spark编程入门-idea环境搭建
原文引自:http://blog.csdn.net/huanbia/article/details/69084895
1、环境准备
idea采用2017.3.1版本。
创建一个文件a.txt

2、构建maven工程
点击File->New->Project…
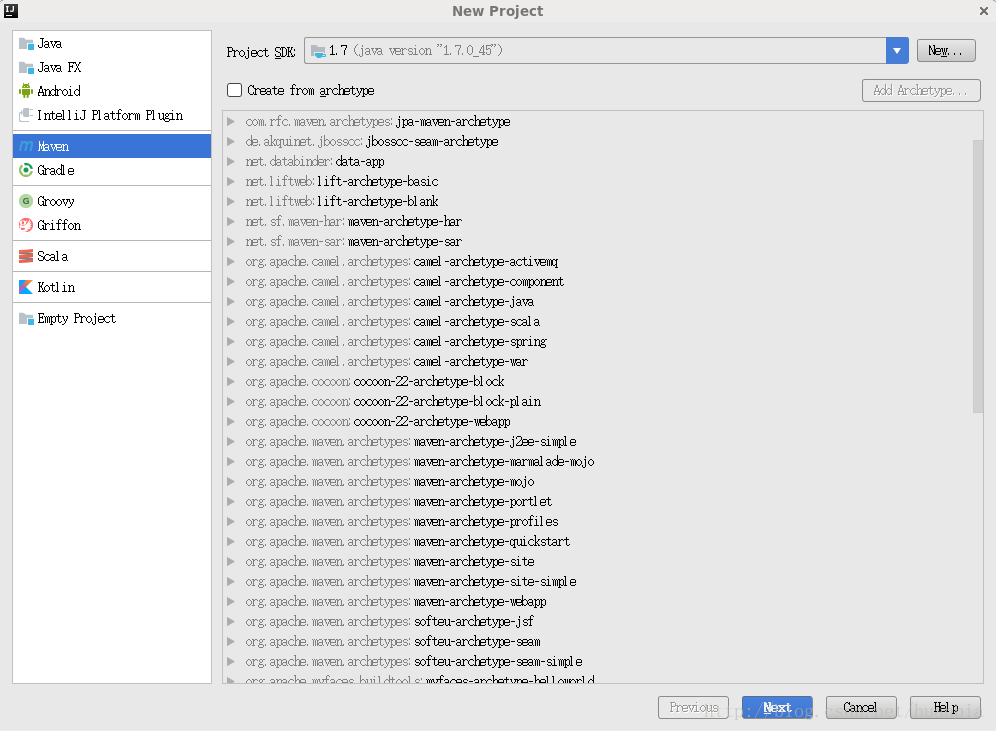
点击Next,其中GroupId和ArtifactId可随意命名

点击Next
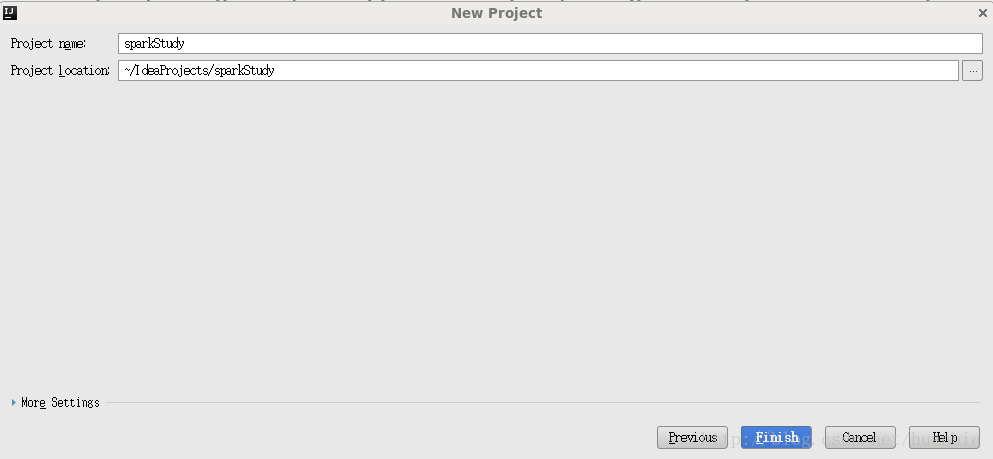
点击Finish,出现如下界面:
3、书写wordCount代码
请在pom.xml中的version标签后追加如下配置
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.2-beta-5</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.3</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<maniClass></maniClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.3.1</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>false</includeProjectDependencies>
