超详细的Ribbon源码解析
Ribbon简介
什么是Ribbon?
Ribbon是springcloud下的客户端负载均衡器,消费者在通过服务别名调用服务时,需要通过Ribbon做负载均衡获取实际的服务调用地址,然后通过httpclient的方式进行本地RPC远程调用。
Ribbon原理
Ribbon负载均衡算法主要是轮询算法,分为以下几步:
- 根据服务别名,从eureka获取服务提供者的列表
- 将列表缓存到本地
- 根据具体策略获取服务提供者
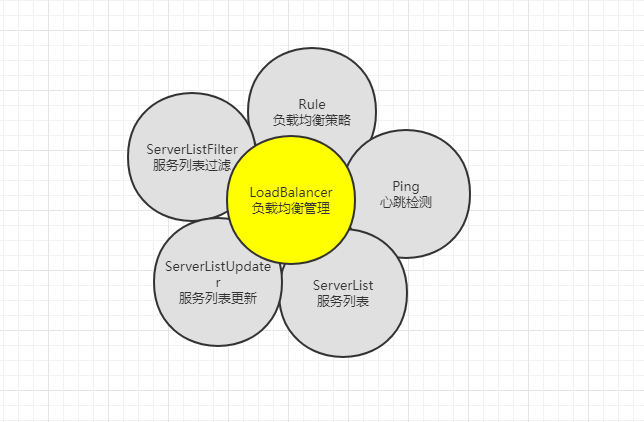
Ribbon的核心是负载均衡管理,另还有5个大功能点。如下图:
源码分析
事前准备
先搭建一个SpringCloud的项目,也可以从我的github上下载。地址:https://github.com/mmcLine/spring-cloud-study
拷贝以下代码
@Configuration
public class RestTemplateConfiguration {
@Bean
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
@Autowired
private RestTemplate restTemplate;
@GetMapping("/testRibbon/{id}")
public User getTodayStatistic(@PathVariable("id") Integer id){
String url ="http://STUDY-USER/user/getUserById?id="+id;
return restTemplate.getForObject(url, User.class);
}
代码都准备好了,可以开始分析了。
- 执行调用
为什么这么就能调用到服务提供者的方法?
打断点,可以看到restTemplate里有两个拦截器,根据名字可以推断RetryLoadBalancerInterceptor是关键。
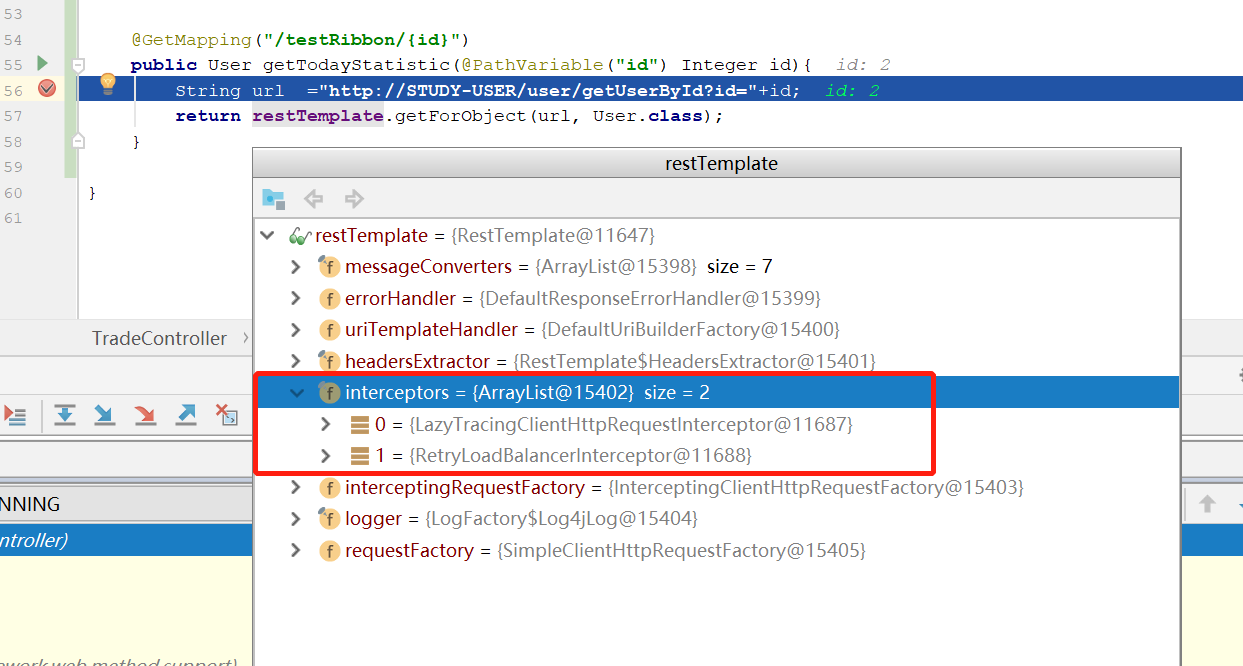
跟踪到RetryLoadBalancerInterceptor类
@Override
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body,
final ClientHttpRequestExecution execution) throws IOException {
final URI originalUri = request.getURI();
//获取到service的name
final String serviceName = originalUri.getHost();
Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);
//根据serviceName和LoadBalancerClient,LoadBalancedRetryPolicy里面包含了RibbonLoadBalancerContext和ServiceInstanceChooser
final LoadBalancedRetryPolicy retryPolicy = lbRetryFactory.createRetryPolicy(serviceName,
loadBalancer);
RetryTemplate template = createRetryTemplate(serviceName, request, retryPolicy);
//执行方法会进入到doExecute方法
