Java 之 HashMap 集合
一、HashMap 概述
java.util.HashMap<k,v> 集合 implements Map<k,v> 接口
HashMap 集合的特点:
1、HashMap 集合底层是哈希表:查询速度特别的快
JDK 1.8 之前:数组+单向链表
JDK 1.8 之后:数组+单向链表 | 红黑树(链表的长度超过8):提高查询的速度
2、HashMap 集合是一个无序的集合,存储元素和取出元素的顺序有可能不一致
二、HashMap 存储自定义类型键值
HashMap存储自定义类型键值
Map集合保证key是唯一的:作为key的元素,必须重写hashCode方法和equals方法,以保证key唯一
三、遍历集合
参考 Map 集合的遍历方式:Map 遍历
四、Hashmap 源码分析
1、hashCode 值
hash算法是一种可以从任何数据中提取出其“指纹”的数据摘要算法,它将任意大小的数据映射到一个固定大小的序列上,这个序列被称为hash code、数据摘要或者指纹。比较出名的hash算法有MD5、SHA。hash是具有唯一性且不可逆的,唯一性是指相同的“对象”产生的hash code永远是一样的。

2、Entry 数组
HashMap和Hashtable是散列表,其中维护了一个长度为2的幂次方的Entry类型的数组table,数组的每一个元素被称为一个桶(bucket),你添加的映射关系(key,value)最终都被封装为一个Map.Entry类型的对象,放到了某个table[index]桶中。
使用数组的目的是查询和添加的效率高,可以根据索引直接定位到某个table[index]。
(1)数组元素类型: Map.Entry

(2)初始容量:16

(3)扩容为原来的2倍

(4)那么 HashMap 是如何决定某个映射关系存在哪个桶的呢?
因为hash code是一个整数,而数组的长度也是一个整数,有两种思路:
①hash code值 % table.length会得到一个[0,table.length-1]范围的值,正好是下标范围,但是用%运算,不能保证均匀存放,可能会导致某些table[index]桶中的元素太多,而另一些太少,因此不合适。
②hash code值 & (table.length-1),因为table.length是2的幂次方,因此table.length-1是一个二进制低位全是1的数,所以&操作完,也会得到一个[0,table.length-1]范围的值。


3、HashMap 中的散列函数 hash()
JDK1.7和JDK1.8关于hash()的实现代码不一样,但是不管怎么样都是为了提高hash code值与 (table.length-1)的按位与完的结果,尽量的均匀分布。

这里用 JDK1.8 的实例分析一下:

思考:那么,JDK1.8为什么要保留高16位呢?
因为一个HashMap的table数组一般不会特别大,至少在不断扩容之前,那么table.length-1的大部分高位都是0,直接用hashCode和table.length-1进行&运算的话,就会导致总是只有最低的几位是有效的,那么就算你的hashCode()实现的再好也难以避免发生碰撞,这时保留高16位的意义就体现出来了。它对hashcode的低位添加了随机性并且混合了高位的部分特征,显著减少了碰撞冲突的发生。
4、如何解决冲突?
虽然从设计hashCode()到上面HashMap的hash()函数,都尽量减少冲突,但是仍然存在两个不同的对象返回的hashCode值相同,或者hashCode值就算不同,通过hash()函数计算后,得到的index也会存在大量的相同,因此key分布完全均匀的情况是不存在的。那么发生碰撞冲突时怎么办?
JDK1.8之间使用:数组+链表的结构。
JDK1.8之后使用:数组+链表/红黑树的结构。


5、JDK1.7里HashMap 中几个常量与变量是什么?
(1)默认数组容量

(2)默认加载因子

思考: loadFactor 设置为 0.1 与 0.9 有什么区别?
当 loadFactor 为 0.1 时,扩容太频繁
当 loadFactor 为 0.9时,会导致 table[index] 下面的链表会很长,查询速度会降低。
(3)加载因子

(4)阈值(临界值)

6、JDK 1.6 中HashMap 的构造方法是怎么样的?
图1
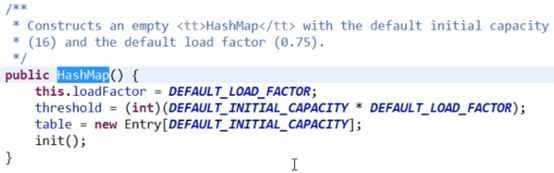
图2

可以看出 JDK1.6 中 table 数组初始化为了一个长度为 16 的空数组,默认加载因子为0.75,阈值为12。
6、JDK 1.7 中的 HashMap 的构造方法是怎么样的?
图1

