28. ClustrixDB 分布式架构/评估模型
本节描述如何在数据库中计算查询。在ClustrixDB中,我们跨节点切片数据,然后将查询发送到数据。这是数据库的基本原则之一,它允许随着添加更多节点而几乎线性地扩展。
有关如何分布数据的概念,请参阅数据分布,因为本页假定您理解这些概念。需要记住的主要概念是,表和索引是跨节点划分的,并且每个表和索引都有自己的分布,这使我们能够在给定的主列下精确地知道数据的位置。
并行查询求值(通过示例)
ClustrixDB对简单查询使用并行查询求值,对分析查询(类似于柱状存储)使用大规模并行处理(MPP)。
最好看一些示例来理解查询求值以及为什么查询(几乎)是使用ClustrixDB线性扩展的。让我们从一个SQL模式开始,并通过一些示例进行讨论。
sql> CREATE TABLE bundler (
id INT default NULL auto_increment,
name char() default NULL,
PRIMARY KEY (id)
); sql> CREATE TABLE donation (
id INT default NULL auto_increment,
bundler_id INT,
amount DOUBLE,
PRIMARY KEY (id),
KEY bundler_key (bundler_id, amount)
);
现在,让我们看看这种情况下的数据分布。我们有三种表达方式:
- _id_primary_bundler
- _id_primary_donation
- _bundler_key_donation
前两个是基于它们的id字段分布的。最后一个是基于bundler_id的。请注意,由于这些是散列分布的,所以具有相同键值的所有行都指向相同的节点。
扩展简单查询
在这里,我们将简单的查询定义为点选择和插入。让我们考虑一个简单的读(一个简单的写遵循相同的路径):
sql> SELECT id, amount FROM donation WHERE id = ;
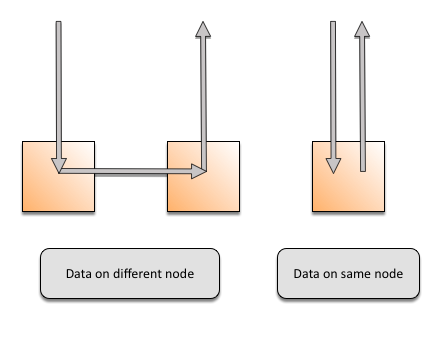
数据将从排序副本中读取。它可以驻留在同一个节点上,也可以只需要一个跳转。下图展示了这两种情况。随着数据集大小和节点数量的增加,一个查询所需的跳数(0或1)不会改变。这允许读写的线性可伸缩性。另外,如果有两个或多个副本(通常是这种情况),则至少有一个写操作跃点(因为两个副本不能驻留在同一个节点上)。