return template.execute(context -> {
ServiceInstance serviceInstance = null;
if (context instanceof LoadBalancedRetryContext) {
LoadBalancedRetryContext lbContext = (LoadBalancedRetryContext) context;
serviceInstance = lbContext.getServiceInstance();
}
if (serviceInstance == null) {
serviceInstance = loadBalancer.choose(serviceName);
}
ClientHttpResponse response = RetryLoadBalancerInterceptor.this.loadBalancer.execute(
serviceName, serviceInstance,
requestFactory.createRequest(request, body, execution));
int statusCode = response.getRawStatusCode();
if (retryPolicy != null && retryPolicy.retryableStatusCode(statusCode)) {
byte[] bodyCopy = StreamUtils.copyToByteArray(response.getBody());
response.close();
throw new ClientHttpResponseStatusCodeException(serviceName, response, bodyCopy);
}
return response;
}, new LoadBalancedRecoveryCallback<ClientHttpResponse, ClientHttpResponse>() {
//This is a special case, where both parameters to LoadBalancedRecoveryCallback are
//the same. In most cases they would be different.
@Override
protected ClientHttpResponse createResponse(ClientHttpResponse response, URI uri) {
return response;
}
});
}
doExecute方法:
protected <T, E extends Throwable> T doExecute(RetryCallback<T, E> retryCallback,
RecoveryCallback<T> recoveryCallback, RetryState state)
throws E, ExhaustedRetryException {
//省略部分代码
/*
* We allow the whole loop to be skipped if the policy or context already
* forbid the first try. This is used in the case of external retry to allow a
* recovery in handleRetryExhausted without the callback processing (which
* would throw an exception).
