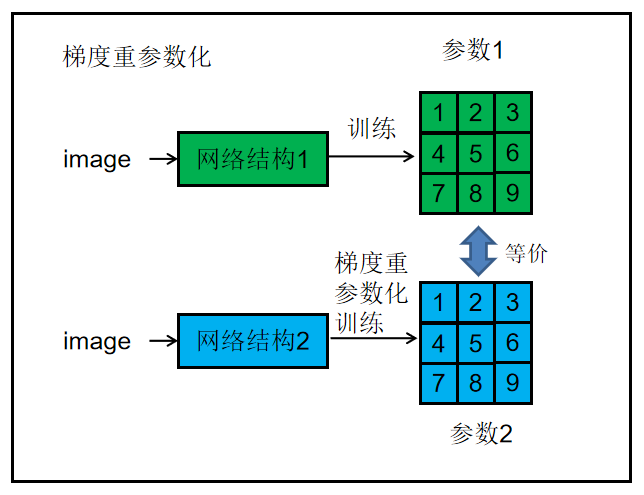
梯度重参数化。
将先验信息用于修改梯度数值,称为梯度重参数化,对应的优化器称为RepOptimizer。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
RepOpt 步骤:
步骤1:将架构的先验知识转移到你的优化器中。
步骤2:通过超搜索获得超参数。
步骤3:使用 RepOpt 进行训练。
二、PTQ-敏感度分析与部分量化
找到敏感的层,直接跳过。
如何寻找?
四种方法:mAP、MSE、SNR、Cosine
进行各层敏感性排序,进行逐层量化误差分析,查找最敏感的层进行跳过,实现部分量化。
三、QAT-量化节点插入
RepOPT的train/deploy模型结构一致,天然适合于QAT方法的使用。
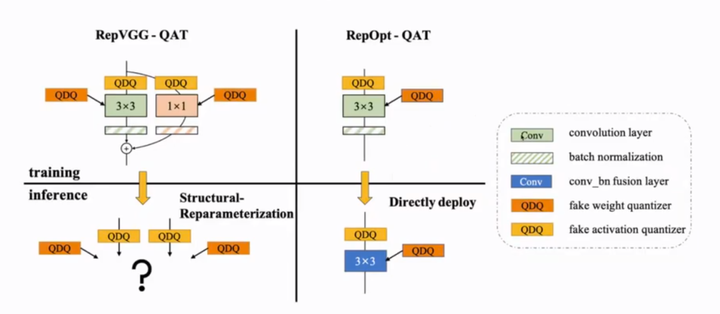
编辑切换为居中
添加图片注释,不超过 140 字(可选)
四、CWD自蒸馏
FP32模型为teacher,int8模型为student。
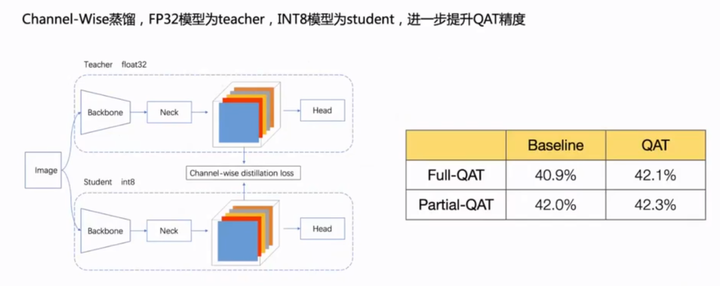
编辑切换为居中
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
10、总结
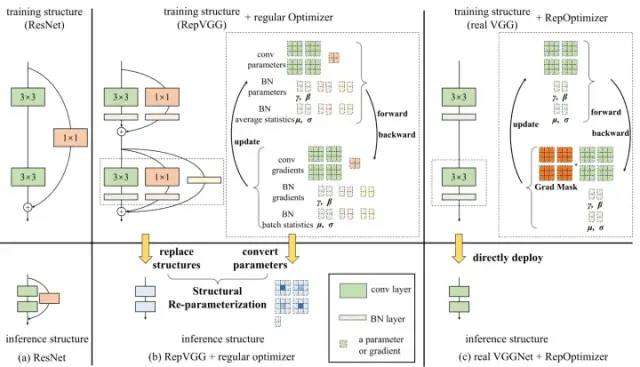
缘起:VGG中3*3的卷积结构,可以有效利用计算密集型硬件计算能力(比如 GPU),同时也可获得 GPU/CPU 上已经高度优化的 NVIDIA cuDNN 和 Intel MKL 编译框架的帮助。基于硬件友好的考虑,从模型推理出发,YOLOv6采用单路网络推理。
问题1:然而,单路网络训练的效果不佳。
解决1:结合resnet的想法,扩展为RepVGG的多分支结构用于训练。
问题2:多分支网络训练的参数无法直接应用到单路网络中进行推理,且多分支网络推理效果低,速度慢。
解决2:将训练模型和推理模型用结构重参数化方法结合起来,使得RepVGG多分支网络训练的参数可用于单路网络进行推理。
问题3:然而结构重参数化的网络无法进行量化,准确的说量化后无法进行分支融合,也就无法应用于单路推理模型。
解决3:因将训练的网络又从新改为单路,回到了起点。
网络的参数由网络结构获得,若能找到网络和参数的联系,类似结构重参数化一样的转化,岂不是可以从简单的网络得到复杂的参数?
