TensorFlow学习笔记2-性能分析工具
TensorFlow学习笔记2-性能分析工具
性能分析工具
- 在spyder中运行以下代码:
import tensorflow as tf
from tensorflow.python.client import timeline
#构造计算图
x = tf.random_normal([1000, 1000])
y = tf.random_normal([1000, 1000])
res = tf.matmul(x, y)
#运行计算图, 同时进行跟踪
with tf.Session() as sess:
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
sess.run(res, options=run_options, run_metadata=run_metadata)
#创建Timeline对象,并将其写入到一个json文件
tl = timeline.Timeline(run_metadata.step_stats)
ctf = tl.generate_chrome_trace_format()
with open('timeline.json', 'w') as f:
f.write(ctf)
使用with tf.Session() as sess进行处理,运算完成后会自动关闭session,不需要再显示地sess.close()
上述代码将session的运行情况写入到timeline.json文件。
注意:如果上述代码在spyder中报错,报错内容为 Couldn't open CUDA library cupti64_92.dll
解决办法: 用everything搜索cupti64_92.dll,并把它复制到你的CUDA环境变量对应的目录:如\CUDA\v9.2\bin\cupti64_92.dll
- 打开你的源文件路径,可以看到已经有了
timeline.json文件。在chrome浏览器中打开chrome://tracing/,然后load上述timeline.json文件,可以看到时序图。
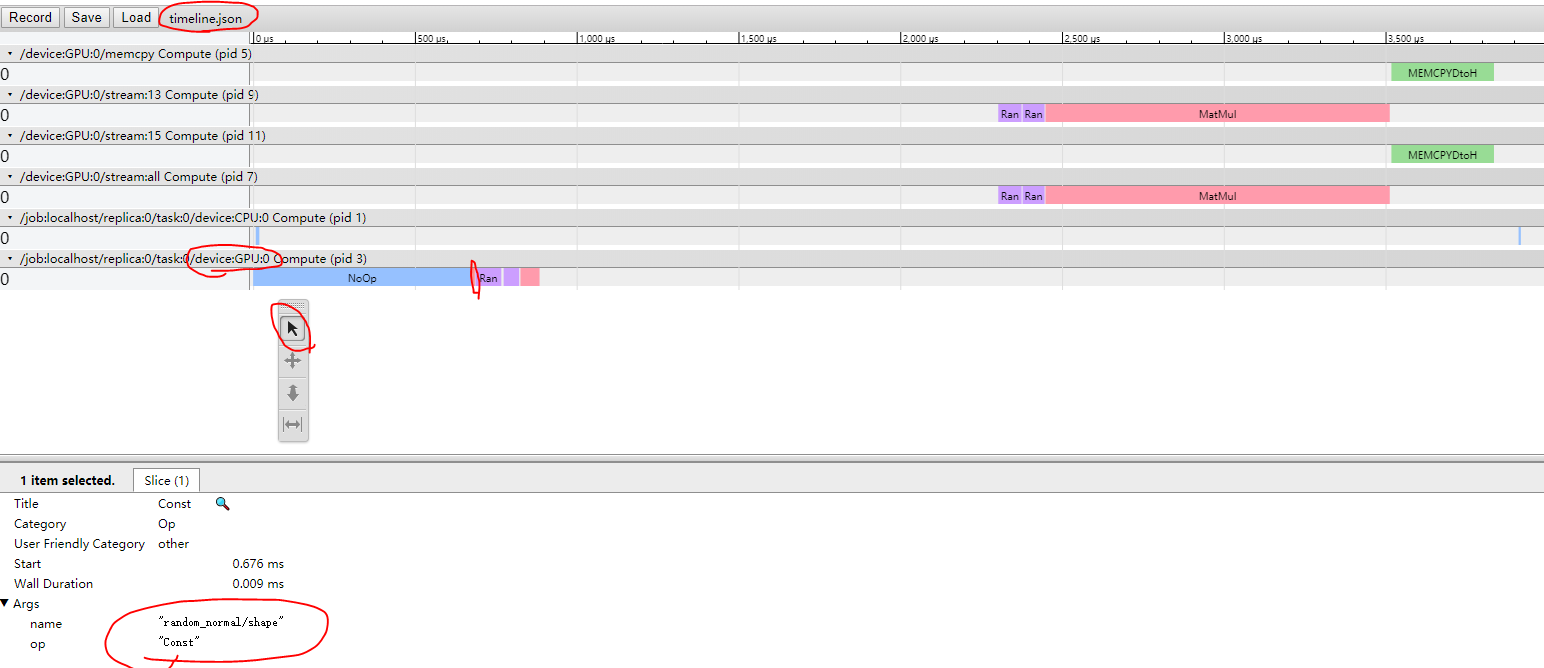
- 进行分析:
左下角的Args中:
- name:输出tensor
- op:运算
- input0:输入tensor
以pid 3为例,是GPU:0的进程:点击NoOp,这意味着没有Op操作;然后是Const操作,它没有输入,输出是random_normal/shape;然后RandomStandardNormal操作,它输入是random_normal/shape,输出是random_normal/RandomStandardNormal;紧接着仍然是RandomStandardNormal操作,它输入也是random_normal/shape,输出是random_normal_1/RandomStandardNormal;最后是MatMul操作,输入是random_normal/RandomStandardNormal与random_normal_1/RandomStandardNormal,输出是MatMul。
- 指派设备
