CUDA编程入门
CUDA是一个并行计算框架.用于计算加速.是nvidia家的产品.广泛地应用于现在的深度学习加速.
一句话描述就是:cuda帮助我们把运算从cpu放到gpu上做,gpu多线程同时处理运算,达到加速效果.
从一个简单例子说起:
#include <iostream>
#include <math.h>
// function to add the elements of two arrays
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20; // 1M elements
float *x = new float[N];
float *y = new float[N];
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the CPU
add(N, x, y);
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
delete [] x;
delete [] y;
return 0;
}
这段代码很简单,对两个数组对应位置元素相加.数组很大,有100万个元素.
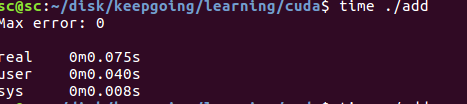
代码运行时间在0.075s.
改写代码使之运行于gpu
gpu上能够运算的函数,在cuda中我们称之为kernel.由nvcc将其编译为可以在GPU上运行的格式.
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add<<<1, 1>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
nvcc编译的文件的后缀为.cu
- cuda中定义kernel在函数前加上
__global声明就可以了. - 在显存上分配内存使用cudaMallocManaged
- 调用一个函数使用<<< >>>符号.比如对add的函数的调用使用`add<<<1, 1>>>(N, x, y);`,关于其中参数的意义,后文再做解释.
- 需要cudaDeviceSynchronize()让cpu等待gpu上的计算做完再执行cpu上的操作
可以用nvprof做更详细的性能分析.
注意用sudo 否则可能报错.
sudo /usr/local/cuda/bin/nvprof ./add_cuda
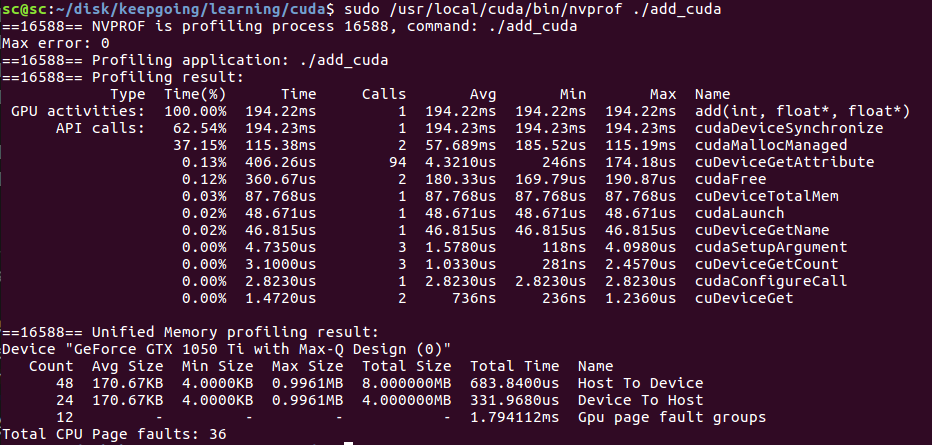
gpu上add用了194ms.
这里,我们注意到,跑在gpu反而比cpu更慢了.因为我们这段代码里`add<<<1, 1>>>(N, x, y);`并没有发挥gpu并行运算的优势,反而因为多了一些cpu与gpu的交互使得程序变慢了.
用GPU threads加速运算
重点来了
CUDA GPUS有多组Streaming Multiprocessor(SM).每个SM可以运行多个thread block. 每一个thread block有多个thread.