<classpathScope>compile</classpathScope>
<mainClass>com.dt.spark.SparkApps.App</mainClass>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId> <configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
</plugins>
</build>
点击右下角的Import Changes导入相应的包

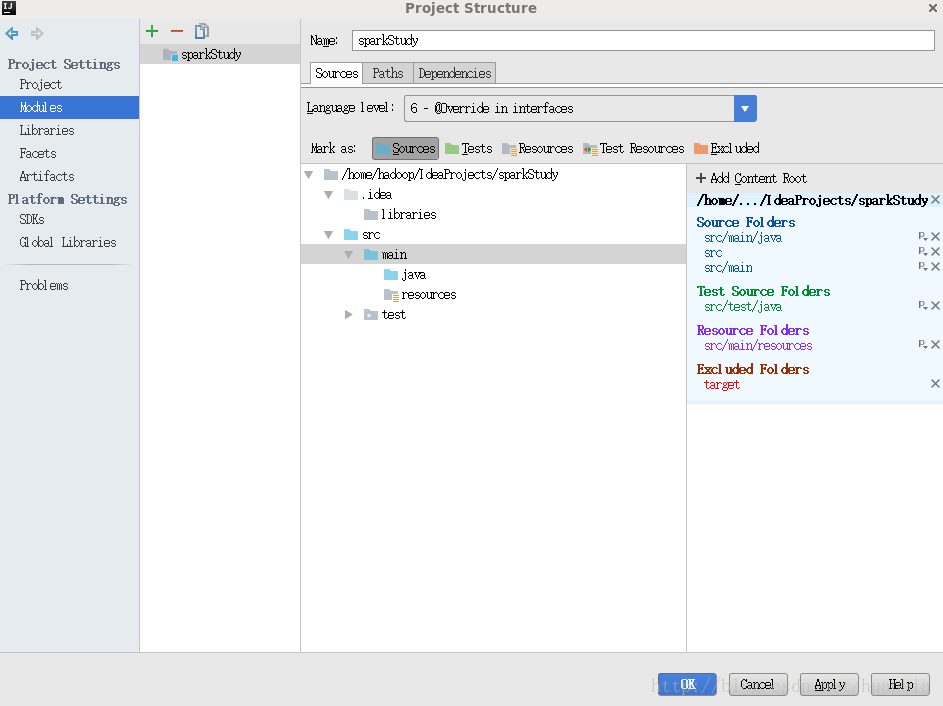
点击File->Project Structure…->Moudules,将src和main都选为Sources文件
在java文件夹下创建SparkWordCount java文件
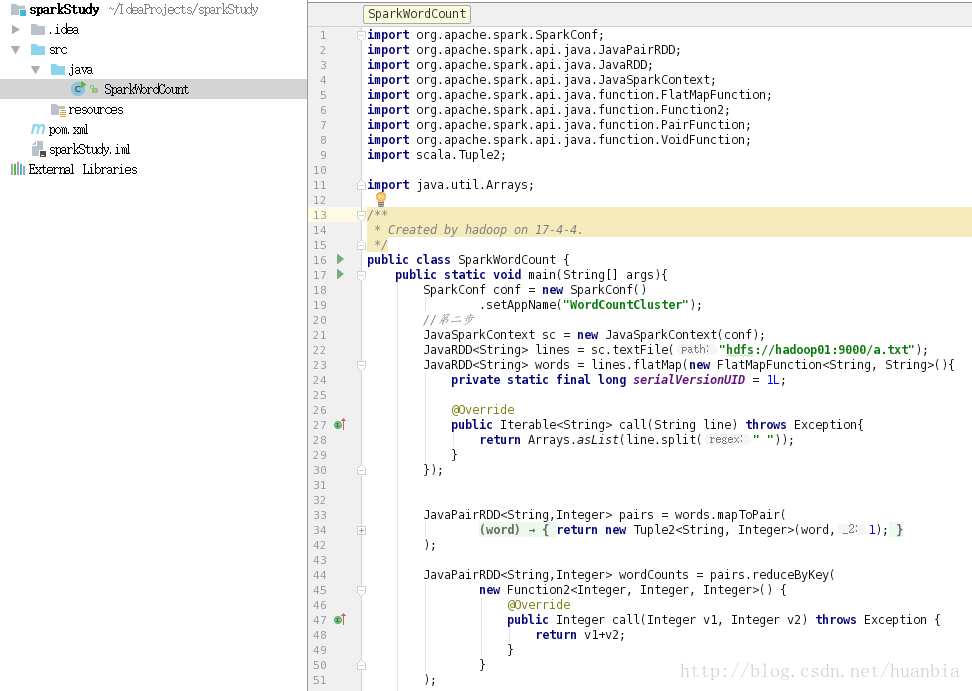
该文件代码为:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2; import java.util.Arrays; /**
* Created by hadoop on 17-4-4.