RepOpt-VGG就是以单路网络为出发点,进行梯度重参数化来达到RepVGG网络的训练效果。
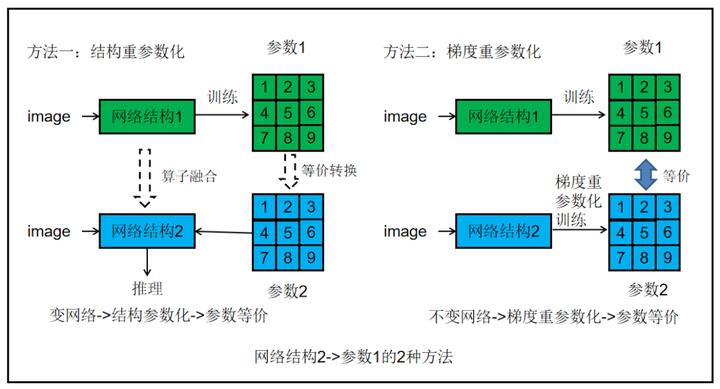
编辑切换为居中
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————
—————————————————————
公众号《AI大道理》征稿函mp.weixin.qq.com/s?__biz=MzU5NTg2MzIxMw==&mid=2247489802&idx=1&sn=228c18ad3a11e731e8f325821c184a82&chksm=fe6a2ac8c91da3dec311bcde280ad7ee760c0c3e08795604e0f221ff23c89c43a86c6355390f&scene=21#wechat_redirect
|
留言吧mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=77&appmsgid=100008353&isMul=1&replaceScene=0&isSend=0&isFreePublish=0&token=2141733260&lang=zh_CN
最新文章
- Json解析工具Jackson(简单应用)
- MVC的理解
- BZOJ3421 : Poi2013 Walk
- sizeof()用法汇总【转载】
- Python学习三---序列、列表、元组
- App接口中json方式封装通信接口
- DP:炮兵阵地问题(POJ 1185)
- BZOJ3122 随机数生成器
- ExtJS4.2学习(17)表单基本输入控件Ext.form.Field(转)
- URLConnection的连接、超时、关闭用法总结
- UML_交互图
- JavaScript 鸭子模型
- Eclipse使用技巧总结(三)
- NAVICAT 拒绝链接的问题
- LeetCode之“散列表”:Contains Duplicate && Contains Duplicate II
- v-charts修改点击图例事件,legendselectchanged
- Mybatis的学习1
- NO.9: 令operator=返回一个reference to *this
- android源码 键盘消息处理机制
- Vue + Bootstrap 制作炫酷个人简历(一)