(MySQL里的数据)通过Sqoop Import HDFS 里 和 通过Sqoop Export HDFS 里的数据到(MySQL)(五)
下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出
一、MySQL里的数据通过Sqoop import HDFS
它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示。
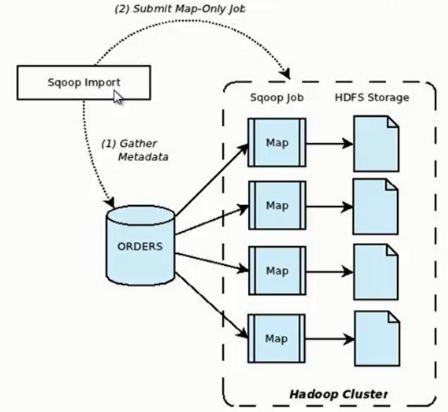
我们来分析一下 Sqoop 数据导入流程,首先用户输入一个 Sqoop import 命令,Sqoop 会从关系型数据库中获取元数据信息,
比如要操作数据库表的 schema是什么样子,这个表有哪些字段,这些字段都是什么数据类型等。
它获取这些信息之后,会将输入命令转化为基于 Map 的 MapReduce作业。
这样 MapReduce作业中有很多 Map 任务,每个 Map 任务从数据库中读取一片数据,这样多个 Map 任务实现并发的拷贝,把整个数据快速的拷贝到 HDFS 上。
Sqoop Import HDFS(带着官网)



具体,自己去尝试做吧!
在这之前,先启动hadoop集群,sbin/start-all.sh。这里不多赘述。
同时,开启MySQL数据库。这里,不多赘述。
同时,因为后续的sqoop运行啊,会产生一些日志等,我这里先新建一个目录,用来专门存放它。在哪个目录下运行后续的sqoop操作,就在哪个目录下新建就好。(因为,已经配置了环境变量,在任何路径下都是可以运行的)
[hadoop@djt002 sqoop]$ pwd
/usr/local/sqoop
[hadoop@djt002 sqoop]$ ll
total 4
drwxr-xr-x. 9 hadoop hadoop 4096 Apr 27 2015 sqoop-1.4.6
[hadoop@djt002 sqoop]$ mkdir sqoopRunCreate
[hadoop@djt002 sqoop]$ ll
total 8
drwxr-xr-x. 9 hadoop hadoop 4096 Apr 27 2015 sqoop-1.4.6
drwxrwxr-x. 2 hadoop hadoop 4096 Mar 17 23:33 sqoopRunCreate
[hadoop@djt002 sqoop]$ cd sqoopRunCreate/
[hadoop@djt002 sqoopRunCreate]$ pwd
/usr/local/sqoop/sqoopRunCreate
[hadoop@djt002 sqoopRunCreate]$
比如,以后我就在这个目录下运行操作sqoop,/usr/local/sqoop/sqoopRunCreate。
Sqoop Import 应用场景——密码访问
(1)明码访问
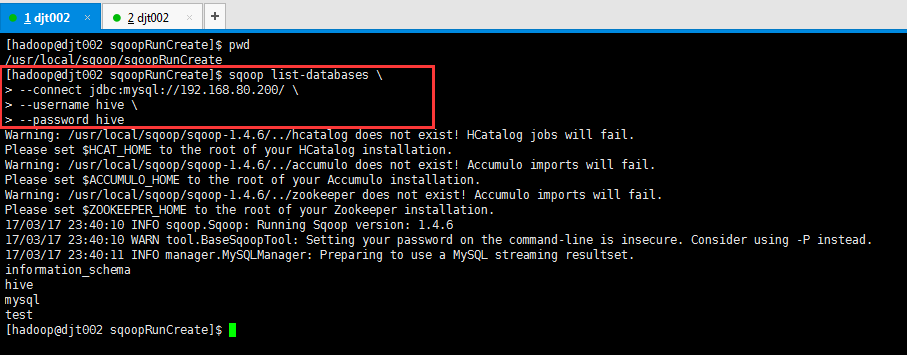
