xml(3)
2024-09-07 11:50:17
xml的解析方式:dom解析和sax解析
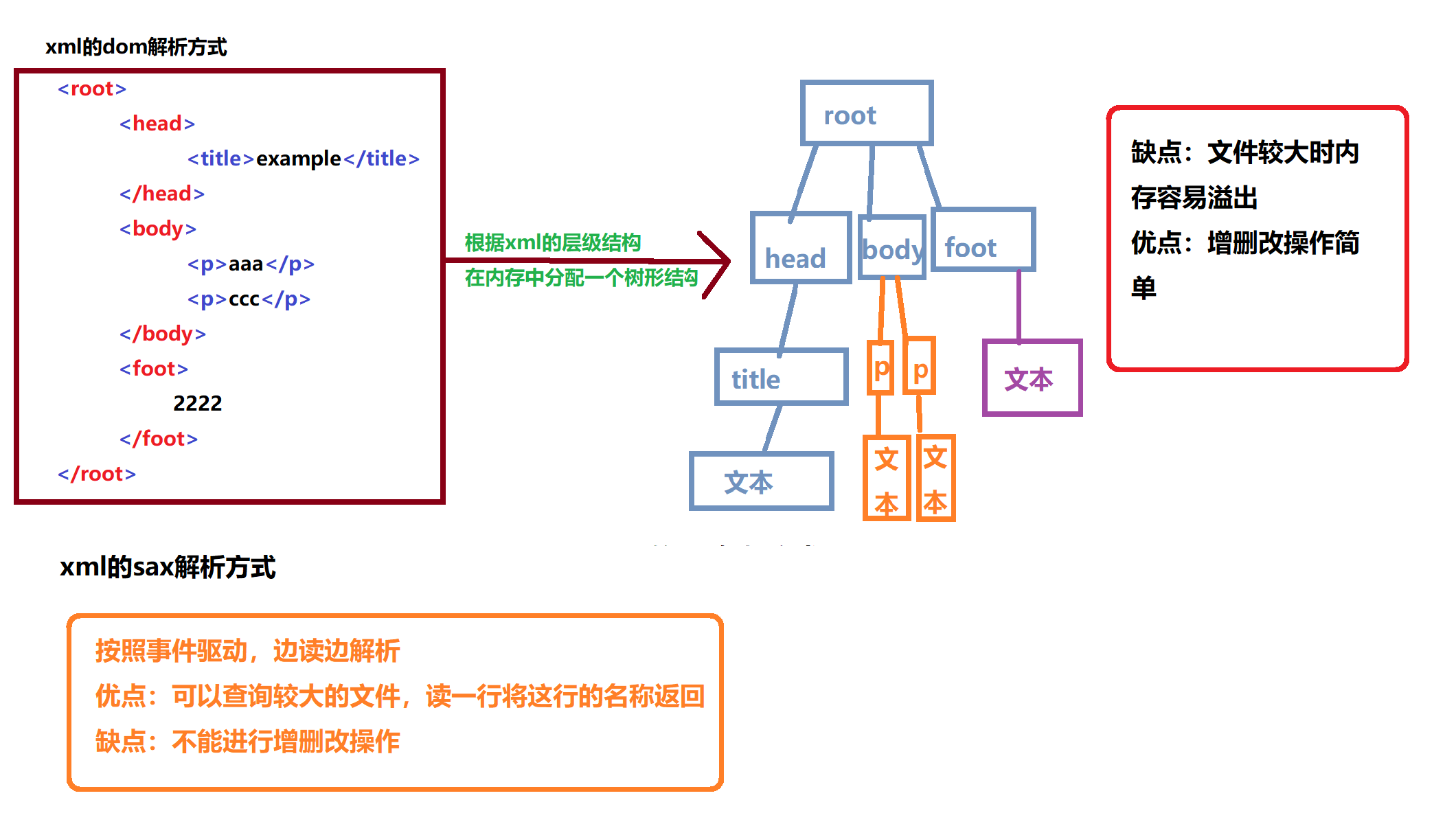
DOM解析
使用jaxp进行增删改查
1.创建DocumentBuilderFactory工厂
2.通过DocumentBuilderFactory工厂创建DocumentBuilder
3.解析xml,得到Document对象
*在对document进行增删改查操作时,需要回写到xml中:
1.创建TransformerFactory回写工厂
2.通过回写工厂,获得Transformer
3.Transformer.transform(new DOMSource(document),new StreamResult(""))
查
private static void selectALL() throws Exception {
/**
*
* 1.创建DocumentFacTory工厂
* 2.通过Document Factory工厂得到DocumentBuilder
* 3.解析xml得到Document对象
*/
//创建工厂
DocumentBuilderFactory documentBuilderFactory=DocumentBuilderFactory.newInstance();
//创建BUilder
DocumentBuilder documentBuilder=documentBuilderFactory.newDocumentBuilder();
//解析xml 获得document对象
Document document=documentBuilder.parse("src/com//zyf/test.xml");
//获得所有name元素
NodeList list=document.getElementsByTagName("sex");
//遍历
for(int i=0;i<list.getLength();i++){
Node node1=list.item(i);
System.out.println(node1.getTextContent());
}
}
增
public static void addSex() throws Exception{
//创建工厂
DocumentBuilderFactory documentBuilderFactory=DocumentBuilderFactory.newInstance();