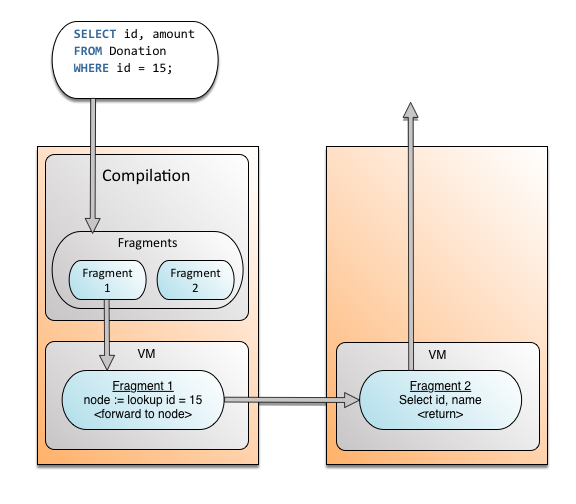
查询编译片段
现在,让我们再深入一点了解理解查询分裂是如何工作的。在编译过程中查询分解成了碎片,类似于函数的集合。更多信息,请参见查询计划和优化器。这里我们将关注逻辑模型。下面,你可以看到一个简单查询编译成两个函数。第一个函数查找价值所在和第二个函数读取正确的值从容器中,节点和切片并返回给用户(并发等等的细节已经排除了清晰)。
扩展连接
连接需要更多的数据移动。然而,ClustrixDB能够实现最小的数据移动,因为:
- 每个表示(表或索引)都有自己的分布,因此我们查找下一个节点/片,删除广播。
- 不存在协调数据移动的中心节点。数据移动到下一个需要它的节点。在给定数据分布的情况下,这将跳数减少到最小。
让我们来看一个查询,它获取特定bundler收集的所有捐款的名称和金额,id = 15。
sql> SELECT name, amount from bundler b JOIN donation d on b.id = d.bundler_id WHERE b.id = ;
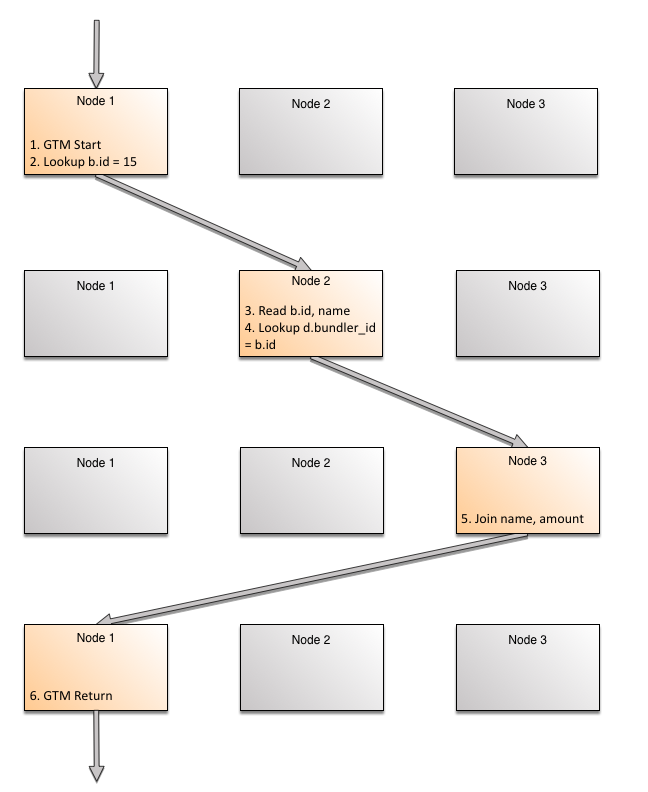
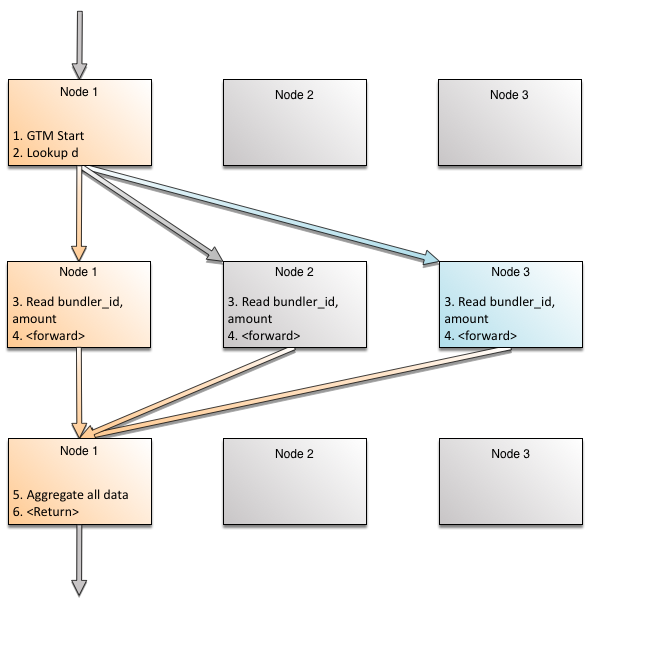
SQL优化器将查看相关的统计数据,包括分位数、热点列表等,以确定计划。查询的并发控制由起始节点(具有会话)管理,该节点称为该查询的GTM(全局事务管理器)节点。它与在每个节点上运行的本地事务管理器进行协调。有关详细信息,请参见并发控制。所选方案的逻辑步骤如下:
- Start on GTM node
- Lookup nodes/slices where _id_primary_bundler has (b.id = 15) and forward to that node
- Read b.id, name from the representation _id_primary_bundler
- Lookup nodes/slice where _bundler_key_donation has (d.bundler_id = b.id = 15) and forward to that node
- Join the rows and foward to GTM node
- Return to user from GTM node
