中阶 d04.1 xml解析
2024-09-07 04:59:54
##XML 解析 > 其实就是获取元素里面的字符数据或者属性数据。 ###XML解析方式(面试常问) > 有很多种,但是常用的有两种。 * DOM * SAX 
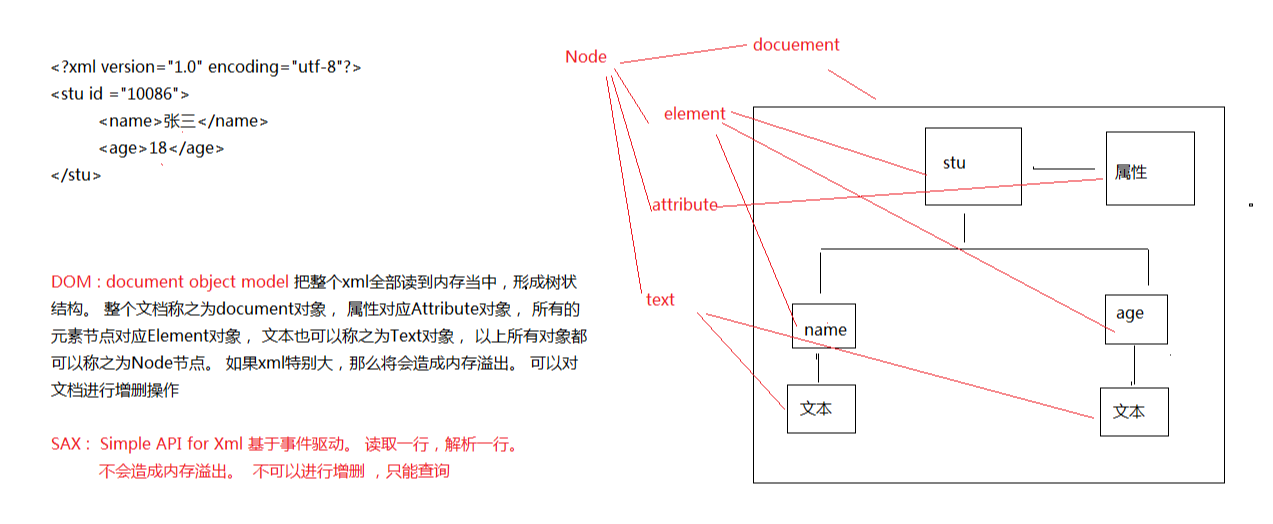
###针对这两种解析方式的API
> 一些组织或者公司, 针对以上两种解析方式, 给出的解决方案有哪些?
jaxp sun公司。 比较繁琐
jdom
dom4j 使用比较广泛
###Dom4j 基本用法
element.element("stu") : 返回该元素下的第一个stu元素
element.elements(); 返回该元素下的所有子元素。
1. 创建SaxReader对象(需要添加dom4j-1.6.1.jar)
2. 指定解析的xml
3. 获取根元素。
4. 根据根元素获取子元素或者下面的子孙元素
try {
//1. 创建sax读取对象
SAXReader reader = new SAXReader(); //jdbc -- classloader
//2. 指定解析的xml源
Document document = reader.read(new File("src/xml/stus.xml"));
//3. 得到元素、
//得到根元素
Element rootElement= document.getRootElement();
//获取根元素下面的子元素 age
//rootElement.element("age")
//System.out.println(rootElement.element("stu").element("age").getText());
//获取根元素下面的所有子元素 。 stu元素
List<Element> elements = rootElement.elements();
//遍历所有的stu元素
for (Element element : elements) {
//获取stu元素下面的name元素
String name = element.element("name").getText();
String age = element.element("age").getText();
String address = element.element("address").getText();
System.out.println("name="+name+"==age+"+age+"==address="+address);
}
} catch (Exception e) {
e.printStackTrace();
}
###Dom4j 的 Xpath使用
> dom4j里面支持Xpath的写法。 xpath其实是xml的路径语言,支持我们在解析xml的时候,能够快速的定位到具体的某一个元素。
1. 添加jar包依赖
jaxen-1.1-beta-6.jar
2. 在查找指定节点的时候,根据XPath语法规则来查找
3. 后续的代码与以前的解析代码一样。
//要想使用Xpath, 还得添加支持的jar 获取的是第一个 只返回一个。
Element nameElement = (Element) rootElement.selectSingleNode("//name");
System.out.println(nameElement.getText());
System.out.println("----------------");
//获取文档里面的所有name元素
List<Element> list = rootElement.selectNodes("//name");
for (Element element : list) {
System.out.println(element.getText());
}
##XML 约束【了解】
如下的文档, 属性的ID值是一样的。 这在生活中是不可能出现的。 并且第二个学生的姓名有好几个。 一般也很少。那么怎么规定ID的值唯一, 或者是元素只能出现一次,不能出现多次? 甚至是规定里面只能出现具体的元素名字。
<stus>
<stu id="10086">
<name>张三</name>
<age>18</age>
<address>深圳</address>
</stu>
<stu id="10086">
<name>李四</name>
<name>李五</name>
<name>李六</name>
<age>28</age>
<address>北京</address>
</stu>
</stus>
###DTD
语法自成一派, 早起就出现的。 可读性比较差。
1. 引入网络上的DTD
<!-- 引入dtd 来约束这个xml -->
<!-- 文档类型 根标签名字 网络上的dtd dtd的名称 dtd的路径
<!DOCTYPE stus PUBLIC "//UNKNOWN/" "unknown.dtd"> -->
2. 引入本地的DTD
<!-- 引入本地的DTD : 根标签名字 引入本地的DTD dtd的位置 -->
<!-- <!DOCTYPE stus SYSTEM "stus.dtd"> -->
2. 直接在XML里面嵌入DTD的约束规则
<!-- xml文档里面直接嵌入DTD的约束法则 -->
<!DOCTYPE stus [
<!ELEMENT stus (stu)>