//获得builder
DocumentBuilder documentBuilder=documentBuilderFactory.newDocumentBuilder();
//获得deocument
Document document=documentBuilder.parse("src/com/zyf/test.xml");
//创建节点<sex>nv</sex>
Node sex=document.createElement("sex");
//在sex中创建文本
Node text=document.createTextNode("nv");
// sex.setTextContent("nv");
sex.appendChild(text);
//得到sex的父节点<p1>
NodeList list=document.getElementsByTagName("p1");
Node node1=list.item(0);
//添加进父节点p1
node1.appendChild(sex);
//回写
TransformerFactory transformerFactory=TransformerFactory.newInstance();
Transformer transformer=transformerFactory.newTransformer();
transformer.transform(new DOMSource(document),new StreamResult("src/com/zyf/test.xml"));
}
删
public static void removeSex()throws Exception{
//创建工厂
DocumentBuilderFactory documentBuilderFactory=DocumentBuilderFactory.newInstance();
//闯将builder
DocumentBuilder documentBuilder=documentBuilderFactory.newDocumentBuilder();
//获得document
Document document=documentBuilder.parse("src/com/zyf/test.xml");
//获得sex的父节点
//获得sex
NodeList list=document.getElementsByTagName("sex");
Node node1=list.item(0);
//获得sex的父节点
Node parent=node1.getParentNode();
//remove
parent.removeChild(node1);
//回写
//回写工厂
TransformerFactory transformerFactory=TransformerFactory.newInstance();
Transformer transformer=transformerFactory.newTransformer();
transformer.transform(new DOMSource(document), new StreamResult("src/com/zyf/test.xml"));
}[Document是Node的子类]
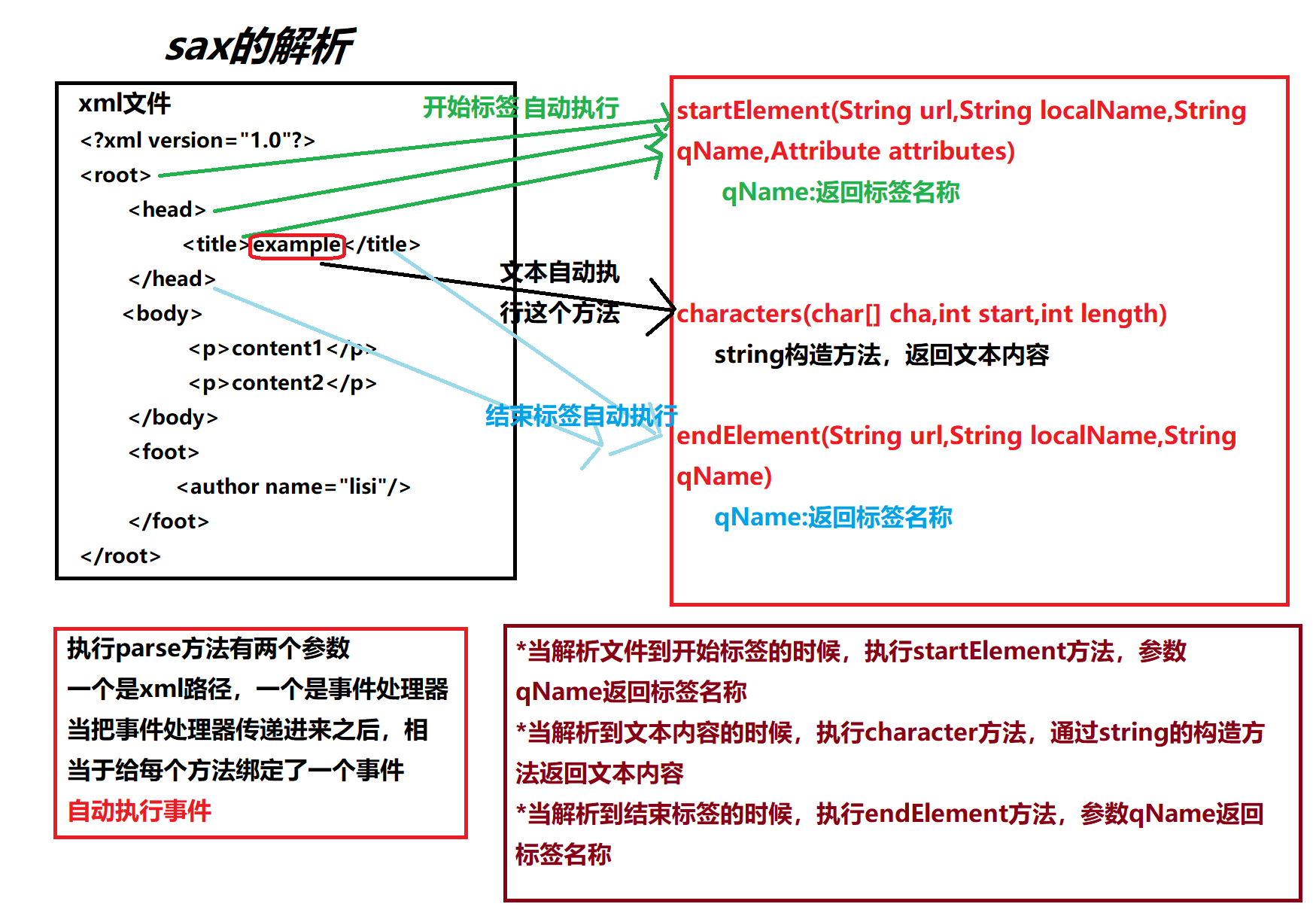
xml的sax解析方式
最新文章
- (。・・)ノ~个人java学习随笔记录
- Chp11 11.7
- 烂泥:apache密码生成工具htpasswd的应用
- ASP.NET MVC Error
- oracle 事务测试
- viPlugin安装破解
- Windows Phone 8初学者开发—第7部分:本地化应用程序
- visual SVN 反编译破解
- ThinkPHP中,display和assign用法详解
- SQL Server 删除重复记录,只保留一条记录
- BZOJ.2655.calc(DP/容斥 拉格朗日插值)
- [转]html5: postMessage解决跨域和跨页面通信的问题
- [转]CentOS虚拟机如何设置共享文件夹,并在Windows下映射网络驱动器?
- Gcc ------ gcc的使用简介与命令行参数说明
- warning: ignoring option PermSize=256m; support was removed in 8.0
- springmvc拦截器的配置、使用
- jquery validate ajax 验证重复的2种方法
- web ul li
- 线段树lazy标记??Hdu4902
- mysql大数据表删除操作锁表,导致其他线程等待锁超时(Lock wait timeout exceeded; try restarting transaction;)