概率检索模型:BIM+BM25+BM25F
1. 概率排序原理
以往的向量空间模型是将query和文档使用向量表示然后计算其内容相似性来进行相关性估计的,而概率检索模型是一种直接对用户需求进行相关性的建模方法,一个query进来,将所有的文档分为两类 -- 相关文档、不相关文档,这样就转为了一个相关性的分类问题。
对于某个文档D来说,P(R|D)表示该文档数据相关文档的概率,则P(NR|D)表示该文档属于不相关文档的概率,如果query属于相关文档的概率大于不相关文档P(R|D)>P(NR|D),则认为这个文档是与用户查询相关相关的。
现在使用贝叶斯公式将其转一下:
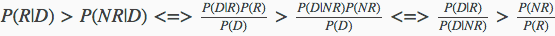
在搜索排序过程中不需要真正的分类,只需要保证相关性由高到底排序即可,所以只需要P(D|R) / P(D|NR)降序即可,
这样就最终转为计算P(D|R),P(D|NR)的值即可。
2. 二元独立模型(BIM)
为了能够使得上述两个计算因子可行,二元独立模型做出了两个假设:
1. 二元假设
类似于布尔模型中的文档表示方法,一篇文档在由特征(或者单词)进行表示的时候,以特征(或者单词)出现和不出现两种情况来表示,不考虑词频等其他因素。
2. 词汇独立性假设
指文档里出现的单词之间没有任何关联,任意一个单词在文档的分布概率不依赖于其他单词是否出现。因为词汇之间没有关联,所以可以将文档概率转换为单词概率的乘积。
上述提到的文档D表示为{1,0,1,0,1},用pi来表示第i个单词在相关文档出现的概率,则在已知相关文档集合的情况下,观察到D的概率为:
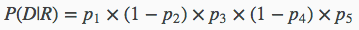
第1,3,5表示这个单词在D中出现,所以其贡献概率为pi,而第2,4这两个单词并没有在D中出现,所以其贡献的概率为1−pi。
同理在不相关文档中观察到的概率为:
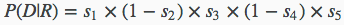
最终得到的相关性概率估算为:
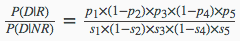
现在将其推广之后可以有通用的式子:
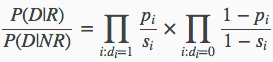
di=1表示在文档中出现的单词,di=0表示没在文档中出现的单词。
在这里进一步对上述公式进行等价变换之后有:
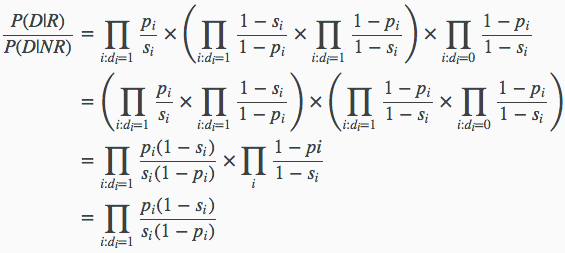
其中上面式子第三步的第二部分 表示各个单词在所有文档中出现的概率,所以这个式子的值和具体文档并没有什么关系,在排序中不起作用,才可以简化到第4步。
表示各个单词在所有文档中出现的概率,所以这个式子的值和具体文档并没有什么关系,在排序中不起作用,才可以简化到第4步。
为了方便计算,将上述连乘公式取log:
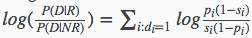
有了上述最终可计算的式子之后,我们就只需要统计文档D中的各个单词在相关文档/不相关文档中出现的概率即可:

上面的表格表示各个单词在文档集合中的相关文档/不相关文档出现数量,同时为了避免log(0)出现,加上平滑之后可以计算得到:

则最终可以得到如下公式:
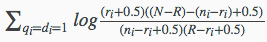
其代表的含义是:对于同时出现在用户查询Q和文档D中的单词,累加每个单词的估值,其和就是文档D和查询的相关性度量。
在不确定哪些文档是相关的,哪些文档是不相关的的时候,可以给公式的估算因子直接赋予固定值,则该公式将会退化为IDF因子。
3. BM25模型
BIM模型基于二元独立假设推导而出,即对于单词特征,只考虑是否在文档中出现过,而不考虑单词的权值。BM25模型在BIM模型的基础上,考虑了单词在查询中的权值及单词在文档中的权值,拟合出综合上述考虑因素的公式,并通过实验引入一些经验参数。
BM25模型的具体计算公式如下所示:
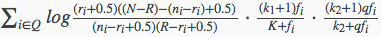
上面的式子中:
- 第1个组成部分即为上一小节的二元独立模型BIM计算得分,如果赋予一些默认值的话,等价于IDF因子的作用。
- 第2个组成部分是查询词在文档D中的权值,其中fi代表了单词在文档D中的词频,K因子代表了对文档长度的考虑,其计算公式为
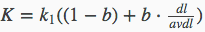
- k1为经验参数,作用是对查询词在文档中的词频进行调节。如果设为0,则第2部分整体变为1,即不考虑词频的因素,退化成了BIM模型;如果设为较大值,则第2部分计算因子基本与词频fi保持线性增长,即放大了词频的权值。根据经验,一般讲k1设置为1.2。
- b为调节因子,将b设为0时,文档长度因素将不起作用,经验表明一般b=0.75。
- dl代表当前文档D的长度。
- avdl代表文档集合中所有文档的平均长度。