*/
//执行逻辑的关键方法
while (canRetry(retryPolicy, context) && !context.isExhaustedOnly()) {
}
继续跟踪canRetry方法
@Override
public boolean canRetry(RetryContext context) {
LoadBalancedRetryContext lbContext = (LoadBalancedRetryContext)context;
if(lbContext.getRetryCount() == 0 && lbContext.getServiceInstance() == null) {
//We haven't even tried to make the request yet so return true so we do
//设置选中的服务提供者
lbContext.setServiceInstance(serviceInstanceChooser.choose(serviceName));
return true;
}
return policy.canRetryNextServer(lbContext);
}
我们跟踪serviceInstanceChooser.choose(serviceName)看看怎么通过serviceName选服务提供者的。
@Override
public ServiceInstance choose(String serviceId) {
//选择server
Server server = getServer(serviceId);
if (server == null) {
return null;
}
return new RibbonServer(serviceId, server, isSecure(server, serviceId),
serverIntrospector(serviceId).getMetadata(server));
}
跟踪getServer方法
protected Server getServer(ILoadBalancer loadBalancer) {
if (loadBalancer == null) {
return null;
}
//可以看出是loadBalancer在选择
return loadBalancer.chooseServer("default"); // TODO: better handling of key
}
继续深入
public Server chooseServer(Object key) {
if (counter == null) {
counter = createCounter();
}
//有一个调用次数在+1
counter.increment();
if (rule == null) {
return null;
} else {
try {
//委托给了IRule,所以Irule是负载均衡的关键,最后来总结
return rule.choose(key);
} catch (Exception e) {
logger.warn("LoadBalancer [{}]: Error choosing server for key {}", name, key, e);
return null;
}
}
}
查看Irule的实现
public Server choose(Object key) {
ILoadBalancer lb = getLoadBalancer();
//lb.getAllServers里面是所有的服务提供者列表
Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);
if (server.isPresent()) {
return server.get();
} else {
return null;
}
}
跟踪chooseRoundRobinAfterFiltering方法
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) {
//拿到筛选后的servers
List<Server> eligible = getEligibleServers(servers, loadBalancerKey);
if (eligible.size() == 0) {
return Optional.absent();
}
//incrementAndGetModulo方法拿到下标,然后根据list.get取到一个服务
return Optional.of(eligible.get(incrementAndGetModulo(eligible.size())));
}
至此就拿到了具体的服务提供者。
但是到这里还有个问题?
- 怎么根据服务名拿到server的?
有一个ServerList接口是用于拿到服务列表的。我们使用的loadBalancer(ZoneAwareLoadBalancer)的父类DynamicServerListLoadBalancer类的构造方法里,有一个restOfinit方法
public DynamicServerListLoadBalancer(IClientConfig clientConfig, IRule rule, IPing ping,
ServerList<T> serverList, ServerListFilter<T> filter,
ServerListUpdater serverListUpdater) {
super(clientConfig, rule, ping);
this.serverListImpl = serverList;
this.filter = filter;
this.serverListUpdater = serverListUpdater;
if (filter instanceof AbstractServerListFilter) {
((AbstractServerListFilter) filter).setLoadBalancerStats(getLoadBalancerStats());
}
restOfInit(clientConfig);
}
跟踪restOfInit方法
void restOfInit(IClientConfig clientConfig) {
boolean primeConnection = this.isEnablePrimingConnections();
// turn this off to avoid duplicated asynchronous priming done in BaseLoadBalancer.setServerList()
this.setEnablePrimingConnections(false);
enableAndInitLearnNewServersFeature();
//用于获取所有的serverList
updateListOfServers();
if (primeConnection && this.getPrimeConnections() != null) {
this.getPrimeConnections()
.primeConnections(getReachableServers());
}
this.setEnablePrimingConnections(primeConnection);
LOGGER.info("DynamicServerListLoadBalancer for client {} initialized: {}", clientConfig.getClientName(), this.toString());
}
继续跟踪updateListOfServers方法
public void updateListOfServers() {
List<T> servers = new ArrayList<T>();
if (serverListImpl != null) {
//查询serverList
servers = serverListImpl.getUpdatedListOfServers();
LOGGER.debug("List of Servers for {} obtained from Discovery client: {}",
getIdentifier(), servers);
if (filter != null) {
servers = filter.getFilteredListOfServers(servers);
