postgresql大数据查询加索引和不加索引耗时总结
1、创建测试表
CREATE TABLE big_data
(
id character varying(50) NOT NULL,
name character varying(50),
datetime timestamp with time zone,
CONSTRAINT big_data_pkey PRIMARY KEY (id)
)
WITH (
OIDS=FALSE
);
ALTER TABLE big_data
OWNER TO postgres;
2、创建插入数据函数
CREATE OR REPLACE FUNCTION insert_bigdata()
RETURNS text AS
$BODY$
declare ii integer;
declare jj integer;
begin
ii = 1;
jj = 1;
FOR ii IN 1..10 LOOP
FOR jj IN 1..10000 LOOP
INSERT INTO big_data values(uuid_generate_v4(), 'lisi'||jj, now());
END LOOP;
END LOOP;
RETURN 'success';
end;
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100;
ALTER FUNCTION insert_bigdata()
OWNER TO postgres;
3、插入一千万条数据(修改函数中的循环次数,多执行几次,插入需要的数据)
select insert_bigdata();
4、给name字段不加索引和加索引分别统计执行时间
查询结果10条记录
select * from big_data where name='lisi10';
查询结果100条记录
select * from big_data where name='lisi100';
查询结果1000条记录
select * from big_data where name='lisi1000';
查询结果10000条记录
select * from big_data where name='lisi10000';
查询结果100000条记录
select * from big_data where name='lisi100000';
耗时统计表(单位/毫秒)

耗时统计图
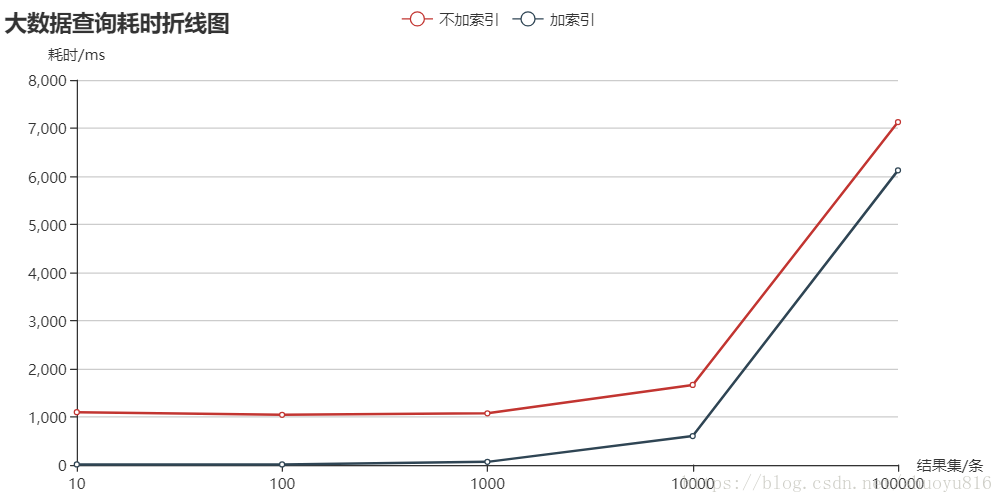
5、结果总结
在查询结果小于1000条记录时,加索引会大幅度提高查询效率。
在查询结果大于1000条记录时,加索引对查询效率的提升逐渐减小,尤其是超过10000条时,使用索引后的查询时间也比较长。
当前结果仅适用于创建的big_data这张数据表(如果数据表中字段比较多,数据量比较大,会在更小的查询结果记录数出现加索引查询效率提升不明显的问题)。
————————————————
版权声明:本文为CSDN博主「朔语」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/shuoyu816/article/details/82793968
最新文章
- ProxyPattern
- 使用JavaScript实现复选框全选与取消的功能
- RabbitMQ3.6.3集群搭建+HAProxy1.6做负载均衡
- UILabel顶端对齐
- NSString与奇怪的retainCount
- POJ 2155 Matrix
- mysql自动化安装
- 【HTML5】表单元素
- nodejs 保存 payload 发送过来的文件
- http.request的请求
- 【Docker】 Swarm简单介绍
- 抽象,接口和Object类
- CodeBlocks(17.12) 代码调试基础方法&快捷方式
- react component onClick 函数带参数
- 云栖大会day1 下午
- 20.react库 入门
- js的简单介绍
- 多核CPU配合负载均衡可以这样用,为老板省点钱
- 性能监控(2)–linux下的vmstat命令
- php的explode()和implode()方法
热门文章
- ceph 接入OpenStack
- Django异常 - ImportError: No module named django.core.management
- 关于在centos下安装python3.7.0以上版本时报错ModuleNotFoundError: No module named '_ctypes'的解决办法
- 六、MySQL系列之数据备份(六)
- ipsec][strongswan] ipsec SA创建失败后的错误处理分析
- springboot学习笔记(二)—— springboot的启动模式设置
- 个性化排序算法实践(四)——GBDT+LR
- idea的基础设置
- 做vue项目时,收集的一些有意思的功能
- Linux PAM 之cracklib模块