Python学习---网页爬虫[下载图片]
2024-08-25 23:41:37
爬虫学习--下载图片
1.主要用到了urllib和re库
2.利用urllib.urlopen()函数获得页面源代码
3.利用正则匹配图片类型,当然正则越准确,下载的越多
4.利用urllib.urlretrieve()下载图片,并且可以重新命名,利用%S
5.应该是运营商有所限制,所以未能下载全部的图片,不过还是OK的
URL分析:
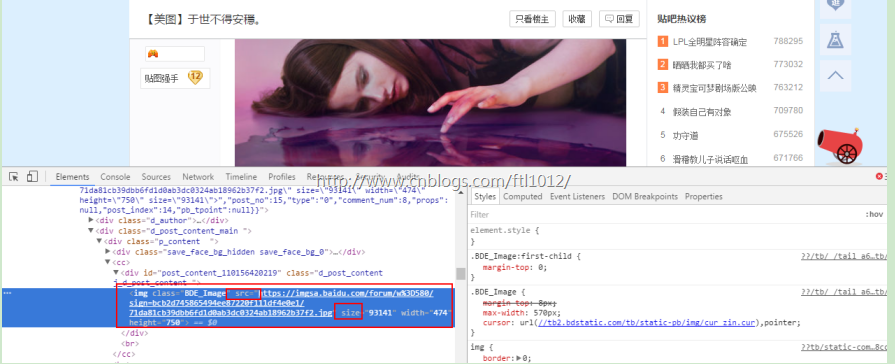
源码:
#coding=utf-8
import re
import urllib
def getHtml(url):
page=urllib.urlopen(url)
html=page.read();
return html
def getImage(html):
reg=r'src="(.*?\.jpg)" size'
imgre=re.compile(reg)
imgeList =re.findall(imgre,html)
x=0
for image in imgeList:
urllib.urlretrieve(image,'%s_hhh.jpg' % x)
x+=1
html=getHtml("https://tieba.baidu.com/p/5256641773")
getImage(html)
最新文章
- 最简单的轮播广告(原生JS)
- Java语言中的volatile变量
- 【UVA 1451】Average
- EF Code First DataAnnotations
- Fibonacci sequence 求余数
- 无限大整数相加算法的C语言源代码
- 通过jquery获取后台传过来的值进行全选
- 讲讲金融业务(一)--自助结算终端POS
- WinForm - 两个窗体之间的方法调用
- Boot Sector - Hello world
- JavaScript总体的介绍【JavaScript介绍、定义函数方式、对象类型、变量类型】
- jquery mobile小案例
- 使用Travis CI自动部署博客到github pages和coding pages
- Chart Parser 中 Earley's 算法的应用
- scrapy基础 之 爬虫入门:先用urllib2来跑几个爬虫
- Android Studio 设置字体
- jQuery中click事件多次触发解决方案
- api.execScript
- OA项目实战学习(7)——初始化数据&权限配置显示
- ASP.NET MVC 获取计算机字体