Hadoop 学习之路(五)—— Hadoop集群环境搭建
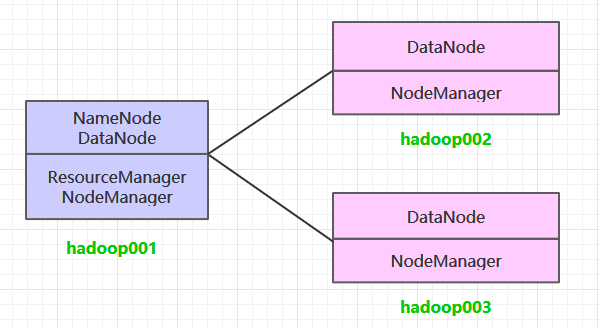
一、集群规划
这里搭建一个3节点的Hadoop集群,其中三台主机均部署DataNode和NodeManager服务,但只有hadoop001上部署NameNode和ResourceManager服务。
二、前置条件
Hadoop的运行依赖JDK,需要预先安装。其安装步骤单独整理至:
三、配置免密登录
3.1 生成密匙
在每台主机上使用ssh-keygen命令生成公钥私钥对:
ssh-keygen
3.2 免密登录
将hadoop001的公钥写到本机和远程机器的~/ .ssh/authorized_key文件中:
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop003
3.3 验证免密登录
ssh hadoop002
ssh hadoop003
四、集群搭建
3.1 下载并解压
下载Hadoop。这里我下载的是CDH版本Hadoop,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
3.2 配置环境变量
编辑profile文件:
# vim /etc/profile
增加如下配置:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH
执行source命令,使得配置立即生效:
# source /etc/profile
3.3 修改配置
进入${HADOOP_HOME}/etc/hadoop目录下,修改配置文件。各个配置文件内容如下:
1. hadoop-env.sh
# 指定JDK的安装位置
export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定hadoop集群存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3. hdfs-site.xml
<property>
<!--namenode节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔-->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!--datanode节点数据(即数据块)的存放位置-->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>
4. yarn-site.xml
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--resourcemanager的主机名-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
</configuration>
5. mapred-site.xml
<configuration>
<property>
<!--指定mapreduce作业运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5. slaves
配置所有从属节点的主机名或IP地址,每行一个。所有从属节点上的DataNode服务和NodeManager服务都会被启动。
hadoop001
hadoop002
hadoop003
3.4 分发程序
将Hadoop安装包分发到其他两台服务器,分发后建议在这两台服务器上也配置一下Hadoop的环境变量。
# 将安装包分发到hadoop002
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop002:/usr/app/