*/
public class SparkWordCount {
public static void main(String[] args){
SparkConf conf = new SparkConf()
.setAppName("WordCountCluster");
//第二步
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://hadoop01:9000/a.txt");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>(){
private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String line) throws Exception{
return Arrays.asList(line.split(" "));
}
}); JavaPairRDD<String,Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
}
); JavaPairRDD<String,Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}
); wordCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1+" : "+ wordCount._2 );
}
}); sc.close(); }
}
打包:
执行
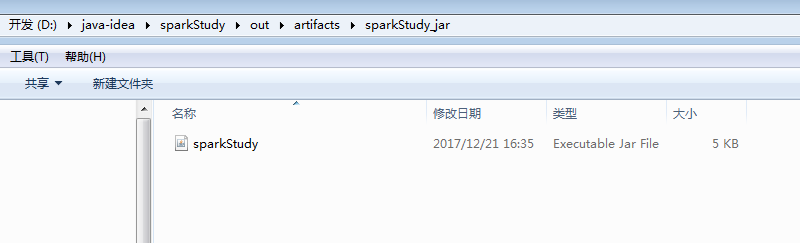
会在output目录下 生成可执行jar包 sparkStudy
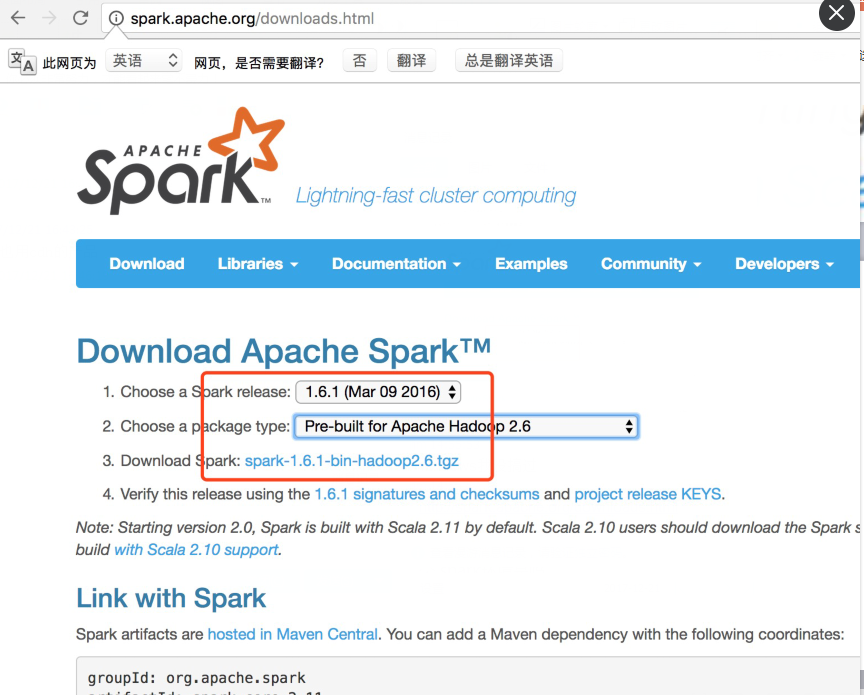