LOGGER.debug("Filtered List of Servers for {} obtained from Discovery client: {}",
getIdentifier(), servers);
}
}
updateAllServerList(servers);
}
继续跟踪源码到obtainServersViaDiscovery方法,
private List<DiscoveryEnabledServer> obtainServersViaDiscovery() {
List<DiscoveryEnabledServer> serverList = new ArrayList<DiscoveryEnabledServer>();
//eurekaClientProvider.get()会去获取EurekaClient
if (eurekaClientProvider == null || eurekaClientProvider.get() == null) {
logger.warn("EurekaClient has not been initialized yet, returning an empty list");
return new ArrayList<DiscoveryEnabledServer>();
}
EurekaClient eurekaClient = eurekaClientProvider.get();
//vipAddresses就是serviceName
if (vipAddresses!=null){
for (String vipAddress : vipAddresses.split(",")) {
// if targetRegion is null, it will be interpreted as the same region of client
//此处获取到服务的信息
List<InstanceInfo> listOfInstanceInfo = eurekaClient.getInstancesByVipAddress(vipAddress, isSecure, targetRegion);
for (InstanceInfo ii : listOfInstanceInfo) {
if (ii.getStatus().equals(InstanceStatus.UP)) {
if(shouldUseOverridePort){
if(logger.isDebugEnabled()){
logger.debug("Overriding port on client name: " + clientName + " to " + overridePort);
}
// copy is necessary since the InstanceInfo builder just uses the original reference,
// and we don't want to corrupt the global eureka copy of the object which may be
// used by other clients in our system
InstanceInfo copy = new InstanceInfo(ii);
if(isSecure){
ii = new InstanceInfo.Builder(copy).setSecurePort(overridePort).build();
}else{
ii = new InstanceInfo.Builder(copy).setPort(overridePort).build();
}
}
DiscoveryEnabledServer des = new DiscoveryEnabledServer(ii, isSecure, shouldUseIpAddr);
des.setZone(DiscoveryClient.getZone(ii));
serverList.add(des);
}
}
if (serverList.size()>0 && prioritizeVipAddressBasedServers){
break; // if the current vipAddress has servers, we dont use subsequent vipAddress based servers
}
}
}
return serverList;
}
综合上面可以看出,最终是通过eurekaClient去拿到服务列表的。
那么如果服务列表发生变化怎么刷新呢?
是通过CacheRefreshThread在定时线程池里面执行,核心拉取方法是fetchRegistry
Iping
Iping是用于探测服务列表中的服务是否正常,如果不正常,则从eureka拉取服务列表并更新。
在BaseLoadBalancer里面有一个setupPingTask方法,启动定时任务,30秒一次定时向EurekaClient发送“ping”
public BaseLoadBalancer(String name, IRule rule, LoadBalancerStats stats,
IPing ping, IPingStrategy pingStrategy) {
logger.debug("LoadBalancer [{}]: initialized", name);
this.name = name;
this.ping = ping;
this.pingStrategy = pingStrategy;
setRule(rule);
setupPingTask();
lbStats = stats;
init();
}
Iping的具体逻辑在PingTask类里。
Irule总结:
Irule是负载均衡的规则:
我这里默认是使用的是ZoneAvoidanceRule,还有很多种策略:
- RandomRule: 随机
- RoundRobinRule: 轮询
- RetryRule: 先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试,获取可用的服务
- WeightedResponseTimeRule: 对RoundRobinRule的扩展,响应速度越快的实例选择权重越大,越容易被选择
- BestAvailableRule:会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务
- AvailabilityFilteringRule:先过滤掉故障实例,再选择并发较小的实例
- ZoneAvoidanceRule:默认规则,复合判断server所在区域的性能和server的可用性选择服务器
properties配置方式如下:
STUDY-USER是服务名
STUDY-USER.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RoundRobinRule
最新文章
- canvas调用scale或者drawImage图片操作后,锯齿感很明显的解决
- paper 130:MatLab分类器大全(svm,knn,随机森林等)
- EF架构~为BulkInsert引入SET IDENTITY_INSERT ON功能
- 在 Mac OS X 终端里使用 Solarized 配色方案
- Flask生成SECRET_KEY(密钥)的一种简单方法
- docker-1 初识docker
- bzoj3034: Heaven Cow与God Bull
- Unity中的C#规则
- JavaScript 隐式转换
- SQL Server 使用ROW_NUMBER()进行分页
- Mac下使用Brew搭建PHP(LNMP/LAMP)开发环境
- Android 开发TCP协议时,报错NetworkOnMainThreadException
- navicat连接mysql出现Client does not support authentication protocol requested by server解决方案
- MS SQL 全局临时表的删除
- javascript常用的操作
- Django 数据库的迁移
- (转)kafka实战教学
- Web端主流框架,jquery、angular、react、vue
- shortcut icon和icon代码的区别介绍
- linux学习记录.2.hello world.c