# 将安装包分发到hadoop003
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop003:/usr/app/
3.5 初始化
在Hadoop001上执行namenode初始化命令:
hdfs namenode -format
3.6 启动集群
进入到Hadoop001的${HADOOP_HOME}/sbin目录下,启动Hadoop。此时hadoop002和hadoop003上的相关服务也会被启动:
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh
3.7 查看集群
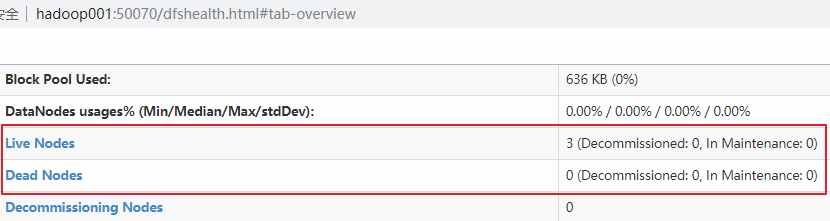
在每台服务器上使用jps命令查看服务进程,或直接进入Web-UI界面进行查看,端口为50070。可以看到此时有三个可用的Datanode:
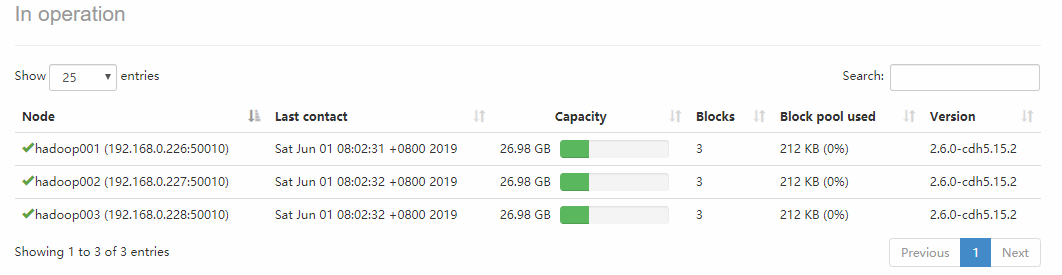
点击Live Nodes进入,可以看到每个DataNode的详细情况:
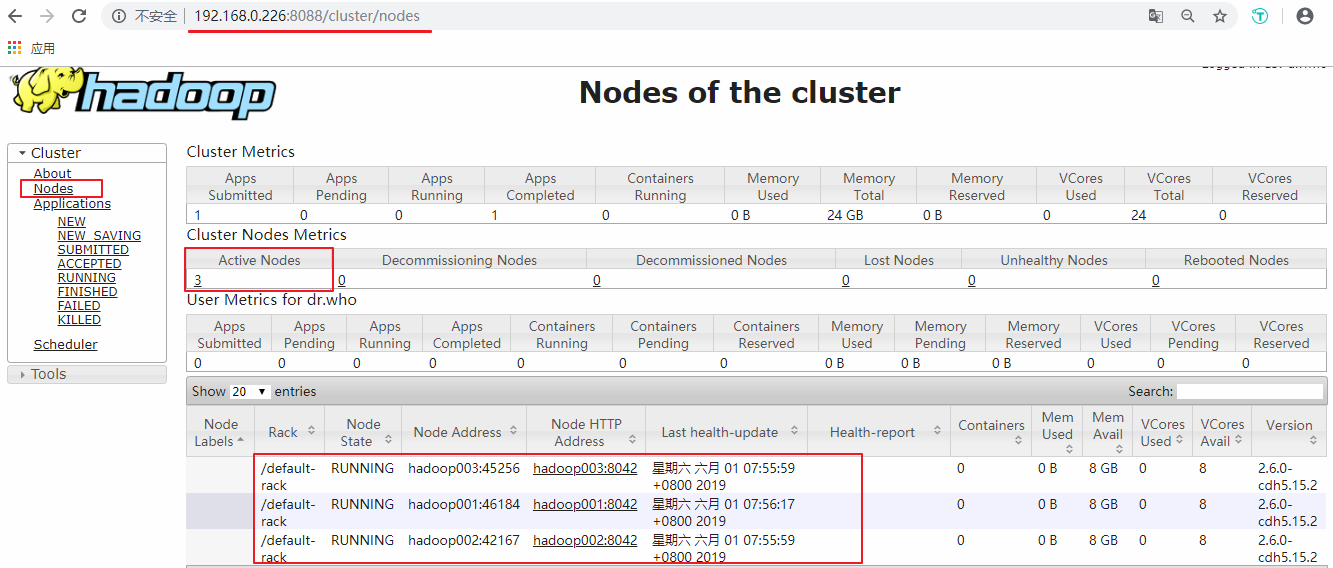
接着可以查看Yarn的情况,端口号为8088 :
五、提交服务到集群
提交作业到集群的方式和单机环境完全一致,这里以提交Hadoop内置的计算Pi的示例程序为例,在任何一个节点上执行都可以,命令如下:
hadoop jar /usr/app/hadoop-2.6.0-cdh5.15.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
最新文章
- Django底层剖析之一次请求到响应的整个流程
- 关于Docker官方CentOS镜像无法启动mysqld的总结
- C++ JsonCpp 使用(含源码下载)
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
- 通俗易懂的讲解iphone视图控制器的生命周期
- ArrayList和List之间的转换
- 探索Microsoft.NET目录
- TIPSO--基于JQUERY的消息提示框插件,用起来蛮顺手
- 怎样在Yii中显示静态页
- struct2(一)第一个struct程序
- mongodb内嵌文档的查询
- 【 js 基础 】【 源码学习 】backbone 源码阅读(二)
- laravel的消息队列剖析
- centos7配置网易yum源
- 结合iconworkshop,创建ribbon界面
- ActivityThread
- 从Linux内核中获取真随机数【转】
- (原)torch中提示Unwritable object <userdata> at <?>.callback.self.XXX.threads.__gc__
- 转载:SQL中Group By 的常见使用方法
- Android的taskAffinity对四种launchMode的影响
热门文章
- Information Centric Networking Based Service Centric Networking
- Full Stack developer and Fog Computing
- 解决引用 System.Windows.Interactivity程序集生成多国语言文件夹fr、es、ja等问题
- XF 标签和文本控件
- 九款免费轻量的 AutoCAD 的开源替代品推荐
- WPF中的资源(二) - 二进制资源
- 3D-Touch Home Screen Quick Actions 使用
- PMC另类阐述
- Win10《芒果TV》商店版更新v3.2.7:修复下载任务和会员下载权限异常
- How to manipulate pixels on a bitmap by scanline property(Ma Xiaoguang and Ma Xiaoming)