pyspark 结构化数据开发实例
2024-09-08 17:26:53
什么是SPARK?
1. 先进的大数据分布式编程和计算框架
2. 替换Hadoop 中的MR计算引擎。
3. 内存分布式计算:运行数度快
4. 可以使用不同的语言编程(java,scala,r 和python)
5. 可以从不同的数据源获取数据,可以从HDFS,Cassandea,HBase等等,同时可以支持很多的文件格式:text Seq AVRO Parquet
6. 实现不同的大数据功能:Spark Core,Sparc SQL等等
PySpark 是 Spark 为 Python 开发者提供的 API ,位于 $SPARK_HOME/bin 目录,其依赖于 Py4J。随着Spark 2.1.0发布的 Py4J位于 $SPARK_HOME/python/lib 目录,对应的版本是 0.10.4。
本文是基于pyspark 的进行数据ETL 和统计分析的代码示例,数据源来源于MySQL。 本文使用较小的数据量作为实例,当然同样适用于海量数据的情况。 运行本文代码的前提是
在Windows11 上搭建 pyspark 的开发环境。
我的环境:
1,jdk 1.8
2, hadoop 3.3.4
3, spark 3.3.1
4,python 3.9
代码设计要点:
1, 使用pyspark 读取 mysql 表数据。
2,使用rdd api 对 结构化数据做简单ETL,设置了简单的清洗规则。
1,cityCode 字段非空,全部为数字, 位数为9位, 前3位必须为”001“ 。
3, 使用3种抽象层级的API (RDD API , Dataframe api, SQL api )对数据进行分析计算 ,比较3种API的使用区别
4,包括了一些 rdd, Datafram 相互转换, ROW类型的使用
# Imports
from pyspark.sql import SparkSession # Create SparkSession
spark = SparkSession.builder \
.appName('SparkByExamples.com') \
.config("spark.jars", "mysql-connector-java-5.1.28.jar") \
.getOrCreate() # Read from MySQL Table
table_df = spark.read \
.format("jdbc") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("url", "jdbc:mysql://134.**.**.**:9200/hesc_stm_xhm") \
.option("dbtable", "temp_user_grid") \
.option("user", "root") \
.option("password", "****") \
.load() # check read accessable
# print( table_df.count()) # 总行数 # etl 使用rdd 算子
rdd = table_df.rdd
# print(rdd.first()) # cityCode
# print(rdd.filter(lambda r: r(5) == None).count()) # gridCode为空的行数 rdd1 = rdd.filter(lambda r: Row.asDict(r).get("cityCode") != None).filter(
lambda r: len(Row.asDict(r).get("cityCode")) == 9) # print(rdd.map(lambda r: Row.asDict(r).get("cityCode")).take(5)) # ROW类型的元素读取 使用 r(19)读取列有问题 def checkCityCode(str):
# 判断字符串的格式,前3位为001,而且全为数字
if (str[:3] == '001') and str.isnumeric():
return True
else:
return False rdd2 = rdd1.filter(lambda r: checkCityCode(Row.asDict(r).get("cityCode")))
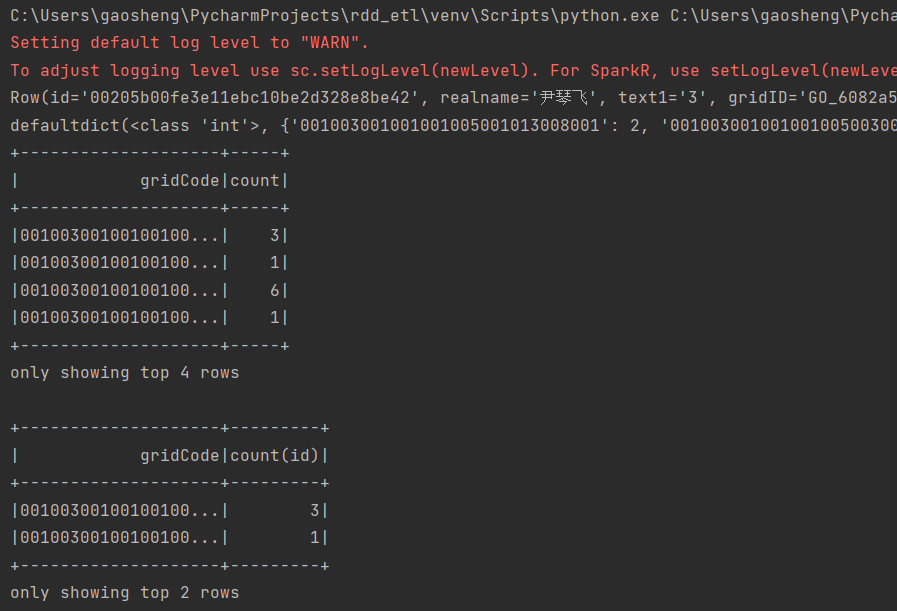
print(rdd2.first()) # 数据分析 使用 rdd df算子 sql 三种算子 ; 统计不同网格的人员数量。
# rdd operator map = rdd2.map(lambda r: (Row.asDict(r).get("gridCode"), Row.asDict(r).get("id"))).countByKey()
print(map) # 查询python rdd api # df/ds operator dataset 1.6之后加入, 整合了RDD 的强类型便于使用lambda函数以及 sqpark sql 优化引擎
# python 没有dataset 类型。java scala 可以。 dataframe是 dataset 的 一种。 dataframe 适用python . df = rdd2.toDF()
df1 = df.groupBy('gridCode').count() # dataframe 特定编程语言 对结构化数据操作, 也称 无类型dataset算子
df1.show(4) # sql operator
df.createOrReplaceTempView('temp_user_grip')
df2 = spark.sql("select gridCode, count(id) from temp_user_grip group by gridCode")
df2.show(2) spark.stop()
运行输出:
最新文章
- java 日期格式
- operator
- js call
- C#中使用UDP通信
- Android数据库的使用
- HDU1054Strategic Game(最小顶点覆盖数)
- js跨域问题新方案
- hadoop多文件输出
- Android 模块化编程之引用本地的aar
- 学习PS必须弄懂的专业术语
- 屏幕编程 F4的帮组用法
- json与javabean之间的转化
- CentOs查看某个字符串在某个目录下的行数
- Spark2.0学习(三)--------核心API
- Python-递归初识-50
- poj3155 最大密度子图
- zabbix_agent添加到系统服务启动(八)
- bootstrap 文本对齐风格
- 2017最新整理移动Web开发遇到的坑
- Java中的构造器与垃圾回收