上述代码是默认指派到gpu0进行运算的,你也可以用with tf.device('/cpu:0')将运算指派到你想要的设备:例如,你可以将上述代码更改为:
import tensorflow as tf
from tensorflow.python.client import timeline
#构造计算图
with tf.device('/cpu:0'):
x = tf.random_normal([1000, 1000])
y = tf.random_normal([1000, 1000])
res = tf.matmul(x, y)
#运行计算图, 同时进行跟踪
with tf.Session() as sess:
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
sess.run(res, options=run_options, run_metadata=run_metadata)
#创建Timeline对象,并将其写入到一个json文件
tl = timeline.Timeline(run_metadata.step_stats)
ctf = tl.generate_chrome_trace_format()
with open('timeline.json', 'w') as f:
f.write(ctf)
在浏览器中打开timeline.json后,可以看到
- 常量的生成,随机矩阵的创建是在CPU进行运算;
- 将两个随机矩阵内存搬运到GPU(MEMCPYHtoD);
- 在GPU上进行MatMul运算;
- 将GPU的运算结果搬回CPU(MEMCPYDtoH)。
警告
当你每次调用 sess.run 时,一定要确保好,不要设置 FULL_TRACE,否则会降低训练的速度。可以每100-1k 次训练设置1次FULL_TRACE.
最新文章
- firefox,跨域ajax 调用方法
- 柏克EPS应急电源签约联达大厦保安全
- nginx入门到精通目录
- python3_RoboBrowser_test
- SDUT1479数据结构实验之栈:行编辑器
- 最短路径(Floyd 模板题)
- 早期练手:功能相对比较完善的 js 计算器
- Neural Networks and Deep Learning(神经网络与深度学习) - 学习笔记
- 扩展Python模块系列(二)----一个简单的例子
- 图论中DFS与BFS的区别、用法、详解…
- web配置详细解释
- spring cloud gateway - RequestRateLimiter
- Java -- JDBC 学习--批量处理
- 02-body标签中相关标签
- 在Wmware虚拟机上如何检查是否CPU支持虚拟化 和 加载kvm模块
- [Pytorch]PyTorch使用tensorboardX(转
- LAMP+Varnish的实现
- 解决时间控件input不能选择的问题
- 信号处理的好书Digital Signal Processing - A Practical Guide for Engineers and Scientists
- linux基础(8)-颜色显示