这里的关键是在第四步。对于连接,当读取第一行,有一个特定的连接列的值。使用这个特定值,下一个节点(这可能是本身)可以精确查找。
让我们看看这个图形。每个返回的行在系统中最多经过三次跳转。随着返回的行数的增加,每一行不工作。行跨节点处理和行相同的节点上运行不同的片段,使用并发使用多核并行性。排在同一节点以及它们之间相同的片段使用管道并行性。
假设有三个节点。为了清晰起见,这三个节点被多次绘制,以描述查询求值的每个阶段。
现在我们已经看到了单行的路径,假设我们没有b.id = 15。连接现在将在多台机器上并行运行,因为b.id出现在多个节点上。让我们看看另一个视图,这一次节点只绘制一次,步骤按时间顺序向下流动。请注意,虽然join的转发显示行可以转到任何节点,但这是在整个行集的上下文中进行的。单个行通常只转发给一个节点。
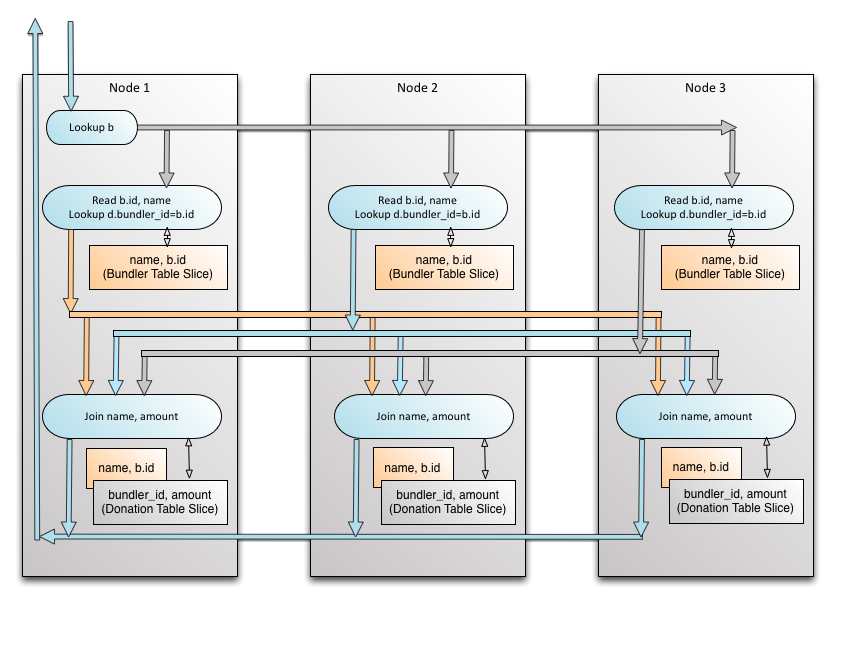
使用大规模并行处理进行连接(ClustrixDB)
对于单个行,我们可以看到ClustrixDB如何使用单播来精确地转发它。现在,让我们缩小范围,看看在系统级别上大型连接意味着什么,以及集群中转发了多少行。每个节点只获得它需要的行。接收节点上的颜色与箭头上的颜色相匹配——这表示行正确地流向节点,节点将为成功连接找到匹配的数据。
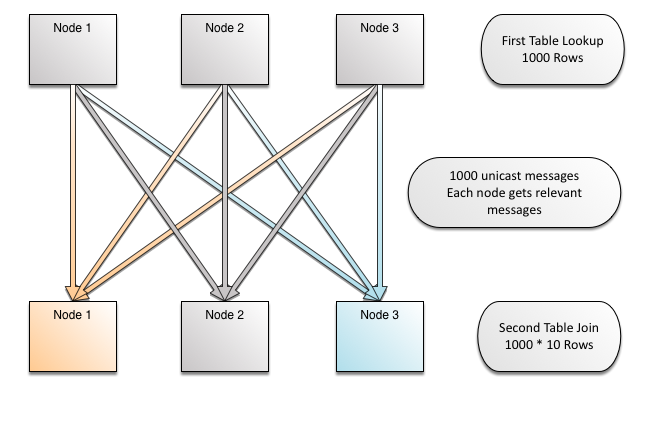
加入广播(竞争)
我们的竞争对手都没有独立的索引分布。所有类似切分的方法都根据主键分配索引。因此,给定列上的索引(如前面的示例中的bundler_id),系统不知道键的去向,因为分发是基于doni .id完成的。这导致广播,因此N路连接不是线性伸缩的。请注意,在图像中,广播是由获取其颜色的行(箭头)的节点显示的,这些行(箭头)将为连接查找匹配的数据,而其他颜色的节点将在查找中显示不匹配的数据。Oracle和MySql集群做这样的广播。
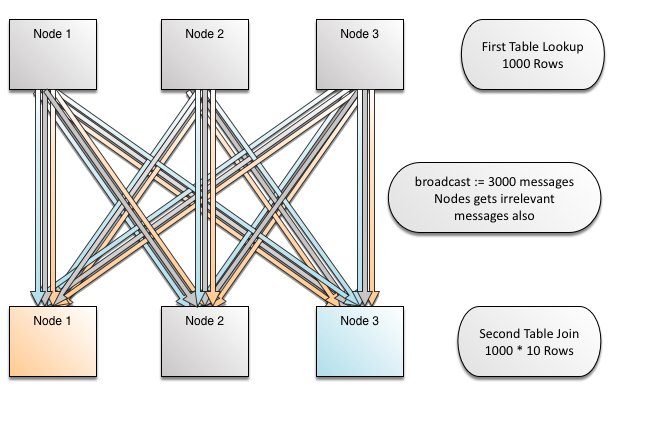
使用单个查询节点进行连接(竞争)
ClustrixDB使用大规模并行处理(MPP)来利用跨节点的多个核心,使单个查询运行得更快。一些竞争产品使用单个节点来评估查询,这导致随着数据量的增加,查询的速度提高有限。这包括Oracle RAC和NuoDB,它们都不能跨多个节点使用核心来计算连接。这里的所有数据都需要流到计算单个查询的单个节点。
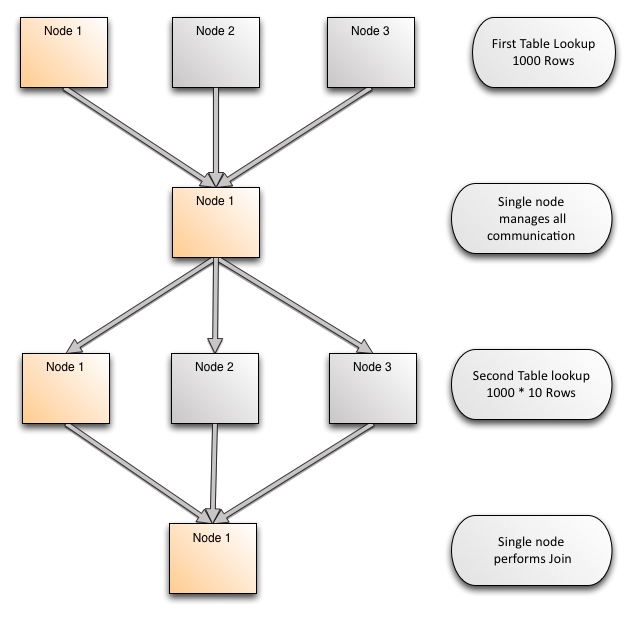