[hadoop@djt002 sqoopRunCreate]$ sqoop list-databases \
> --connect jdbc:mysql://192.168.80.200/ \
> --username hive \
> --password hive
(2)交互式密码访问
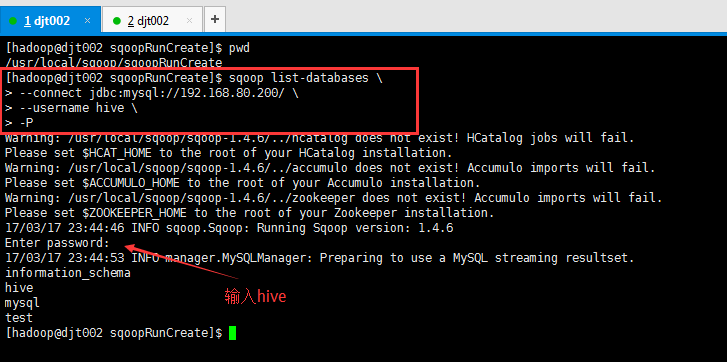
[hadoop@djt002 sqoopRunCreate]$ sqoop list-databases \
> --connect jdbc:mysql://192.168.80.200/ \
> --username hive \
> -P Enter password: (输入hive)
(3)文件授权密码访问
因为,官网上是这么给的,在家目录,且需赋予400权限。所以
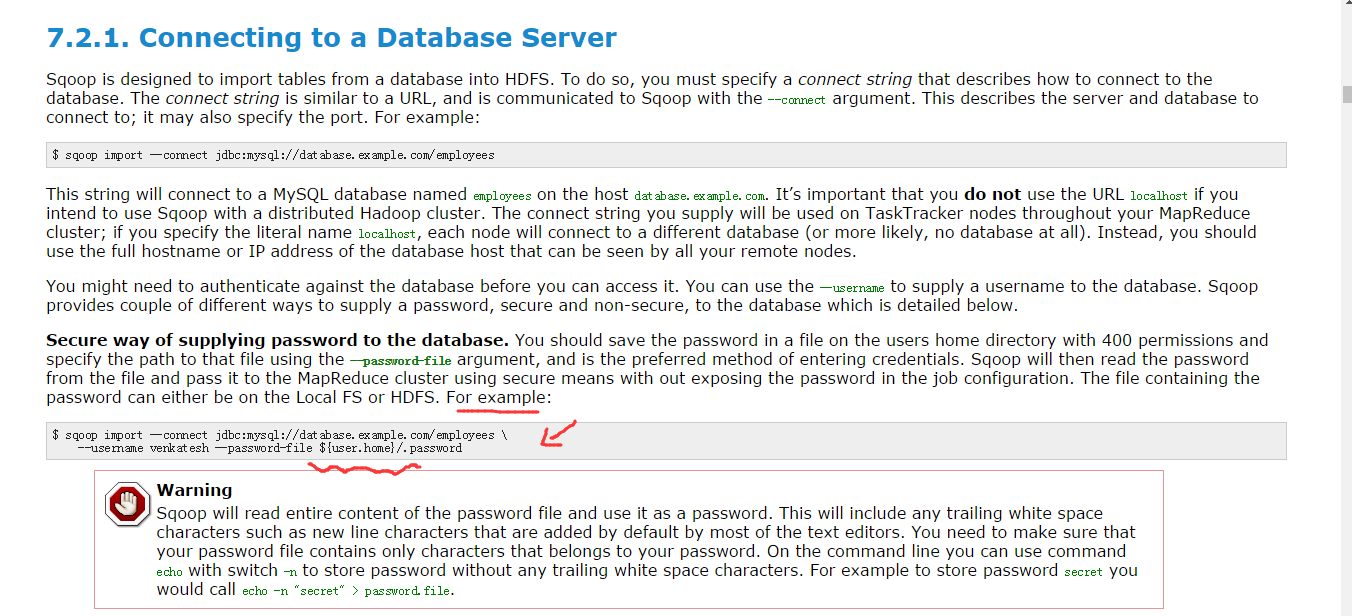

[hadoop@djt002 ~]$ pwd
/home/hadoop
[hadoop@djt002 ~]$ echo -n "hive" > .password
[hadoop@djt002 ~]$ ls -a
. .bash_history .cache djt flume .gnote .gvfs .local .nautilus .pulse Videos .xsession-errors
.. .bash_logout .config Documents .gconf .gnupg .hivehistory .mozilla .password .pulse-cookie .vim .xsession-errors.old
.abrt .bash_profile .dbus Downloads .gconfd .gstreamer-0.10 .ICEauthority Music Pictures .ssh .viminfo
anagram.jar .bashrc Desktop .esd_auth .gnome2 .gtk-bookmarks .imsettings.log .mysql_history Public Templates .Xauthority
[hadoop@djt002 ~]$ more .password
hive
[hadoop@djt002 ~]$

[hadoop@djt002 ~]$ chmod 400 .password
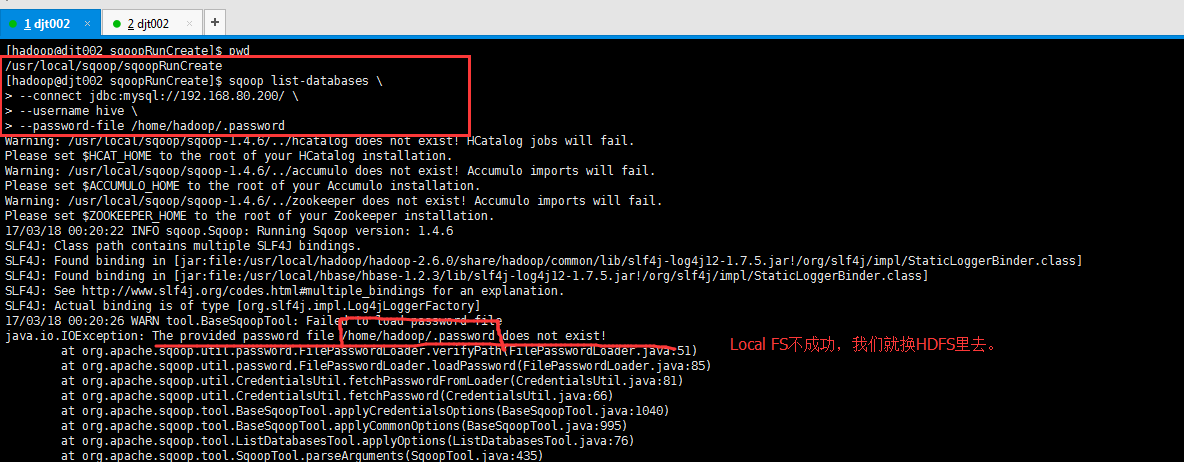
[hadoop@djt002 sqoopRunCreate]$ sqoop list-databases \
> --connect jdbc:mysql://192.168.80.200/ \
> --username hive \
> --password-file /home/hadoop/.password java.io.IOException: The provided password file /home/hadoop/.password does not exist!