4、jar包上传到集群并执行
从spark官方网站 下载spark-1.6.1-bin-hadoop2.6.tgz
Spark目录:
bin包含用来和Spark交互的可执行文件,如Spark shell。
examples包含一些单机Spark job,可以研究和运行这些例子。
Spark的Shell:
Spark的shell能够处理分布在集群上的数据。
Spark把数据加载到节点的内存中,因此分布式处理可在秒级完成。
快速使用迭代式计算,实时查询、分析一般能够在shells中完成。
Spark提供了Python shells和Scala shells。
解压

这里需要先启动集群:
启动master: ./sbin/start-master.sh
启动worker: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
这里的地址为:启动master后,在浏览器输入localhost:8080,查看到的master地址

启动成功后,jps查看进程:
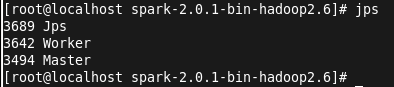
接下来执行提交命令,将打好的jar包上传到linux目录,jar包在项目目录下的out\artifacts下。
提交作业: ./bin/spark-submit --master spark://localhost:7077 --class WordCount /home/lucy/learnspark.jar
可以在4040端口查看job进度:
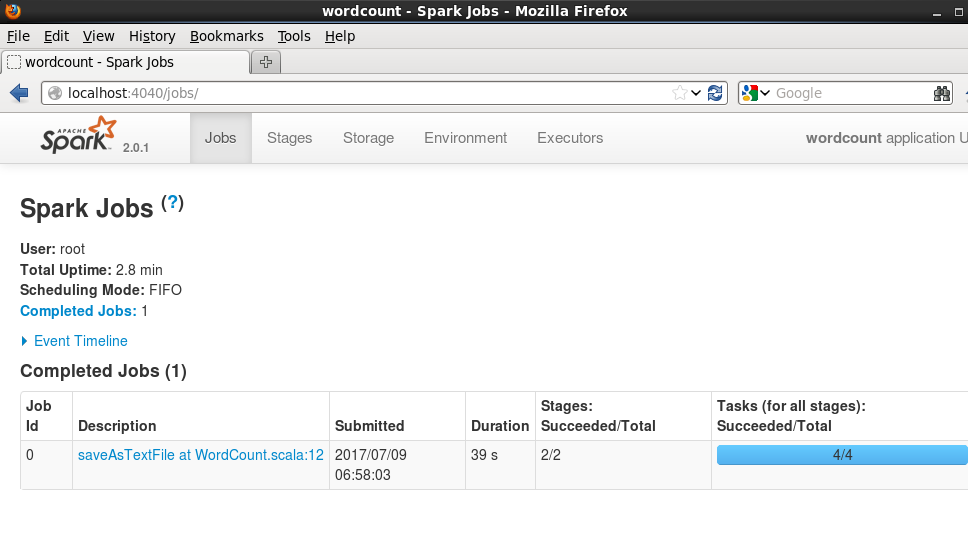
将执行的包上传到服务器上,封装执行的脚本。


然后执行脚本,执行结果如下:
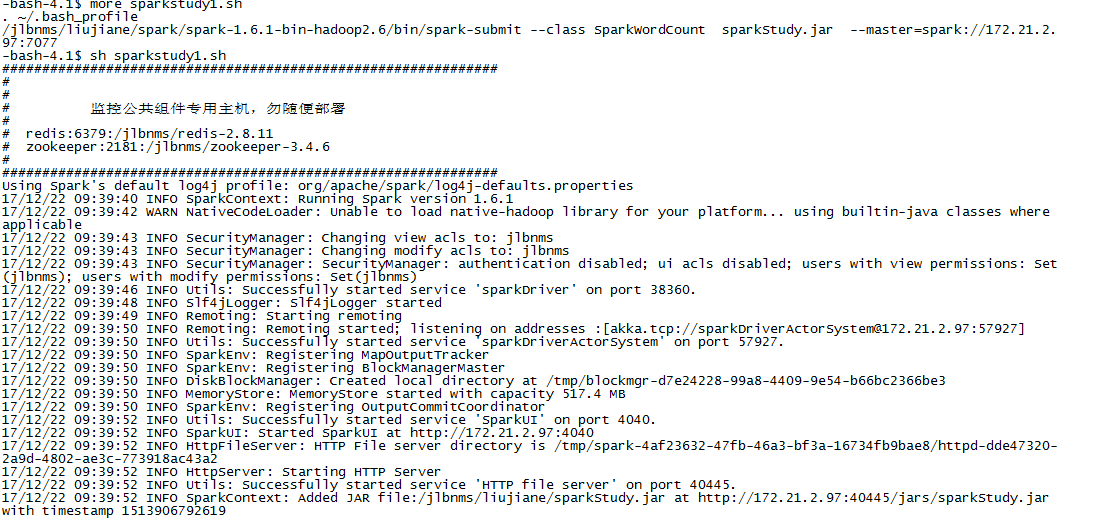
