【Spark】Day02:Spark-Core:RDD概述、RDD编程(转换算子、Action)、序列化、依赖关系、持久化、数据读取保存、累加器、广播变量、top10、转化率
总结:https://www.cnblogs.com/qingyunzong/p/8899715.html
一、RDD概述
1、引入:IO流
按行、按字节、字节缓冲
调用read方法读取流,均为惰性加载
2、RDD介绍
RDD:弹性分布数据集
只有调用collect才会执行
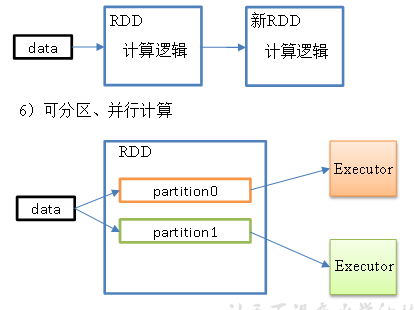
3、特性
分区(是并行计算的粒度)、计算逻辑(分区计算函数)、依赖关系(RDD流水线的转换)
二、RDD编程
1、编程模型
只有遇到action,才会执行RDD计算(即延迟计算)
wordcount
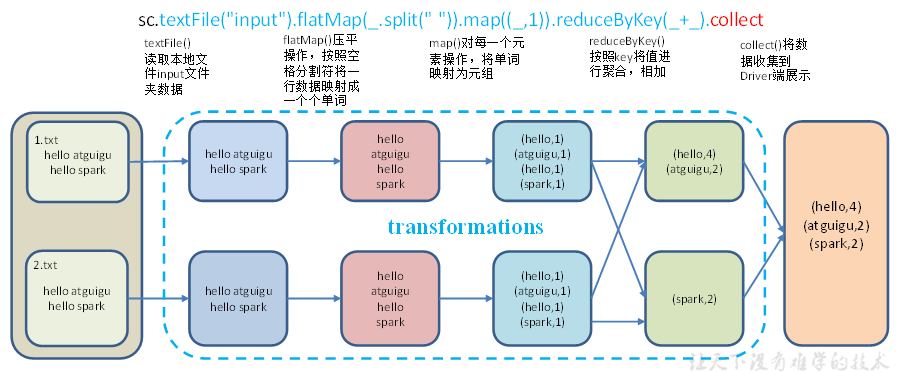
2、RDD的创建
Live Templates设置idea快捷键
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]") //2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf) //4.关闭连接
sc.stop()
三种方式:从集合中创建RDD、从外部存储创建RDD、从其他RDD创建
集合中创建:parallelize和makeRDD
外部存储系统的数据集创建:textFile,如本地,或hdfs即hdfs://hadoop102:9000/input
其他RDD创建:
3、分区规则:默认按照CPU核数进行分区
自定义分区方式:
从集合中创建:sc.makeRDD(Array(1, 2, 3, 4), 3)
从文件中读取后创建:val rdd: RDD[String] = sc.textFile("input/3.txt",3)
4、Transformation转换算子
RDD分为:Value类型、双Value类型和Key-Value类型
(1)Value类型:
map映射(一次处理一个元素)
mapPartitions()以分区为单位执行(一次处理一个分区)
mapPartitionsWithIndexindex, item()处理完后带分区号,形成元组
flatMap()压平(多个集合数据放入一个大的集合)
glom()分区转换数组(将一个分区的数据变为一个数组)【例如求最大值:rdd.glom.map(_.max)】
groupBy()分组(参数是分组条件,如_%2,或groupBy(t=>t._1))
filter()过滤(参数是过滤条件)
sample()采样(按概率传参,选择放回或不放回抽样)
distinct(n)去重,并设置去重操作的分区数(去重后修改分区个数)
coalesce(n)重新设置分区(可选是否使用shuffle),shuffle即数据打乱重组【库尔莱sei】
repartition()重新分区(使用shuffle),实际上调用的是coalesce