大多数竞争对手无法匹配ClustrixDB提供的连接的线性扩展。这是因为它们要么在所有情况下都进行广播(除了联接在主键上时),要么只有单个节点执行单个查询(其他节点通过主键发送数据)。这使得ClustrixDB比竞争对手具有更好的伸缩性,使它在事务分析空间(OLAP)中具有独特的价值主张。
扩展聚合
扩展聚合需要在多个节点上并行聚合。这样就剩下最后的工作了,将每个节点的部分聚合合并为一个小得多的数据量的简单任务。
此查询用于生成bundler_id的捐款总数报告。在这里,与bundlers表连接以及获取名称是有意义的,但是我们已经了解了连接是如何工作的—所以让我们保持示例的简单性。
sql> SELECT id, SUM(amount) FROM donation d GROUP BY by bundler_id;
分布式聚集(ClustrixDB)
在这里,捐款表分布在donation.id字段。如果按此字段分组,则跨节点的数据不会共享相同的分组键。这样就不需要重新聚合。但是在本例中,我们展示了相同的值可能在不同节点上的情况(让我们忽略可以使用索引)。以下是它如何在最普遍的情况下工作:
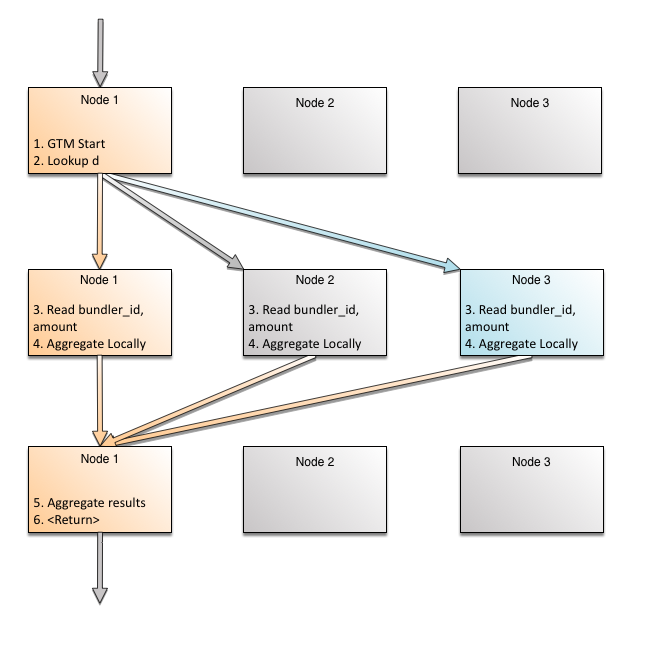
这里,我们看到为了聚合,数据移动和顺序工作被最小化了。当基于统计量的数据约简效果良好时,我们选择分布式聚合。
没有重新聚合的聚合
请注意,我们需要在GTM节点上聚合本地聚合的结果,只有在来自不同节点的值可能重叠的情况下才需要这样做。对于涉及连接的复杂查询,通常是这种情况。让我们来看一个更简单的查询:
sql> SELECT DISTINCT bundler_id FROM donation;
在本例中,有一个名为_bundler_key_donor的备用键(或索引),它由bundler_id分发。这有两个含义:
- bundler_id values on each node are unique
- bundler_id values on each node are sorted
要有效地实现这个ClustrixDB,只需分布式聚合一次保持一行。因此,如果节点读取bundler_id = 5,它将存储该数据并将其转发给GTM节点。然后它将丢弃所有随后的值= 5,直到它看到一个新值6。在GTM节点上,不需要重新聚合,因为每个节点的值都是惟一的,它只是合并流。
单个节点聚合(竞争)