图2
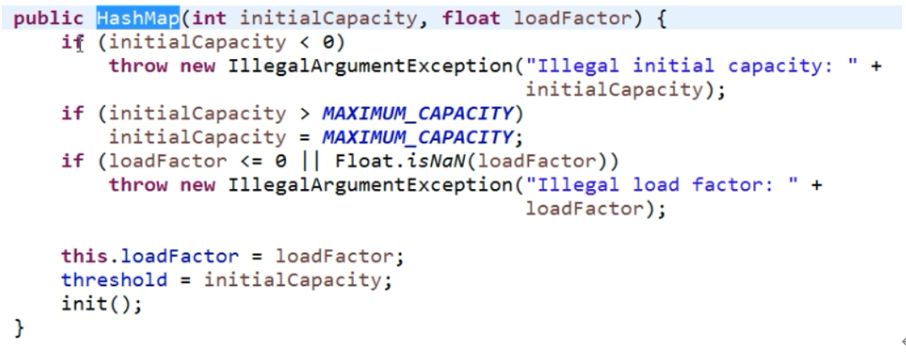
图3
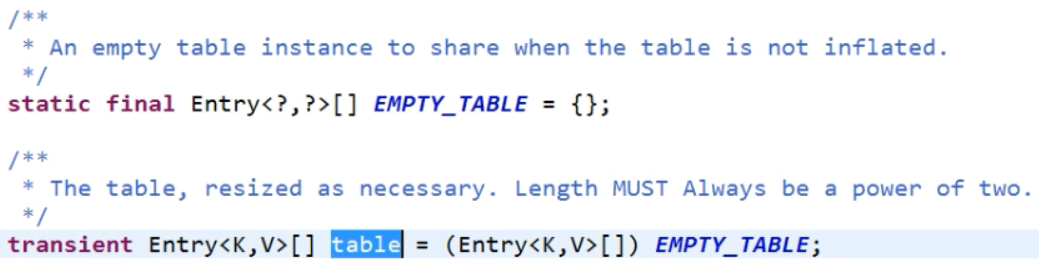
可以从无参构造中看出,调用了有参的构造,但是有参的构造方法中并没有做什么,但是从上面的图三可以看出 table 数组初始化为了一个长度为0的长度为0的数组。
7、JDK 1.8 中的 HashMap 的构造方法
8、JDK 1.7 中的 put 方法
源码分析:


执行步骤:
(1)先判断table是否为空数组,如果是,先初始化长度为16的Entry 类型的数组,并且把threshold计算为12;
这里如果你手动指定了数组的capacity,那么如果这个capacity不是2的n次方,会自动纠正为2的n次方;
(2)如果key是null,特殊对待,key为null的映射关系的hash值为0,index也为0;
(3)key 不是 null,那么先计算hash(key)获得 hash 值
(4)再通过处理过的hash值&(table.length-1)计算index,决定是在table[index],index在[0,table.length-1]范围内;
(5)判断table[index]桶下是否存在某个Entry的key与新的key的“相同”(hash值相同并且(满足key的地址相同或key的equals返回true)),如果是,用新的value替换原来的value;
(6)如果不存在,判断是否满足size达到阈值(threshold)并且table[index]不是null,如果是,先扩容;扩容会导致原来table中的所有元素都会重新计算位置,并调整存储位置;
(7)添加一个新的Entry对象至table[index](注意,这个index也是重新计算过的)中,并且把当前table[index]下的所有元素都连接到新的Entry的next下。
(8)size++,元素个数增加
思考:
1、为什么要把数组的长度纠正为2的n次方?
① 后面算index = hash & table.length-1,这样才能保证[0,table.length-1]范围内
② 2的次方,根据它的散列算法,可以保证比较均匀的分散在它的数组的各个位置
2、扩容的条件是什么?
① size达到阈值threshold
② table[index]下面已经有映射关系,即不为空
9、JDK 1.8 中常量与变量
(1)DEFAULT_INITIAL_CAPACITY:默认的初始容量 16
(2)MAXIMUM_CAPACITY:最大容量 1 << 30
(3)static final float DEFAULT_LOAD_FACTOR = 0.75:默认加载因子 0.75
(4)static final int TREEIFY_THRESHOLD = 8; 默认树化阈值8,该阈值的作用是判断是否需要树化,树化的目的是为了提高查询效率;当某个链表的结点个数达到这个值时,可能会导致树化
(5)static final int MIN_TREEIFY_CAPACITY = 64;最小树化容量64,当某个链表的结点个数达到8时,还要检查table的长度是否达到64,如果没有达到,先扩容解决冲突问题
(6)static final int UNTREEIFY_THRESHOLD = 6;默认反树化阈值6,当删除了结点时,如果某棵红黑树的结点个数已经低于该值时,会把树重新变成链表,目的是减少复杂度
(7)Node<K,V>[] table:数组
(8)int size:记录有效映射关系的对数,也是Entry对象的个数
(9)int threshold:阈值,当size达到阈值时,考虑扩容
(10)double loadFactor:加载因子,影响扩容的频率
10、JDK 1.8 的 put 方法
11、
12、
最新文章
- 电脑控制Android设备的软件——Total Control
- 通过OnResultExecuted设置返回内容为JSONP
- [BZOJ1146][CTSC2008]网络管理Network
- T3500通过PXE克隆报“Unable to Control A20 Line XMS Driver not installed”
- Octopus系列之数据上传格式要求说明
- MyEclipse + Tomcat 热部署问题
- Android无限循环轮播广告位Banner
- 在AngularJS中学习javascript的new function意义及this作用域的生成过程
- Linux安装sonarQube
- cmstop框架中的js设计content.js
- 【Scala】Scala之Traits
- MongDB PHP7
- Go-技篇第一 技巧杂烩
- 从壹开始前后端 [vue后台] 之二 || 完美实现 JWT 滑动授权刷新
- Manjaro下带供电的USB Hub提示error -71
- Intellij实用技巧
- html页面出现&#65279,影响布局
- python生成指定文件夹目录树
- SharePoint 2013怎样创建Wiki库
- C标准库函数--文件IO操作函数。