Big Txt File(一)
2024-09-16 14:57:32
对于当今的数据集来说,动不动就上G的大小,市面的软件大多不支持,所以需要自己写一个。
常见的txt文本行形式存储的时候也不过是行数多些而已,可以考虑只观测部分行的方式,基于这个思路可以搞一个大数据的浏览工具。
贴图:
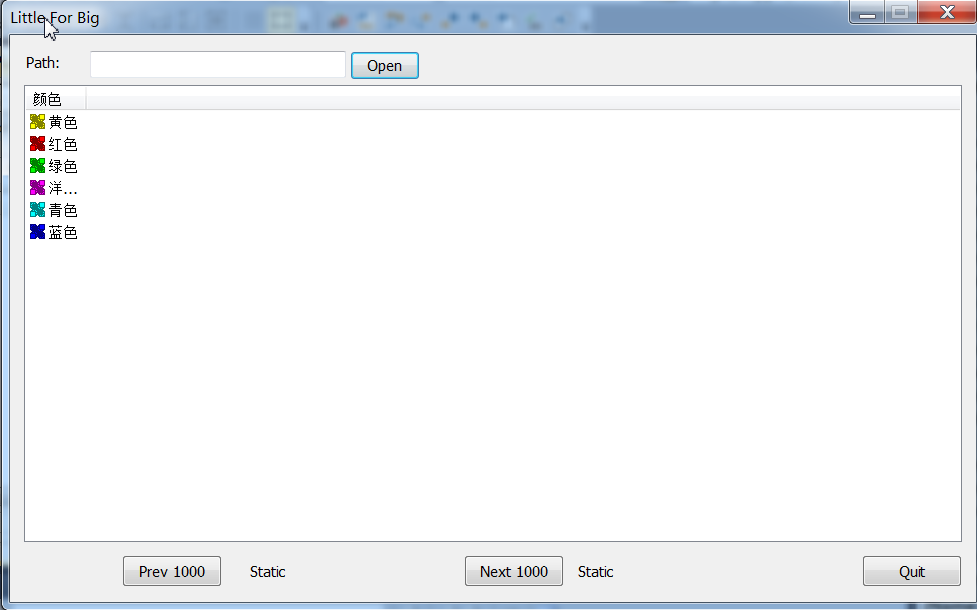
内部的原理很简单,就是先记录下文件的每行的末尾坐标,然后存起来,到需要的时候直接seek到位置然后读取。
这样的思路在z400的工作站10G文件几秒就打开了。
VC做的10G在win7 64位系统下几乎卡死,还未研究。但是1G左右的文件差不多几秒也能打开。
我用的list,如果换成editor的话几乎可以实现文本的处理。
git源码:https://github.com/watergao/A-Little-in-Big-text-file
喜欢的打赏我吧:
支付宝

微信

最新文章
- SQL脚本IN在EF中的应用
- Thinkphp整合最新Ueditor编辑器
- linux之cal命令
- javascript数组去重算法-----2
- Problem E: Product
- Detailed Information for Outputted Files from Somatic Mutation Annotators(annovar 注释文件条目详细解释)
- Sql行列转换参考
- Java中为什么long能自动转换成float类型
- 文本离散表示(一):词袋模型(bag of words)
- 【Python 18】BMR计算器2.0(数值类型转换与while循环)
- STL 中 使用迭代器删除元素的问题
- Android 开发 蓝牙开发
- TCP 的那些事儿(下)(转)
- 配置完php.ini中的扩展库后,重启apache出现错误1067
- 今天我碰到了由于web.xml文件表头信息导致润乾报表启动失败的问题,解决方案如下
- js递归遍历key
- 更改 AWS RDS mysql时区 -摘自网络
- Alpha 冲刺报告(10/10)
- [linux]linux调度策略对io的影响
- [转载][QT][SQL]sql学习记录2_sqlite数据类型