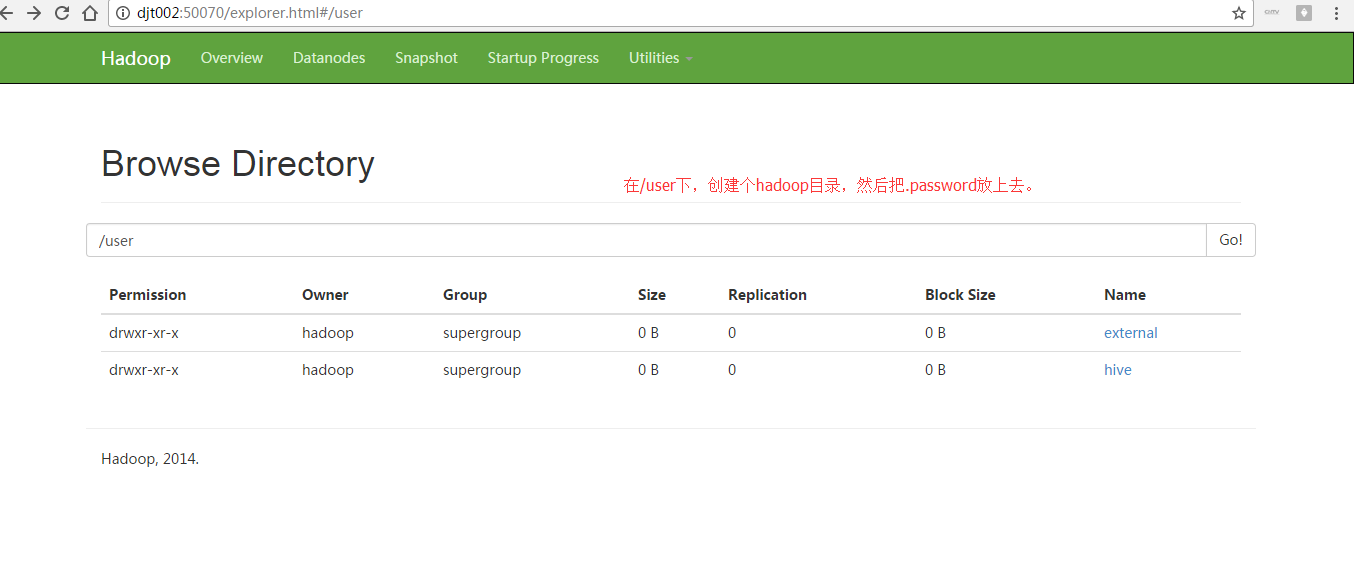


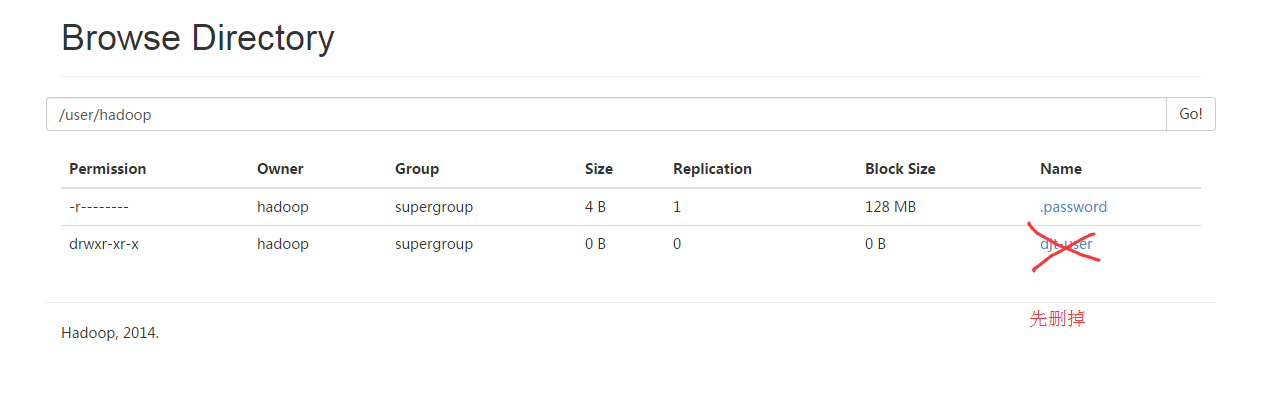
[hadoop@djt002 local]$ $HADOOP_HOME/bin/hadoop dfs -put /home/hadoop/.password /user/hadoop [hadoop@djt002 local]$ $HADOOP_HOME/bin/hadoop dfs -chmod 400 /user/hadoop/.password

[hadoop@djt002 ~]$ rm .password
rm: remove write-protected regular file `.password'? y
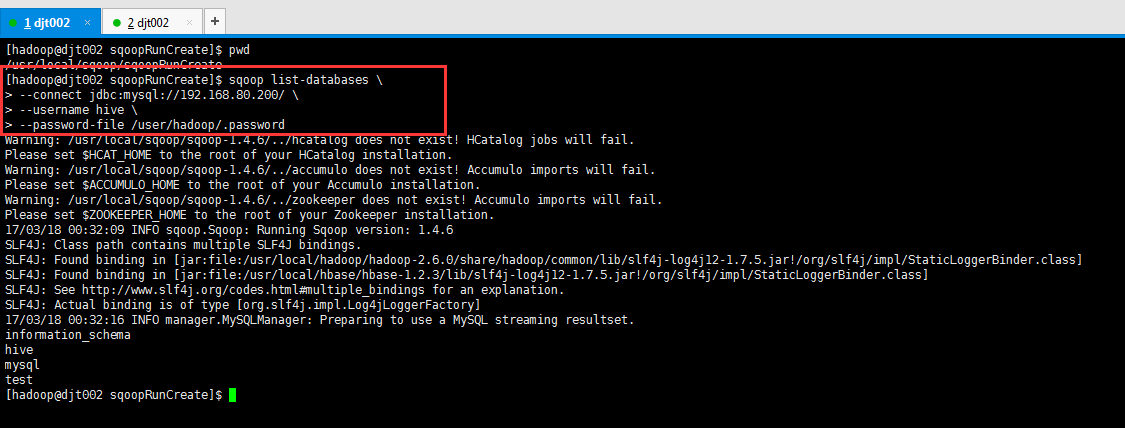