大多数主数据库没有大规模并行处理,因此所有聚合都发生在接收查询的单个节点上。这就是Oracle、NuoDB和MongoDB的工作方式。这将移动更多的数据,无法使用多台机器的资源,而且伸缩性不好。
讨论
让我们复习一下分布式计算和查询并行处理中涉及的概念。
查询的生命周期
用户查询分布在ClustrixDB中的各个节点上。以下是如何处理查询:
- 查询与它到达的节点上的会话相关联,该节点为它编排并发控制。
- 解析之后,查询将通过查询优化器和规划器,根据统计信息为其选择最佳计划。
- 然后由编译器编译计划,编译器将计划分解成更小的查询片段并运行代码优化。
- 编译后的查询片段以分布式方式跨节点运行,结果返回到查询开始的节点并返回给用户。
使用管道和并发并行
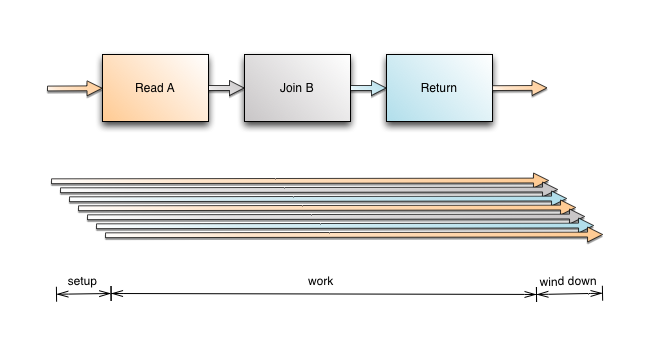
ClustrixDB同时使用并行并行和流水线并行来对查询进行大规模并行计算。像点选择和插入这样的简单查询通常只使用节点上的单个核心进行计算。随着添加的节点越来越多,可用的内核和内存也越来越多,这使得ClustrixDB能够并发地处理更多的简单查询。
更复杂的分析查询,如涉及连接和聚合的查询,利用管道和并发并行性,使用来自多个节点的核心和单个节点上的多个核心来快速评估查询。请看下面的示例,查询如何扩展以更好地理解并行性。
并发并行性是指片之间的并行性,每个片可能位于一个或多个节点上。
管道并行发生在单个查询的行之间。分析查询中的每一行可能涉及一个双向连接的三个跃点。添加到一行的延迟是三个跃点的延迟,所以设置时间可以忽略不计。另一个可能的限制是带宽。如前所述,ClustrixDB对于每个表和索引都有独立的分布,因此我们只将行转发到正确的节点。
如何在分布式系统中扩展评估?
这个表格总结了一个可扩展的分布式数据库的不同元素,以及如何建立一个:
|
|
Throughput
|
Speedup
|
Concurrent Writes
|
|---|---|---|---|
| Logical Requirement |
Work increases linearly with
|
Analytic query speed increases linearly with
|
Concurrency Overhead does not increase with
|
| System Characteristic |
For evaluation of one query
|
For evaluation of one query