sortBy()排序,参数为排序规则,修改第二个参数为false则为降序,缺省为升序
pipe("/opt/module/spark/pipe.sh")调用脚本,将脚本作用于RDD上
#!/bin/sh
echo "Start"
while read LINE; do
echo ">>>"${LINE}
done scala> rdd.pipe("/opt/module/spark/pipe.sh").collect()
res18: Array[String] = Array(Start, >>>hi, >>>Hello, >>>how, >>>are, >>>you)
(2)双Value类型交互【两个RDD的操作】
A.union(B)并集
A.subtract (B)差集
A.intersection(B)交集
zip()拉链,两个RDD组合到一起形成一个(k,v)RDD,一个作为k,一个作为v
partitionBy(分区器)按照K重新分区,内部可以传递分区器,如HashPartitioner或自定义分区器
reduceByKey(参数)按照K聚合V,如相同k的进行相加,可以写成(x,y) => x+y
groupByKey()按照K重新分组,相同k的值进行分组
aggregateByKey()多个参数,分别按照K处理分区内和分区间的逻辑,如aggregateByKey(0)(math.max(_, _), _ + _)为取出每个分区相同key对应值的最大值,然后相加
foldByKey()分区内和分区间相同的aggregateByKey()
combineByKey()转换结构后分区内和分区间操作
sortByKey(T/F)按照K进行排序
mapValues()只对V进行操作,如参数传递_ + "|||"
join()连接,相同key对应的多个value关联,将value变成集合,如 rdd.join(rdd1).
cogroup() 类似全连接,在同一个RDD中对key聚合,同一k的多个v分别位于不同的集合
(3)案例实操(广告点击Top3)

object Demo_top3 {
def main(args: Array[String]): Unit = {
//1. 初始化Spark配置信息并建立与Spark的连接
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Test")
val sc = new SparkContext(sparkConf)
//2. 读取日志文件,获取原始数据
val dataRDD: RDD[String] = sc.textFile("input/agent.log")
//3. 将原始数据进行结构转换string =>(prv-adv,1)
val prvAndAdvToOneRDD: RDD[(String, Int)] = dataRDD.map {
line => {
val datas: Array[String] = line.split(" ")