[hadoop@djt002 sqoopRunCreate]$ sqoop list-databases \
> --connect jdbc:mysql://192.168.80.200/ \
> --username hive \
> --password-file /user/hadoop/.password
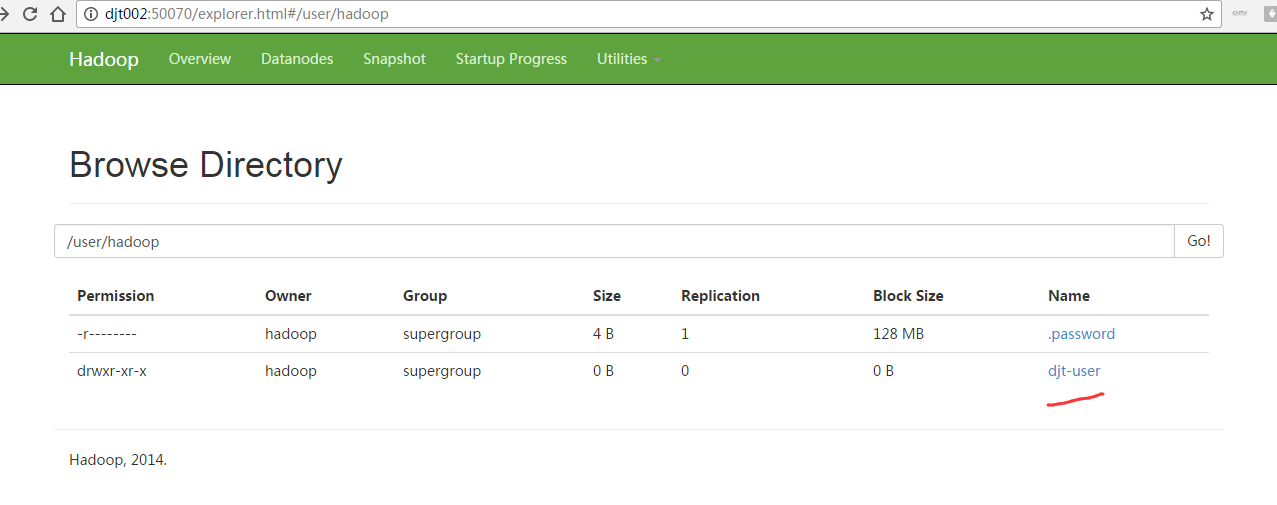
Sqoop Import 应用场景——导入全表
(1)不指定目录 (则默认是在/user/hadoop/下)
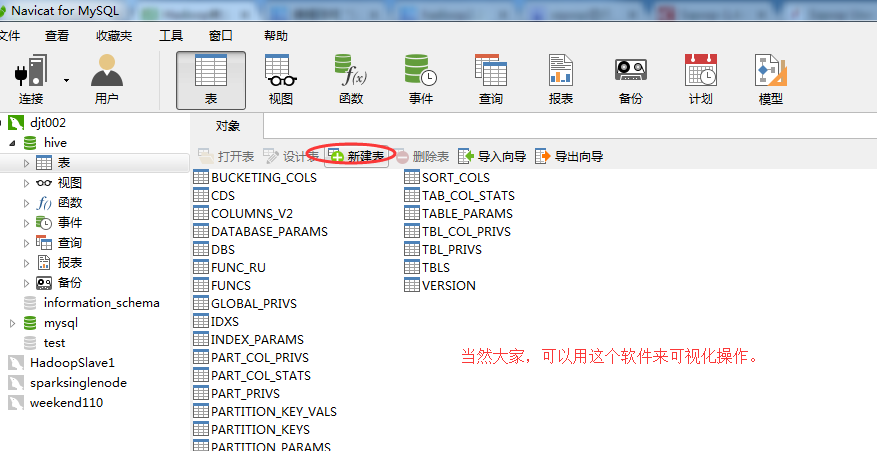
我这里啊,给大家尝试另一个软件。(为什么,要这样带大家使用,是为了你们的多适应和多自学能力)(别嫌麻烦!)
SQLyog之MySQL客户端的下载、安装和使用
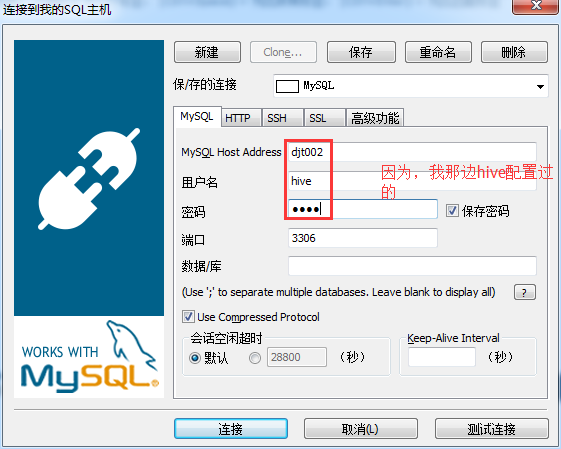