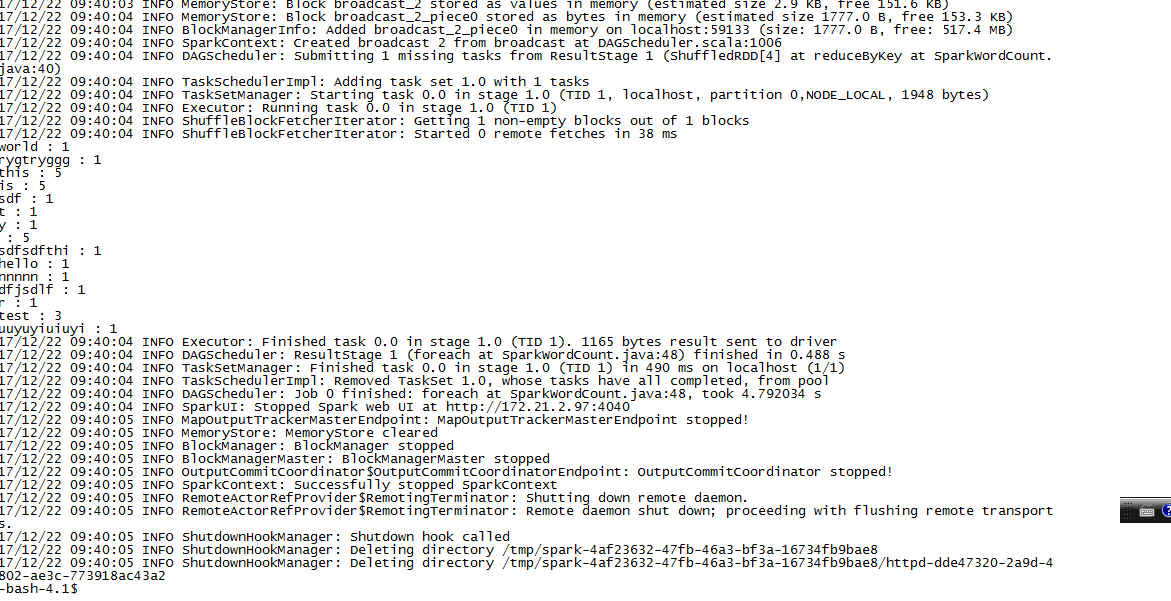
任务执行结束。
最新文章
- 使用Zabbix监控Oracle数据库
- 【知识必备】RxJava+Retrofit二次封装最佳结合体验,打造懒人封装框架~
- 执行HQL语句出现Remember that ordinal parameters are 1-based
- ASP.NET多个Button的页面,回车执行按钮事件(转)
- 转!!java中Object转String
- LeetCode44 Wildcard Matching
- corosync+pacemaker and drbd实现mysql高可用集群
- 【转】 Android Studio SVN 使用方法
- ECSTORE 关于前台页面DIALOG的调用
- GridView事件DataBinding,DataBound,RowCreated,RowDataBound区别及执行顺序分析
- 轻量级的内部测试过程r \\ u0026研发团队
- Vijos P1114 FBI树【DFS模拟,二叉树入门】
- Codeforces Round #343 (Div. 2)-629A. Far Relative’s Birthday Cake 629B. Far Relative’s Problem
- [Swift]LeetCode59. 螺旋矩阵 II | Spiral Matrix II
- nginx安装SSL证书,并强制跳转https访问
- SQLite reset password
- P4008 [NOI2003]文本编辑器
- TabNavigator Container Example
- ajax中的contendType和dataType知识点梳理
- 一)如何开始 ehcache ?