(datas(1) + "-" + datas(4), 1)
}
}
//4. 将转换结构后的数据进行聚合统计(prv-adv,1)=>(prv-adv,sum)
val prvAndAdvToSumRDD: RDD[(String, Int)] = prvAndAdvToOneRDD.reduceByKey(_ + _)
//5. 将统计的结果进行结构的转换(prv-adv,sum)=>(prv,(adv,sum))
val prvToAdvAndSumRDD: RDD[(String, (String, Int))] = prvAndAdvToSumRDD.map {
case (prvAndAdv, sum) => {
val ks: Array[String] = prvAndAdv.split("-")
(ks(0), (ks(1), sum))
}
}
//6. 根据省份对数据进行分组:(prv,(adv,sum)) => (prv, Iterator[(adv,sum)])
val groupRDD: RDD[(String, Iterable[(String, Int)])] = prvToAdvAndSumRDD.groupByKey()
//7. 对相同省份中的广告进行排序(降序),取前三名
val mapValuesRDD: RDD[(String, List[(String, Int)])] = groupRDD.mapValues {
datas => {
datas.toList.sortWith(
(left, right) => {
left._2 > right._2
}
).take(3)
}
}
//8. 将结果打印
mapValuesRDD.collect().foreach(println)
//9.关闭与spark的连接
sc.stop()
}
}
5、Action行动算子
reduce()聚合,例如reduce(_+_)
collect()以数组形式返回,
count()返回元素个数
first()返回第一个元素
take(n):返回前n个元素构成的数组,如val takeResult: Array[Int] = rdd.take(2)
takeOrdered(n)返回该RDD排序后前n个元素组成的数组
aggregate(初始值)(分区内逻辑,分区间的逻辑),例如val result: Int = rdd.aggregate(10)(_ + _, _ + _)
fold()折叠操作,即分区内和分区间的逻辑相同,是aggregate的简化,例如元素相加可以写成rdd.fold(0)(_+_)
countByKey()统计每种key的个数,返回map,如val result: collection.Map[Int, Long] = rdd.countByKey()
save相关的算子:saveAsTextFile、saveAsSequenceFile、saveAsObjectFile
foreach()遍历RDD的每个元素