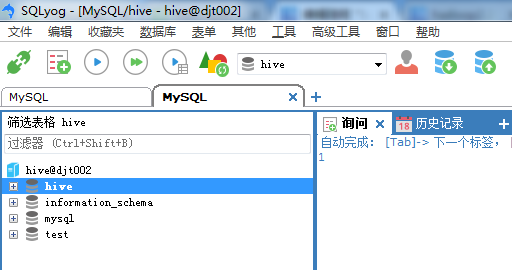
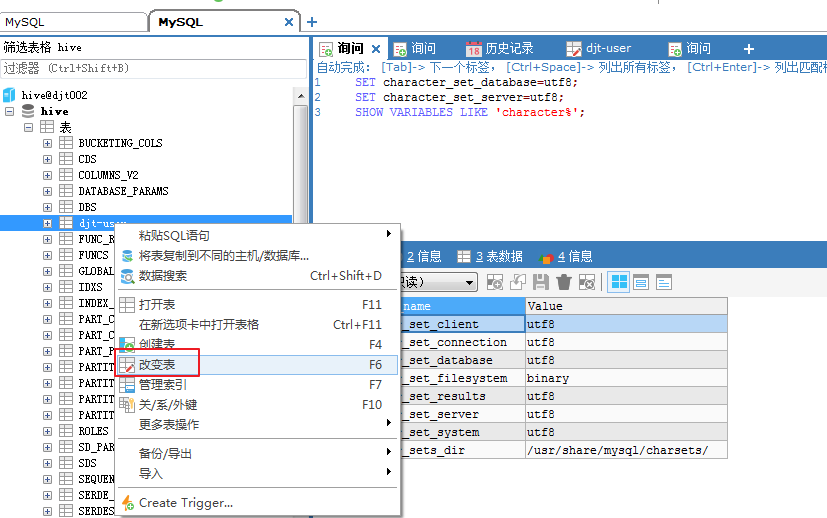
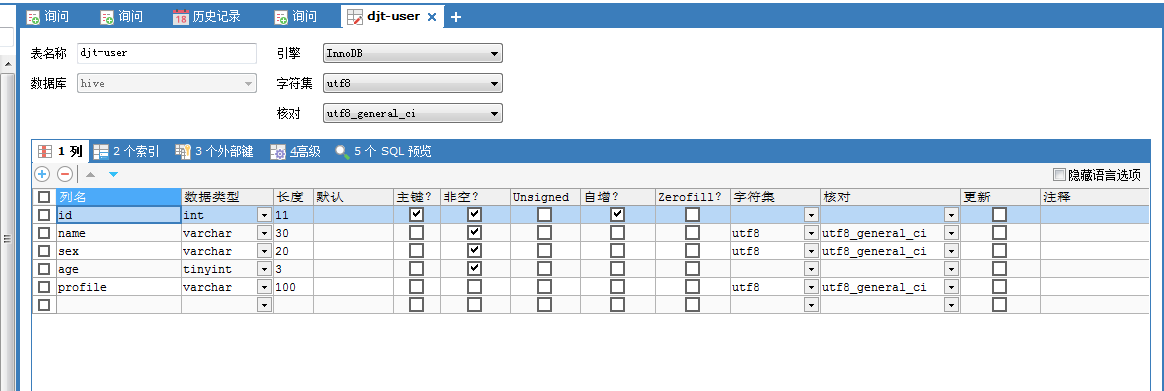
这里,我们选择在hive这个数据库里,创建新的表,命名为
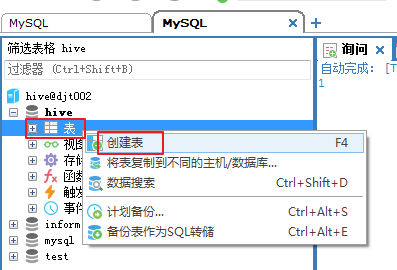

如果,面对 SQLyog不能正常显示中文数据的情况:在SQLyog下输入SET character_set_results = gb2312(或 gbk),执行,重新启动SQLyog,显示应该也可以看到你所插入的中文数据了。
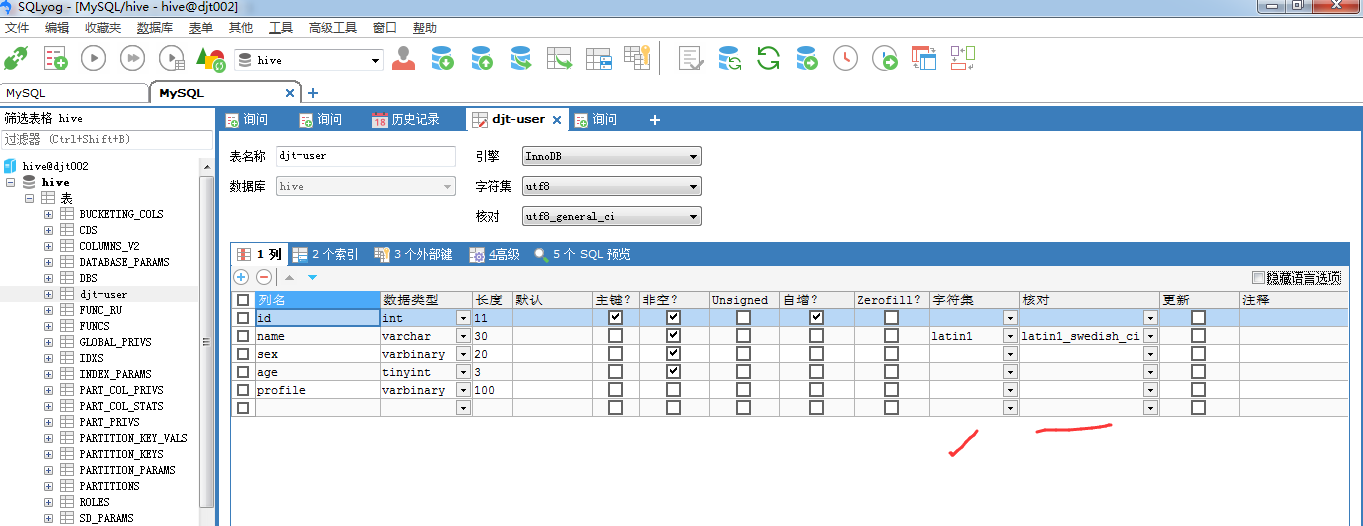
SQLyog软件里无法插入中文(即由默认的latin1改成UTF8编码格式)

注意,我的数据表是djt-user。我这里改名啦!

