Spider爬虫-get、post请求
1:概念:
爬虫就是通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。
2:python爬虫与其他语言的比较:
(1)php爬虫弊端:多进程多线程支持的不好
(2)java:代码臃肿,重构成本较大
(3)C/c++:不明智的选择,C语言纯面向过程
(4)Python:学习成本低,较多模块,具有框架的支持,Scripy
3:分类(使用场景)
(1)通用爬虫:是搜素引擎中’抓取系统‘的重要组成部分(爬取的是整张页面)。将互联网上页面内容进行抓取下载到服务器本地
扩展:搜素引擎如何抓取互联网的网页
1.门户主动将自己的url提交给搜素引擎公司
2.搜索引擎公司会和DNS服务商进行合作
3.挂靠知名网站的友情链接
(2)聚焦爬虫:根据指定的需求去网上爬去指定的内容
4.robots.txt协议:指定的是门户中哪些数据可以供爬虫程序进行爬取和非爬取。(协议是防君子不防小人)
查看网站后台的robots协议:

5.反爬虫:
门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。
6.反反爬虫:
爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。
get请求,爬取数据实例:
(1):简单的get请求:模拟浏览器发送get请求,在百度上爬取搜索明星名字页面
import requests
#get请求:爬取百度搜素
get_url='http://www.baidu.com/s'
wd=input('输入你要搜素的明星名字:') param={
'ie':'utf-8',
'wd':wd, }
response=requests.get(url=get_url,params=param)
# print(response.text)
data=response.text filename=wd+'.html'
with open(filename,'wt',encoding='utf-8') as f:
f.write(data)
实现的效果如下:
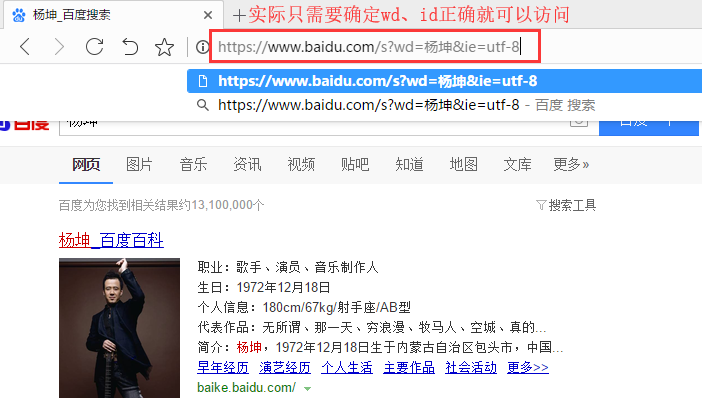
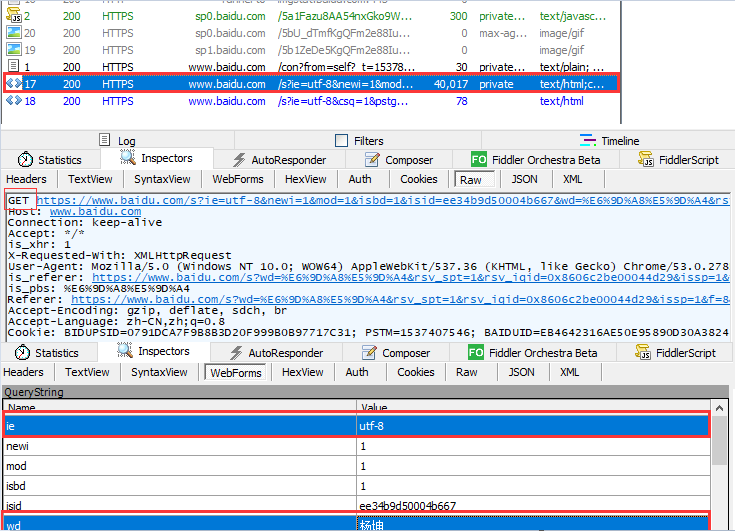
结合fiddler抓包工具图解分析如下:
(2):基于ajax的get请求:获取豆瓣网上的电影排行榜信息
import requests
#指定开始位置和结束位置:start开始的视频 limit:即每页显示的视频数量(默认每页是20个可以自己设定每页显示的数值)
get_url='https://movie.douban.com/j/chart/top_list?type=13&interval_id=100%3A90&action=&start=0&limit=20' param={ 'type':'',
'interval_id':'100:90',
'action':'',
'start':'', #指定开始爬取的开始位置
'limit':'', #默认每页的显示的视频个数 } response=requests.get(url=get_url,params=param)
print(response.text)
要获取的页面信息如下:
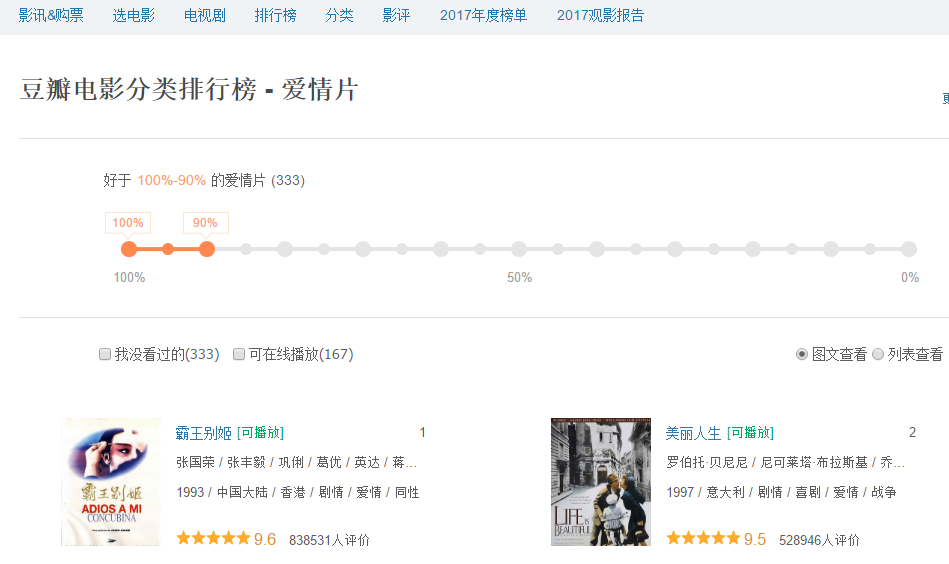
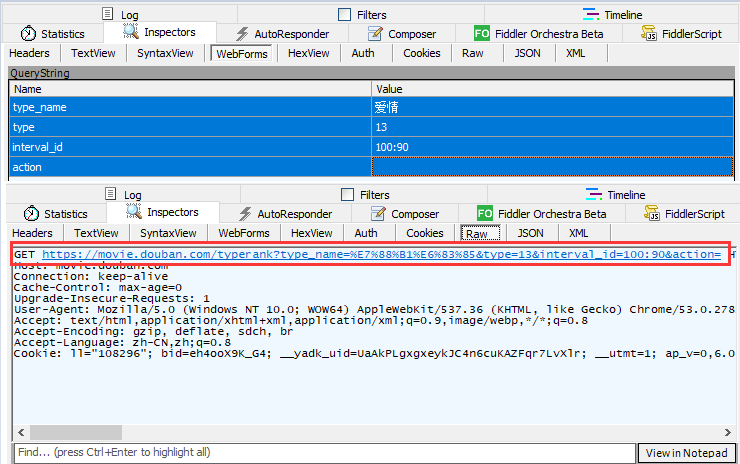
结合抓包工具,分析如下:
结果如下,就能实现获取指定页数指定数量的电影信息:

post请求,爬取数据实例:
(1):普通post请求,爬取百度翻译信息
import requests
#百度翻译:爬取post请求翻译结果 #如下两行代码表示的是忽略证书(SSLError)
import ssl
ssl._create_default_https_context = ssl._create_unverified_context url='https://fanyi.baidu.com/sug' header={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 Safari/537.36', }
data={
'kw':'hi' } response=requests.post(url,data=data,headers=header )
print(response.text)
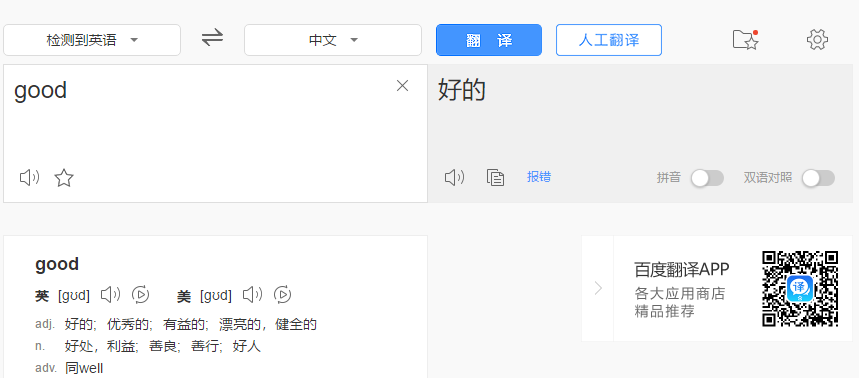
(2):基于ajax的post请求,搜素肯德基的门店信息
网址:http://www.kfc.com.cn/kfccda/storelist/index.aspx
import requests #KFC门店查询
get_url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 Safari/537.36',
} address=input('输入你要查询的城市>>>:')
start_page=int(input('输入开始页>>>:'))
end_page=int(input('输入结束页>>>:')) #for循环拿到每一页的页码数(for..range取值,所以页码数必须为int类型)
for page in range(start_page,end_page+1): data={
'cname':'',
'pid':'',
'keyword':address,
'pageIndex':str(page),
'pageSize':'', #每页显示10条信息 }
#显示每一页的10条门店信息
response=requests.post(url=get_url,data=data,headers=header)
print(response.text)

最新文章
- 生成PDF的新选择-Phantomjs
- poj1679 kruskal
- volley框架 出现at com.android.volley.Request.<init>
- 【转】Android HTTP协议
- 2.2 sikuli中编程运行
- signalR 消息推送
- Babylon.js demo
- Big Event in HDU HDU - 1171
- CSS3笔记3
- apache做反向代理服务器
- JumpServer里的sftp功能报错说明
- [LeetCode] 236. Lowest Common Ancestor of a Binary Tree_ Medium tag: DFS, Divide and conquer
- python 全栈开发,Day135(爬虫系列之第2章-BS和Xpath模块)
- bzoj2330
- Oracle服务无法启动,报:Windows无法启动OracleOraDb10g_home1TNSListener服务,错误 1067:进程意外终止。
- Linux下升级openssl
- linux基础命令---rm
- html css 伪样式
- SIFT算法的教程及源码
- idea基础操作