|
For evaluation of one query
|
| Why Systems Fail |
Many databases use sharding-like approach to slice their data
|
Many databases do not use Massively Parallel Processing
|
Many databases used Shared Data architecture where
|
| Examples of Limited Design |
Colocation of indexes leading to broadcasts
|
Single Node Query Processing leading to limited query speedup
|
Shared data leading to ping-pong effect on hot data
Coarse-grained locking leading to limited write concurrency
|
| Why ClustrixDB Shines |
ClustrixDB has
|
ClustrixDB has
|
ClustrixDB has
|
最新文章
- 用RMAN备份EBS数据库的脚本
- centos6.5安装oracle11g_2
- MSP是什么?
- .NET Core HtmlAgilityPack HTML解析利器
- 观察者模式及Java实现例子
- [leetcode] Contains Duplicate II
- lintcode:排颜色 II
- 【USACO 2.2.3】循环数
- JAVA中运用数组的四种排序方法
- ASP.NET MVC 学习之路-3
- C#连接sqlserver数据库
- Redis构建分布式锁
- Ubuntu 增加swap空间大小
- iRate---一个跳转AppStore评分弹窗
- Java中excel转换为jpg/png图片 采用aspose-cells-18.6.jar
- 4A - 排序
- protobuf-c的学习总结
- Linux+Redis实战教程_day01_Linux介绍与安装
- C# XtraGrid的行指示器(RowIndicator)行号以及图标设置
- 【洛谷 P3191】 [HNOI2007]紧急疏散EVACUATE(二分答案,最大流)