6、RDD序列化【用于driver和executor之间进行数据传递】
初始化工作是在Driver端进行的,而实际运行程序是在Executor端进行,就需要进行序列化
(1)解决方案
类继承scala.Serializable,将类变量query赋值给局部变量
把类变成样例类case class,样例类默认是序列化的,能够被优化以用于模式匹配
(2)Kryo序列化框架
即使使用kryo序列化,也要继承Serializable接口
方式
val conf: SparkConf = new SparkConf()
.setAppName("SerDemo")
.setMaster("local[*]")
// 替换默认的序列化机制
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册需要使用 kryo 序列化的自定义类
.registerKryoClasses(Array(classOf[Searcher])) val sc = new SparkContext(conf)
7、RDD依赖关系
将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区,可以根据这些信息来重新运算和恢复丢失的数据分区
查看血缘关系println(fileRDD.toDebugString)
查看依赖关系:fileRDD.dependencies,包含一对一、shuffle
窄依赖:个父RDD的Partition最多被子RDD的一个Partition使用
宽依赖:一个RDD可能会到多个RDD,会引起shuffle
job调度:程序自己是运行在驱动节点, 然后发送指令到执行器节点。启动一个 SparkContext 的时候, 就开启了一个 Spark 应用,针对每个action,Spark 调度器就创建一个执行图
任务划分:中间分为:Application、Job、Stage和Task(最后一个RDD的分区个数),每一层都是1对n的关系,可以通过http://localhost:4040/jobs/查看
8、RDD持久化
RDD Cache缓存:wordToOneRdd.cache(),将前面的计算结果缓存
RDD CheckPoint检查点,将RDD中间结果写入磁盘
wordToOneRdd.checkpoint(),如果要保存到hdfs,需要提前创建路径"hdfs://hadoop102:9000/checkpoint"
三、数据读取与保存
1、文件类数据读取与保存
sc.textFile("input/user.json")
sc.sequenceFile[Int,Int]("output")
text json sequence object
saveAsTextFile
saveAsSequenceFile
2、文件系统类数据读取与保存
HDFS MySQL
四、累加器
1、系统累加器
val sum1: LongAccumulator = sc.longAccumulator("sum1")
2、自定义累加器
