Python中import模块时报SyntaxError: (unicode error)utf-8 codec can not decode 错误的解决办法
2024-10-04 22:16:20
老猿有个通过UE编辑(其他文本编辑器一样有类似问题)的bmi.py文件,在Python Idle环境打开文件执行时没有问题,但import时报错:
SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xc7 in position 0: invalid continuation byte,具体报错截图如下:

老猿知道这是字符集编码的问题,应该是Python import文件是支持UTF-8编码,而老猿存储时是GBK的编码导致,怎么解决该问题呢?有以下三种办法:
1、文件存储时以UTF-8编码存储,每个编辑器应该都可以设置文件存储的编码格式,老猿的编辑器是UE,相关格式设置界面请见下面截图:
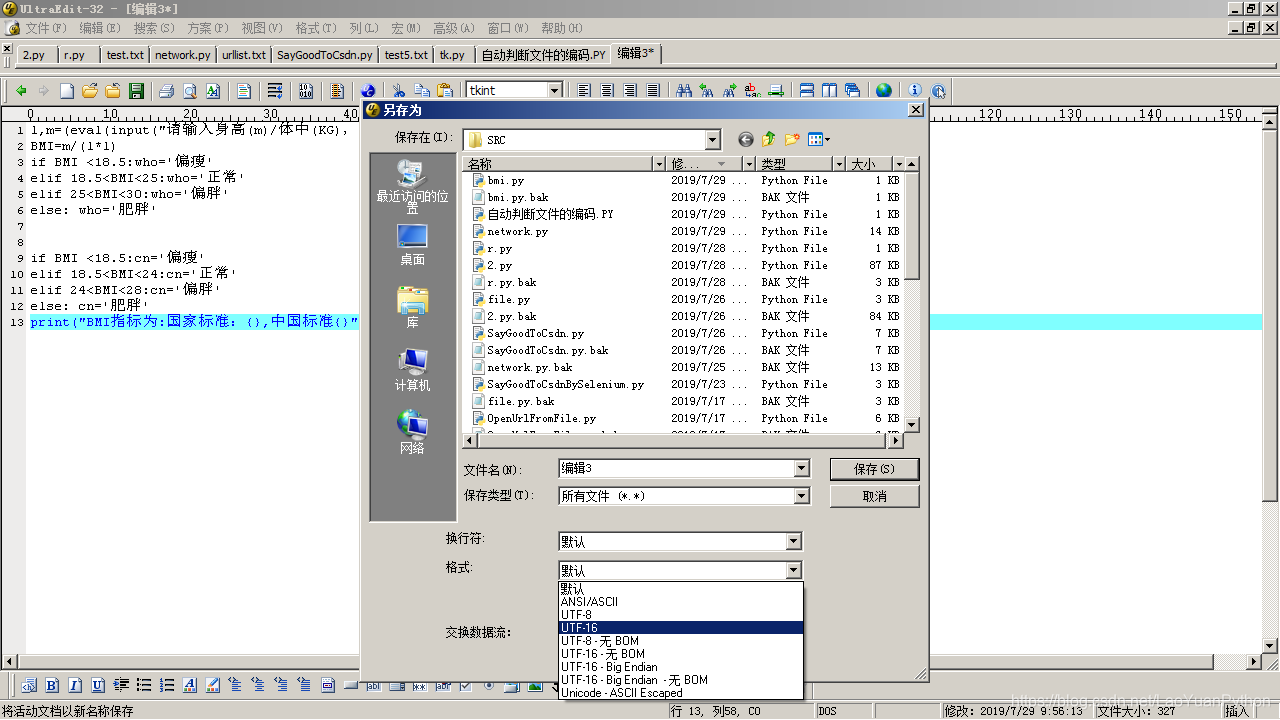
再将文件另存一下就可以了。
方法二,使用IDLE打开文件再进行格式转换
使用IDLE打开非UTF-8编码的文件时,系统会有如下提示信息:
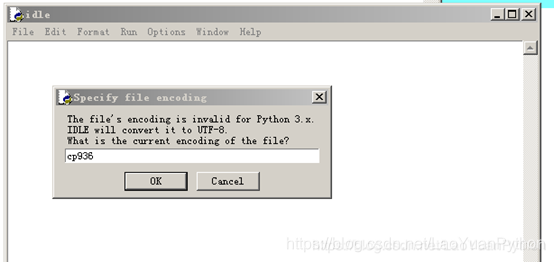
此时只要输入正确编码(Python默认会根据操作系统的设置给出一个默认值),如中文选择cp936(具体字符集和代码也的映射关系请见《转:使用DOS命令chcp查看windows操作系统的默认编码以及编码和语言的对应关系》)。
打开成功后将文件再保存一下就可以将格式修改为Python可以正确解码的格式了。
方法三,直接在文件中给出文件本身的编码格式就可以了,如果是中文编码的,可以在首行添加:
#-*-coding: GBK -*-
就可以正常识别了。
老猿Python,跟老猿学Python!
博客地址:https://blog.csdn.net/LaoYuanPython
请大家多多支持,点赞、评论和加关注!谢谢!
最新文章
- GWAS Simulation
- asp.net关于页面不回发的问题,寻求完美解决方案
- datagrid后台分页js.js
- UIStepper swift
- log4net 配置
- VC++非MFC项目中如何使用TRACE宏
- CF 675 div2C 数学 让环所有值变为0的最少操作数
- 设计模式——备忘录模式(C++实现)
- git 同步勾子
- debug_backtrace
- 关于indexof和substring经常记不住的点
- HDU 6346 整数规划 (最佳完美匹配)
- C 语言的 GCC 扩展
- Reactor 3 学习笔记(1)
- nodejs(log4js)服务中应用splunk进行Log存储、搜索、分析、监控、警告
- 避免使用jQuery的html方法来替换标签,而是使用replaceWith方法
- .Net高级技术——字符串拘留池(Intern)
- 复数 一级ADT实现
- linux信息查看手记
- Manager Test and DAO