<!ELEMENT stu (name,age)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
]>
<stus>
<stu>
<name>张三</name>
<age>18</age>
</stu>
</stus>
<!ELEMENT stus (stu)> : stus 下面有一个元素 stu , 但是只有一个
<!ELEMENT stu (name , age)> stu下面有两个元素 name ,age 顺序必须name-age
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ATTLIST stu id CDATA #IMPLIED> stu有一个属性 文本类型, 该属性可有可无
元素的个数:
+ 一个或多个
* 零个或多个
? 零个或一个
属性的类型定义
CDATA : 属性是普通文字
ID : 属性的值必须唯一
<!ELEMENT stu (name , age)> 按照顺序来
<!ELEMENT stu (name | age)> 两个中只能包含一个子元素
###Schema
其实就是一个xml , 使用xml的语法规则, xml解析器解析起来比较方便 , 是为了替代DTD 。
但是Schema 约束文本内容比DTD的内容还要多。 所以目前也没有真正意义上的替代DTD
约束文档:
<!-- xmlns : xml namespace : 名称空间 / 命名空间
targetNamespace : 目标名称空间 。 下面定义的那些元素都与这个名称空间绑定上。
elementFormDefault : 元素的格式化情况。 -->
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itheima.com/teacher"
elementFormDefault="qualified">
<element name="teachers">
<complexType>
<sequence maxOccurs="unbounded">
<!-- 这是一个复杂元素 -->
<element name="teacher">
<complexType>
<sequence>
<!-- 以下两个是简单元素 -->
<element name="name" type="string"></element>
<element name="age" type="int"></element>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
实例文档:
<?xml version="1.0" encoding="UTF-8"?>
<!-- xmlns:xsi : 这里必须是这样的写法,也就是这个值已经固定了。
xmlns : 这里是名称空间,也固定了,写的是schema里面的顶部目标名称空间
xsi:schemaLocation : 有两段: 前半段是名称空间,也是目标空间的值 , 后面是约束文档的路径。
-->
<teachers
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itheima.com/teacher"
xsi:schemaLocation="http://www.itheima.com/teacher teacher.xsd"
>
<teacher>
<name>zhangsan</name>
<age>19</age>
</teacher>
<teacher>
<name>lisi</name>
<age>29</age>
</teacher>
<teacher>
<name>lisi</name>
<age>29</age>
</teacher>
</teachers>
##名称空间的作用
一个xml如果想指定它的约束规则, 假设使用的是DTD ,那么这个xml只能指定一个DTD , 不能指定多个DTD 。 但是如果一个xml的约束是定义在schema里面,并且是多个schema,那么是可以的。简单的说: 一个xml 可以引用多个schema约束。 但是只能引用一个DTD约束。
名称空间的作用就是在 写元素的时候,可以指定该元素使用的是哪一套约束规则。 默认情况下 ,如果只有一套规则,那么都可以这么写
<name>张三</name>
<aa:name></aa:name>
<bb:name></bb:name>
xml文件

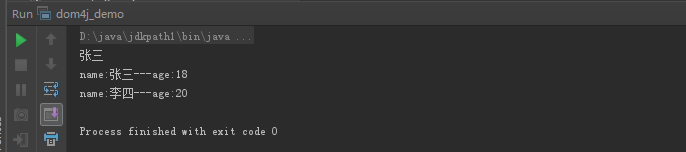
dom4j用法代码示例(获取元数要多层element)
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader; import java.io.File;
import java.util.List; public class dom4j_demo {
public static void main(String[] args) {
try {
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File("D:\\java\\java_workspace\\9_xml\\src\\sutdents.xml")); //得到根元素
Element element = document.getRootElement();
//获取根元素下面的子元素 age