如下图所示:
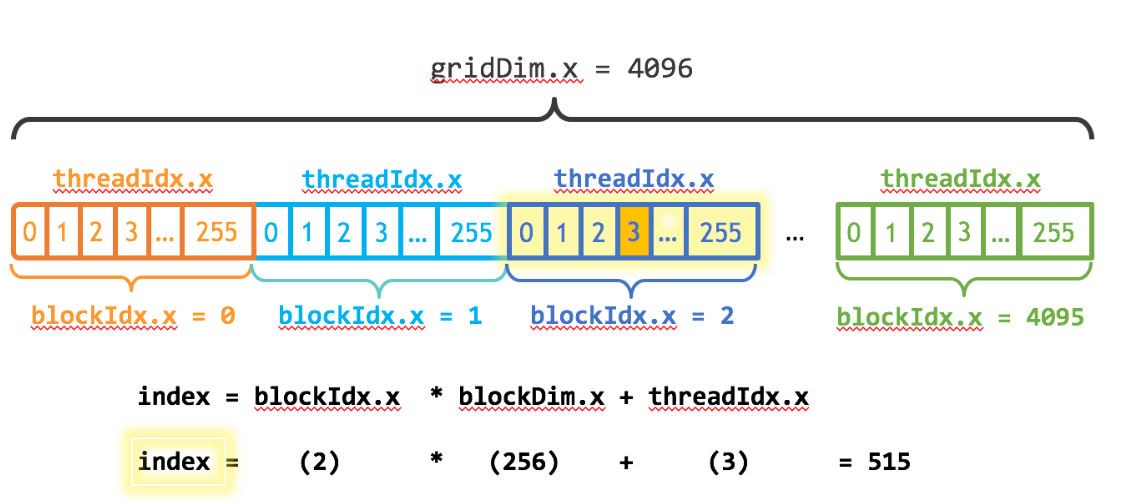
注意几个关键变量:
- blockDim.x 表明了一个thread block内含有多少个thread
- threadIdx.x 表明了当前thread在该thread blcok内的index
- blockIdx.x 表明了当前是第几个thread block
我们要做的就是把计算分配到所有的thread上去.这些thread上并行地做运算,从而达到加速的目的.
前面我们说到在cuda内调用一个函数(称之为kernel)的用法为<<<p1,p2>>>,比如`add<<<1, 1>>>(N, x, y);` 第一个参数的含义即为thread block的数量,第二个参数的含义为block内参与运算的thread数量.
现在来改写一下代码:
#include <iostream>
#include <math.h>
#include <stdio.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
printf("index=%d,stride=%d\n",index,stride);
for (int i = index; i < n; i+=stride)
{
y[i] = x[i] + y[i];
if(index == 0)
{
printf("i=%d,blockIdx.x=%d,thread.x=%d\n",i,blockIdx.x,threadIdx.x);
}
}
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add<<<1, 256>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
注意add的写法,我们把0,256,512...放到thread1计算,把1,257,...放到thread2计算,依次类推.调用的时候,add<<<1, 256>>>(N, x, y);表明我们只把计算分配到了thread block1内的256个thread去做.
编译这个程序(注意把代码里的printf注释掉,因为要统计程序运行时间):nvcc add_block.cu -o add_cuda_blcok -I/usr/local/cuda-9.0/include/ -L/usr/local/cuda-9.0/lib64

可以看到add的gpu时间仅仅用了2.87ms
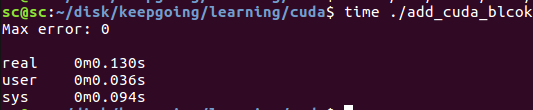
程序的整体运行时间为0.13s,主要是cudaMallocManaged,cudaDeviceSynchronize之类的操作耗费了比较多的时间.
再一次改写代码
这一次我们用更多的thread block.
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i+=stride)
{
y[i] = x[i] + y[i];
//printf("i=%d,blockIdx.x=%d\n",i,blockIdx.x);
}
}
编译:nvcc add_grid.cu -o add_cuda_grid -I/usr/local/cuda-9.0/include/ -L/usr/local/cuda-9.0/lib64
统计性能:

可以看出来,gpu上add所用的时间进一步缩小到1.8ms
参考:https://devblogs.nvidia.com/even-easier-introduction-cuda/
最新文章
- android开发虚拟机不能正常启动
- 【HDOJ】2388 Playground Hideout
- REST和SOAP Web Service的比较
- Java Instanceof
- list,map的疑问
- (摘录)26个ASP.NET常用性能优化方法
- PHP操作Mysql中间BLOB场
- 利用overflow实现导航栏中常 出现的倒三角下拉小图标
- 洛谷P2617 Dynamic Ranking(主席树,树套树,树状数组)
- 关于PHP7
- 数据库“行专列”操作---使用row_number()over(partition by 分组字段 [order by 排序字段])
- 利用zabbix api添加、删除、禁用主机
- OO_多线程电梯_单元总结
- 建立Heapster Influxdb Grafana集群性能监控平台
- MySQL索引操作
- 11.12git部分和redis
- vue extend 的基本使用
- day35-python 操作memcache二
- 几种常用的Interpolator(插值器)的动画效果
- 力扣(LeetCode) 14. 最长公共前缀