创建、注册
//3.1 创建累加器
val accumulator1: MyAccumulator = new MyAccumulator() //3.2 注册累加器
sc.register(accumulator1,"wordcount")
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {
五、广播变量:分布式共享只读变量
val broadcastList: Broadcast[List[(String, Int)]] = sc.broadcast(list)
向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用
六、SparkCore项目实战
1、数据准备
用户行为数据:搜索、点击、下单和支付
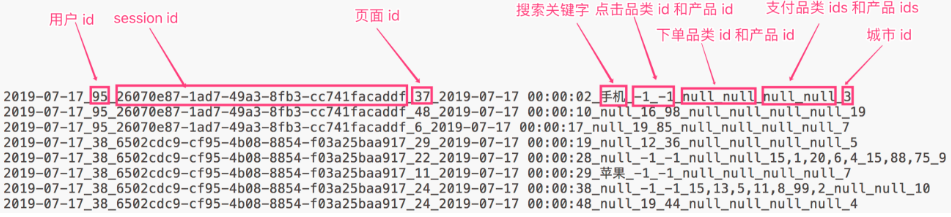
2、需求1:Top10热门品类
综合排名=点击数*20%+下单数*30%+支付数*50%
定义累加器
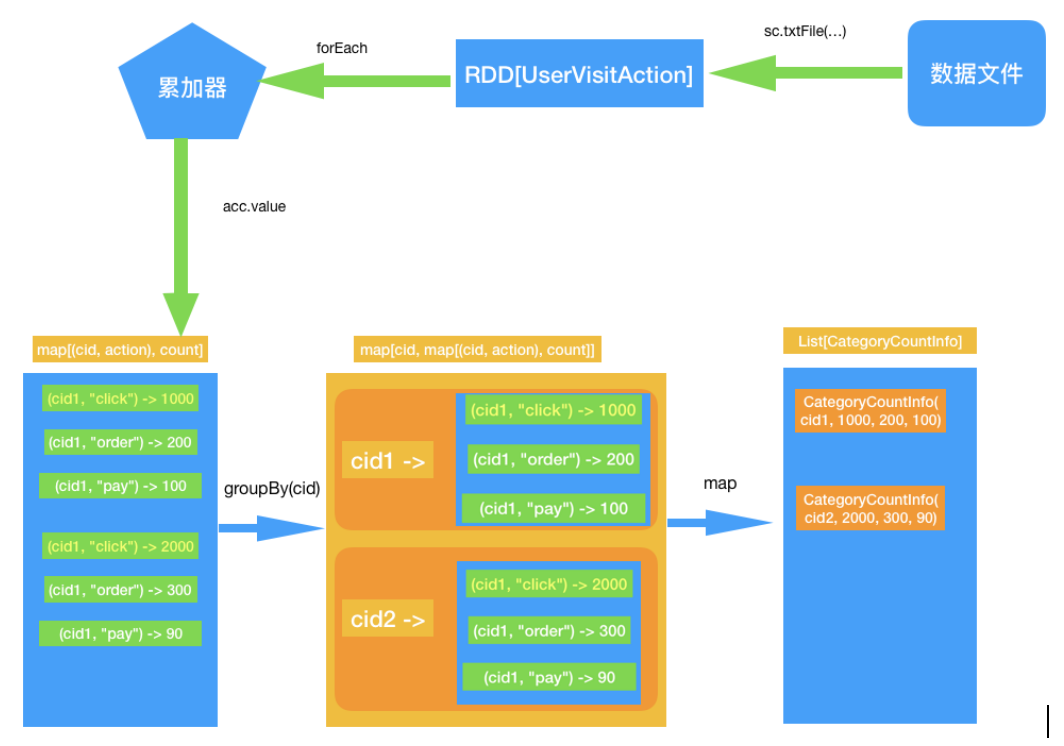
3、需求2:排名前10的品类,分别获取每个品类点击次数排名前10的sessionId
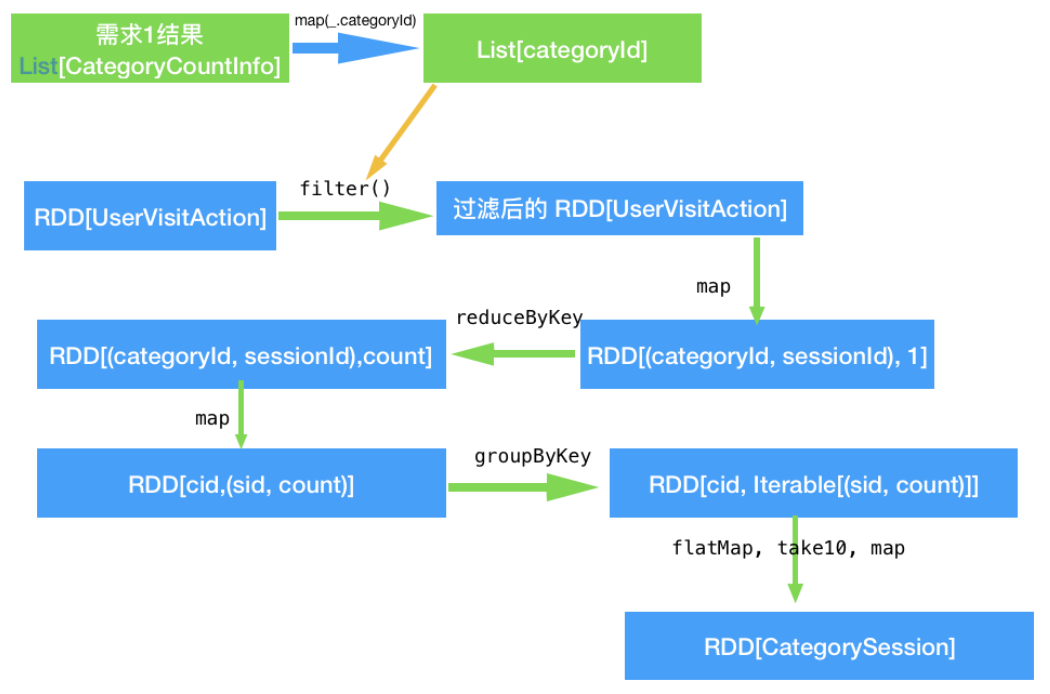
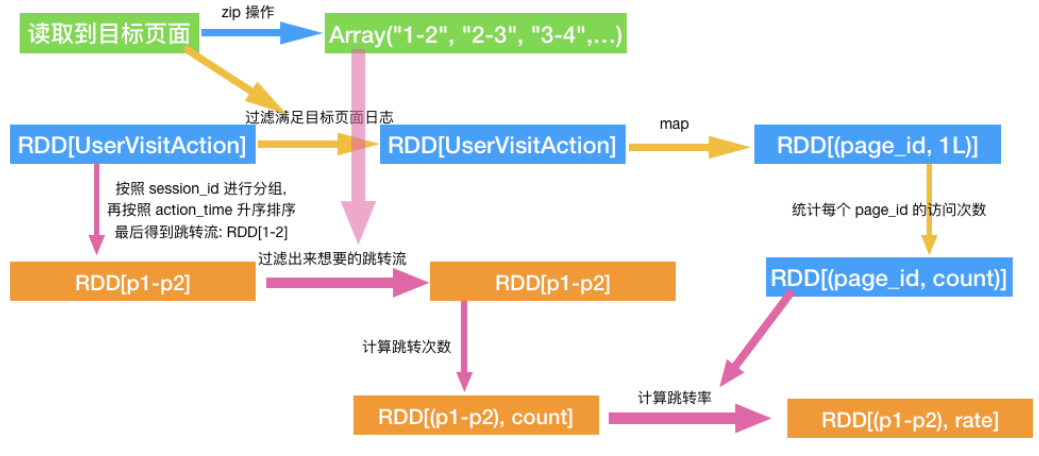
4、需求3:页面单跳转化率统计
访问了页面 3 又紧接着访问了页面 5 的
最新文章
- [moka同学笔记]php 获取时间(今天,昨天,三天内,本周,上周,本月,三年内,半年内,一年内,三年内)
- SAM/BAM文件处理
- https://developers.google.com/maps/documentation/javascript/examples/places-autocomplete-addressform
- 分析一个C语言程序生成的汇编代码-《Linux内核分析》Week1作业
- [转]ASP.NET 2.0中GridView无限层复杂表头的实现
- Java for LeetCode 198 House Robber
- css修改,类似elememt.style样式修改
- javascript 倒计时获取验证码
- 在asp.net中如何自己编写highcharts图表导出到自己的服务器上来
- 【转】关于oracle with as用法
- 浙大PTA - - File Transfer
- PHP面向对象(OOP):克隆对象__clone()方法
- IE浏览器兼容性问题解决方法
- mybatis分页+springmvc+jsp+maven使用步骤
- Knockoutjs 响应式计算研究
- windows安装mysql5.7.xx解压版
- 2159 ACM 杭电 杀怪 二维费用的背包+完全背包问题
- virtualbox - 2台虚拟机之间通过ssh互访
- mysqldump命令的安装
- Iscloc用法笔记