- 第3个组成部分是查询词自身的权值,qfi表示查询词在用户查询中的词频,如果查询较短小的话,这个值一般是1,k2也为调节因子,是针对查询中的词频进行调节,因为查询往往很短,所以不同查询词的词频都很小,词频之间差异不大,为了放大这部分的差异,k2一般取值为
0~1000。
综合来看,BM25模型计算公式其实融合了4个考虑因素:IDF因子,文档长度因子,文档词频,和查询词频。并对3个自由调节因子(k1,k2,b)进行权值的调整。
例子:
假设当前以“乔布斯 IPAD2”这个查询词为例,来计算在某文档D中BM25相关性的值,由于不知道文档集中相关与不相关的分类,所以这里直接将相关文档个数r置为0,则将得到的BIM因子为:
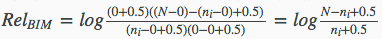
其他数值假定如下:
- 文档的集合总数:N=100000
- 包含
乔布斯的文档个数为:n乔布斯=1000 - 包含
IPAD2的文档个数为:nIPAD2=100 - 文档D中出现
乔布斯的词频为:f乔布斯=8 - 文档DD中出现
IPAD2的词频为:fIPAD2=8 - 查询词频均为:qfi=1
- 调节因子k1=1.2k
- 调节因子k2=200
- 调节因子b=0.75
- 设文档D的长度为平均长度的1.5倍(dl/avdl=1.5),即K=1.2×(0.25+0.75×1.5)=1.65
则最终可以计算到的BM25结果为:
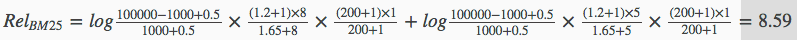
每个文档按上述公式计算得到相关性排序即可。
4. BM25F模型
在BM25模型中,文档被当做一个整体进行进行词频的统计,而忽视了不同区域的重要性,BM25F模型正是抓住了这点进行了相应的改进。
BM25F模型在计算相关性时候,会对文档分割成不同的域来进行加权统计,非常适用于网页搜索,因为在一个网页有标题信息、meta信息、页面内容信息等,而标题信息无疑是最重要的,其次是meta信息,最后才是网页内容,BM25F在计算相关性的,会将网页分为不用的区域,在各个区域分别统计自己的词频。
所以BM25F模型的计算公式为:
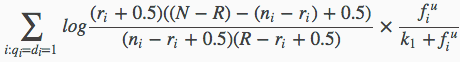
BM25F的第1部分还是BIM的值。
其中与BM25主要的差别体现在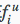 因子上,它是单词i在各个区域不同的得分,计算公式如下:
因子上,它是单词i在各个区域不同的得分,计算公式如下:
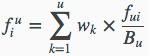
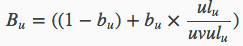
上面的公式表示:
- 文档D来个不同的u个域
- 各个域对应的权重为Wk
- fui为第i个单词在各个域中的 fui / Bu 的加权和
- fui表示词频
- Bu表示各个域的长度情况
- ulu为实际域的实际长度,uvulu表示域的平均长度
- bu则为各个域长度的调节因子
最新文章
- 全面解析sizeof(上) 分类: C/C++ StudyNotes 2015-06-15 10:18 188人阅读 评论(0) 收藏
- GNOME on Arch Linux
- rabbitmq_hearbeat
- BZOJ4584 : [Apio2016]赛艇
- 移动前端头部标签(HTML5 head meta)
- jsp之jstl标签
- 使用C语言实现二维,三维绘图算法(1)-透视投影
- Android中通过访问本地相册或者相机设置用户头像
- 使用AlertDialog创建对话框的大致步骤
- sqllog 8.32 注册码
- Javascript: 截取字符串多出来并用省略号[...]显示
- Eat Candy(暴力,水)
- OpenSSL “心脏滴血”漏洞
- 本地存储 cookie,session,localstorage( 一)基本概念及原生API
- redis7--hash set的操作
- Linux的基本命令(CentOS)
- Get Form type using javascript in CRM 2011
- 如何在sublime安装ctags函数追踪插件
- Python编程Day7——字符编码、字符与字节、文件操作
- python里面 循环明细对比 相同人员明细,生成同一订单里面
热门文章
- JavaScript—当前时间
- python WEB UI自动化在日期框中动态输入当前日期
- fis前端开发框架
- vim上下左右键输出A B
- 服务端渲染(ssr)初了解
- postgresql----网络地址类型和函数
- 托管调试助手 "DisconnectedContext":“上下文 0xf20540 已断开连接... 请确保在应用程序全部完成 RuntimeCallableWrapper (表示其内部的 COM 组件)之前,所有 COM 上下文/单元/线程都保持活动状态并可用于上下文转换
- TFS二次开发05——下载文件(DownloadFile)
- Java-06-动手动脑
- YARN架构设计详解