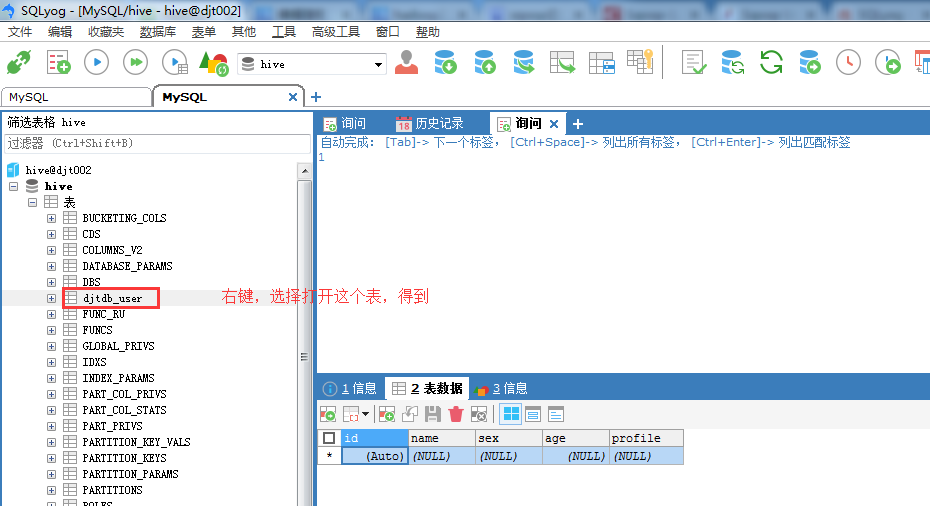
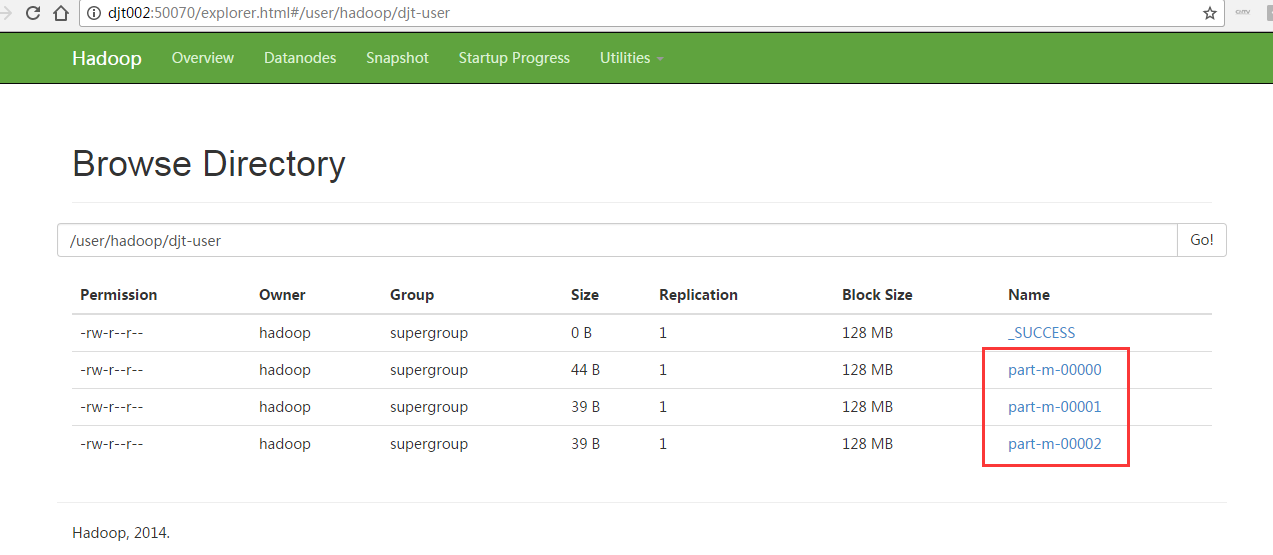
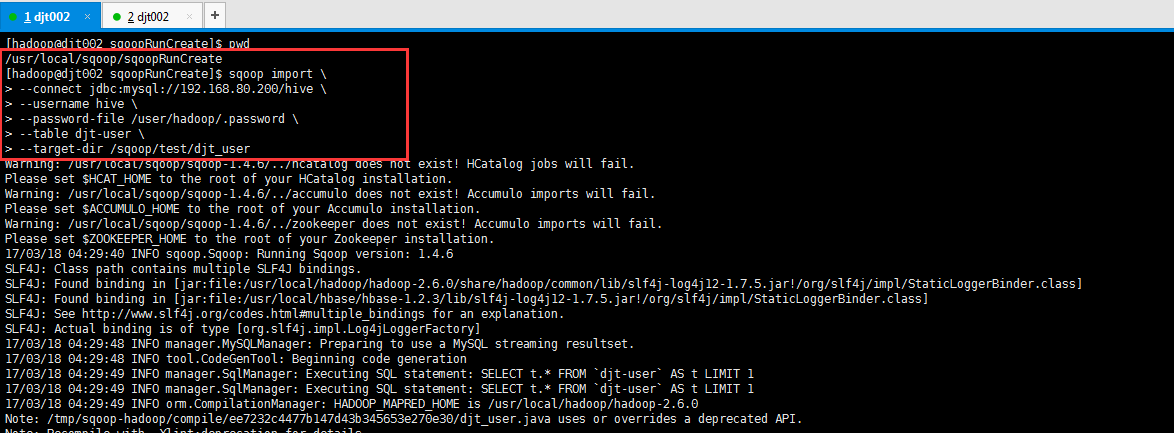
[hadoop@djt002 sqoopRunCreate]$ sqoop import \
> --connect jdbc:mysql://192.168.80.200/hive \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt-user

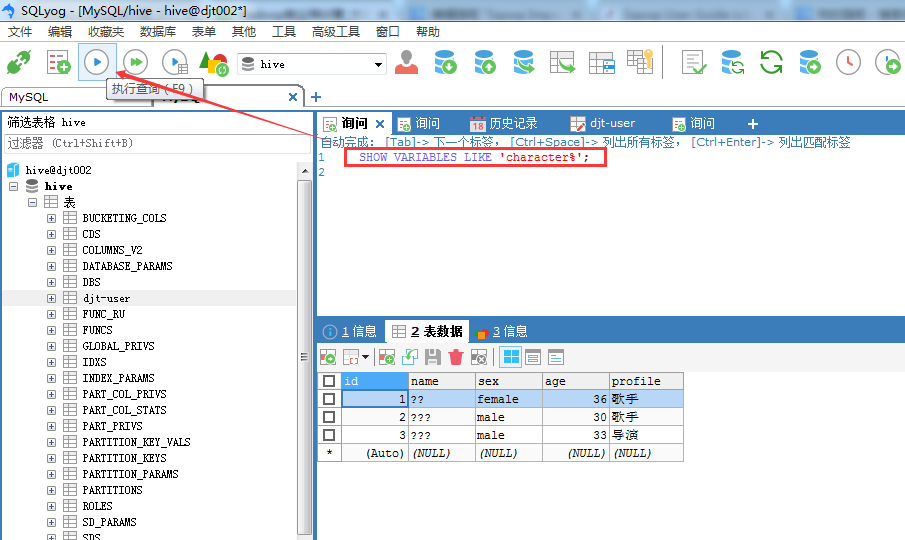
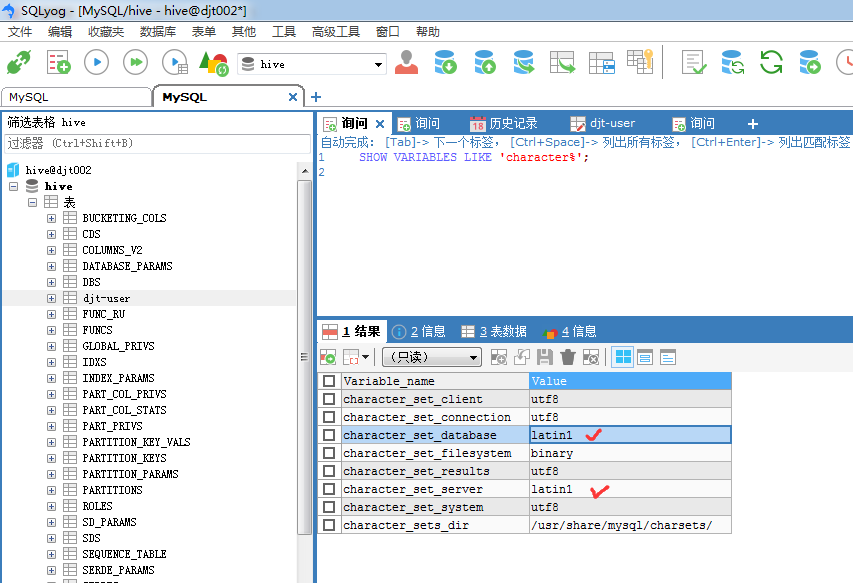
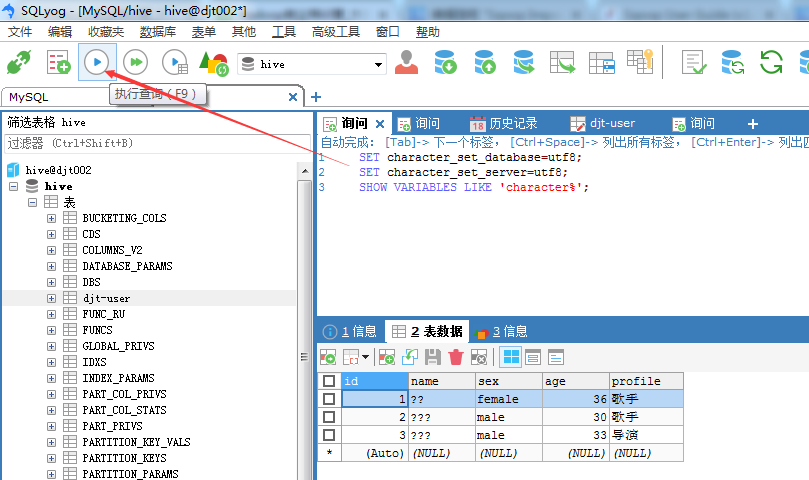
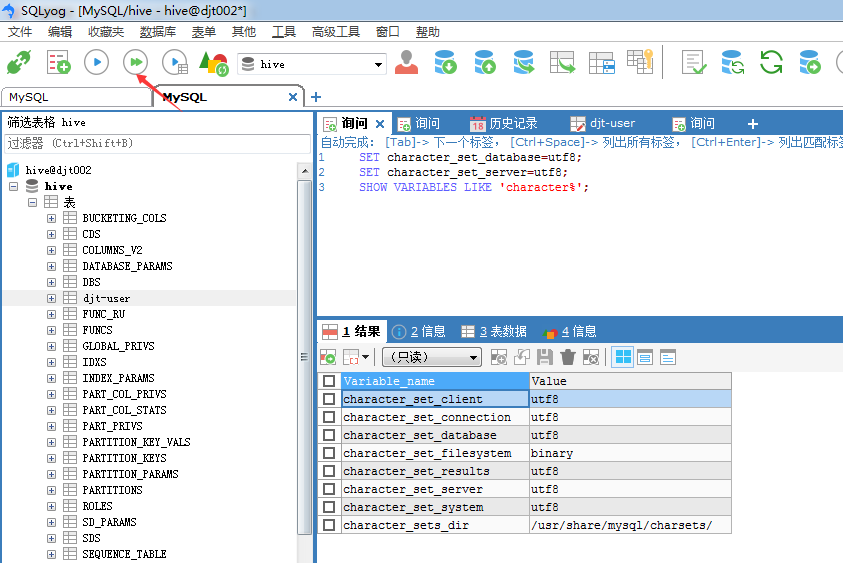
SET character_set_database=utf8;
SET character_set_server=utf8;
SHOW VARIABLES LIKE 'character%';


[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -rmr /user/hadoop/djt-user

[hadoop@djt002 sqoopRunCreate]$ sqoop import --connect jdbc:mysql://192.168.80.200/hive --username hive --password-file /user/hadoop/.password --table djt-user
[hadoop@djt002 sqoopRunCreate]$ sqoop import --connect jdbc:mysql://192.168.80.200/hive --username hive --password-file /user/hadoop/.password --table djt-user
Warning: /usr/local/sqoop/sqoop-1.4.6/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/sqoop-1.4.6/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop/sqoop-1.4.6/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
17/03/18 04:17:10 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hbase/hbase-1.2.3/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
17/03/18 04:17:14 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/03/18 04:17:14 INFO tool.CodeGenTool: Beginning code generation
17/03/18 04:17:15 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `djt-user` AS t LIMIT 1
17/03/18 04:17:15 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `djt-user` AS t LIMIT 1
17/03/18 04:17:15 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop/hadoop-2.6.0
Note: /tmp/sqoop-hadoop/compile/38104c9fe28c7f43fdb42c26826dbf91/djt_user.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
17/03/18 04:17:21 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/38104c9fe28c7f43fdb42c26826dbf91/djt-user.jar
17/03/18 04:17:21 WARN manager.MySQLManager: It looks like you are importing from mysql.