System.out.println(element.element("stu").element("name").getText()); //获取根元素下面的所有子元素 。 stu元素
List<Element> list = element.elements();
//遍历所有的stu元素
for (Element elm : list) {
String name = elm.element("name").getText();
String age = elm.element("age").getText();
System.out.println("name:"+name +"---"+ "age:"+age);
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
输出
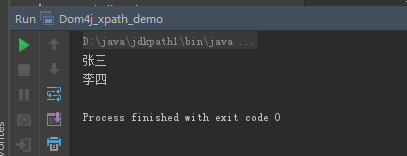
xpath用法(用法 优点:根据路径直接查找/stu //name ///dsaf...)多层查找
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.dom4j.xpath.DefaultXPath; import java.io.File;
import java.util.List; public class Dom4j_xpath_demo {
public static void main(String[] args) {
try {
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File("D:\\java\\java_workspace\\9_xml\\src\\sutdents.xml"));
Element rootElement = document.getRootElement(); /* //想要使用Xpath,需要添加依赖的jar:jaxen-1.1-beta-6.jar。否则会报错notfound class jaxenxxx
//Node可以理解为对象,参考parse_type.png
//向下转型使用Element接收
// "//name"用法参考xpath api:XPathTutorial.chm
Element nameelement = (Element) rootElement.selectSingleNode("//age");
System.out.println(nameelement.getText());*/ List<Element> list = rootElement.selectNodes("//name");
for(Element element1 : list) {
String name = element1.getText();
System.out.println(name);
} } catch (DocumentException e) {
e.printStackTrace();
}
}
}
输出
最新文章
- Phantomjs+Nodejs+Mysql数据抓取(1.数据抓取)
- 日期控件jsdate用法注意事项
- JavaScript 中 的prototype和__proto__
- Android Studio 设置不自动缩进匿名内部类
- _AR="ar" _ARFLAGS="-ruv"
- 解析xml报classnotfound错误
- Java再学习——synchronized与volatile
- UVa 11609 (计数 公式推导) Teams
- Windows 7下 搭建 基于 ssh 的sftp 服务器
- Android中的Menu
- mysqladmin在SuSE linux系统中--sleep參数使用不准确问题
- 在Windows Server 2008 R2 Server中,连接其他服务器的数据库遇到“未启用当前数据库的 SQL Server Service Broker,因此查询通知不受支持。如果希望使用通知,请为此数据库启用 Service Broker ”
- python---cookie模拟登陆和模拟session原理
- Practice1小学四则运算
- vue父子间通信
- C# xml通过xslt转换为html输出
- RMAN备份详解
- 前端~HTML~CSS~JavaScript~JQuery~Vue
- 阻止MyEclipse启动项目时自动跳转的debug视图
- 让一个 csproj 项目指定多个开发框架
热门文章
- React利用Antd的Form组件实现表单功能(转载)
- File 关键词
- 您知道SASS吗?
- Netty中ChannelHandler的生命周期
- MySQL对JSON类型UTF-8编码导致中文乱码探讨
- [Unity] Unity 2019.1.14f 在Terrain中使用Paint Texture的方法
- Python——迭代器的几个高级用法
- Building Applications with Force.com and VisualForce(Dev401)(七):Designing Applications for Multiple users:Managing your users' experience I
- 用序列到序列和注意模型实现的:Translation with a Sequence to Sequence Network and Attention
- PHP7内核:源码分析的环境与工具