17/03/18 04:17:21 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
17/03/18 04:17:21 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
17/03/18 04:17:21 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
17/03/18 04:17:21 INFO mapreduce.ImportJobBase: Beginning import of djt-user
17/03/18 04:17:21 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/03/18 04:17:21 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/03/18 04:17:22 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/03/18 04:17:30 INFO db.DBInputFormat: Using read commited transaction isolation
17/03/18 04:17:30 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`id`), MAX(`id`) FROM `djt-user`
17/03/18 04:17:31 INFO mapreduce.JobSubmitter: number of splits:3
17/03/18 04:17:32 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1489767532299_0002
17/03/18 04:17:33 INFO impl.YarnClientImpl: Submitted application application_1489767532299_0002
17/03/18 04:17:33 INFO mapreduce.Job: The url to track the job: http://djt002:8088/proxy/application_1489767532299_0002/
17/03/18 04:17:33 INFO mapreduce.Job: Running job: job_1489767532299_0002
17/03/18 04:18:03 INFO mapreduce.Job: Job job_1489767532299_0002 running in uber mode : false
17/03/18 04:18:03 INFO mapreduce.Job: map 0% reduce 0%
17/03/18 04:19:09 INFO mapreduce.Job: map 67% reduce 0%
17/03/18 04:19:12 INFO mapreduce.Job: map 100% reduce 0%
17/03/18 04:19:13 INFO mapreduce.Job: Job job_1489767532299_0002 completed successfully
17/03/18 04:19:13 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=370638
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=295
HDFS: Number of bytes written=105
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Job Counters
Launched map tasks=3
Other local map tasks=3
Total time spent by all maps in occupied slots (ms)=174022
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=174022
Total vcore-seconds taken by all map tasks=174022
Total megabyte-seconds taken by all map tasks=178198528
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=295
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=5172
CPU time spent (ms)=9510
Physical memory (bytes) snapshot=362741760
Virtual memory (bytes) snapshot=2535641088
Total committed heap usage (bytes)=181862400
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=105
17/03/18 04:19:13 INFO mapreduce.ImportJobBase: Transferred 105 bytes in 111.9157 seconds (0.9382 bytes/sec)
17/03/18 04:19:13 INFO mapreduce.ImportJobBase: Retrieved 3 records.
[hadoop@djt002 sqoopRunCreate]$
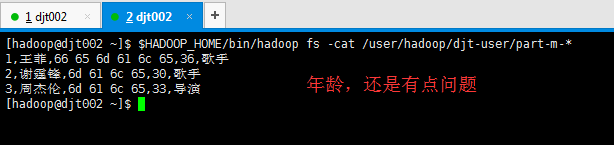



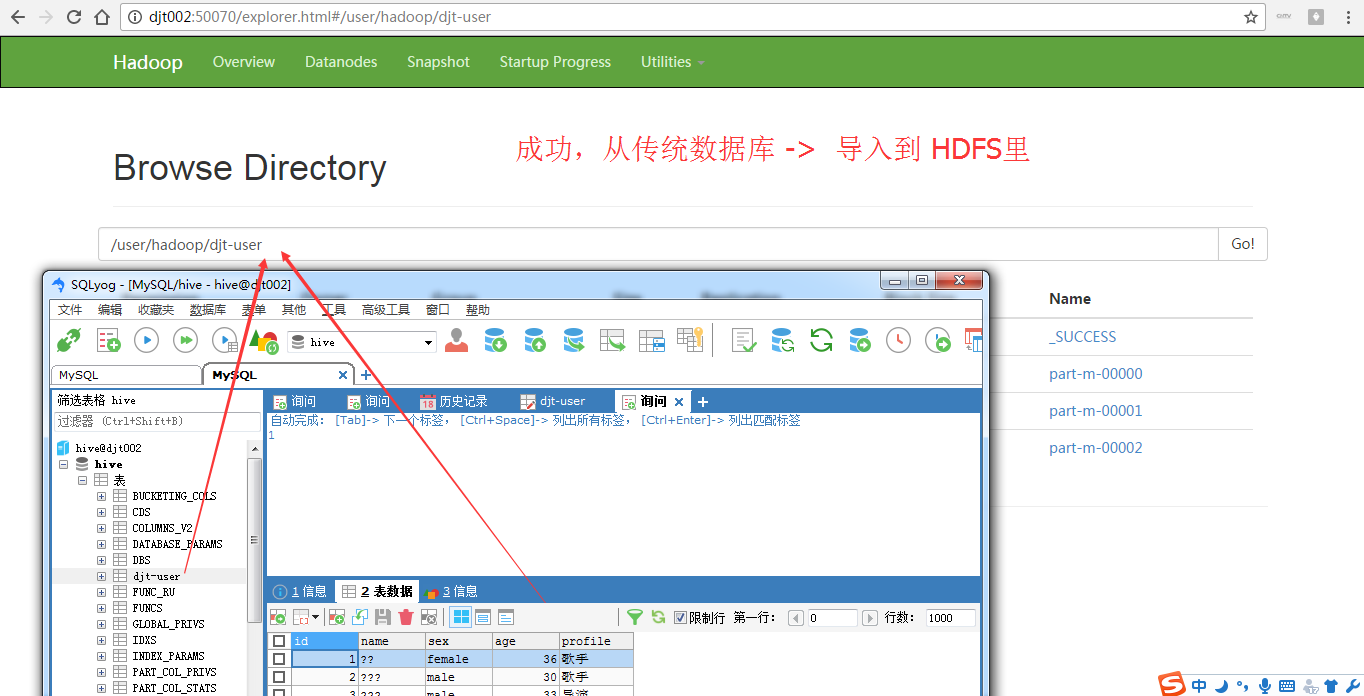
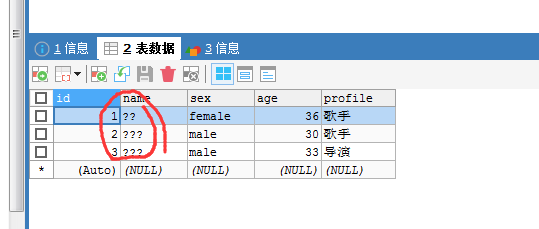
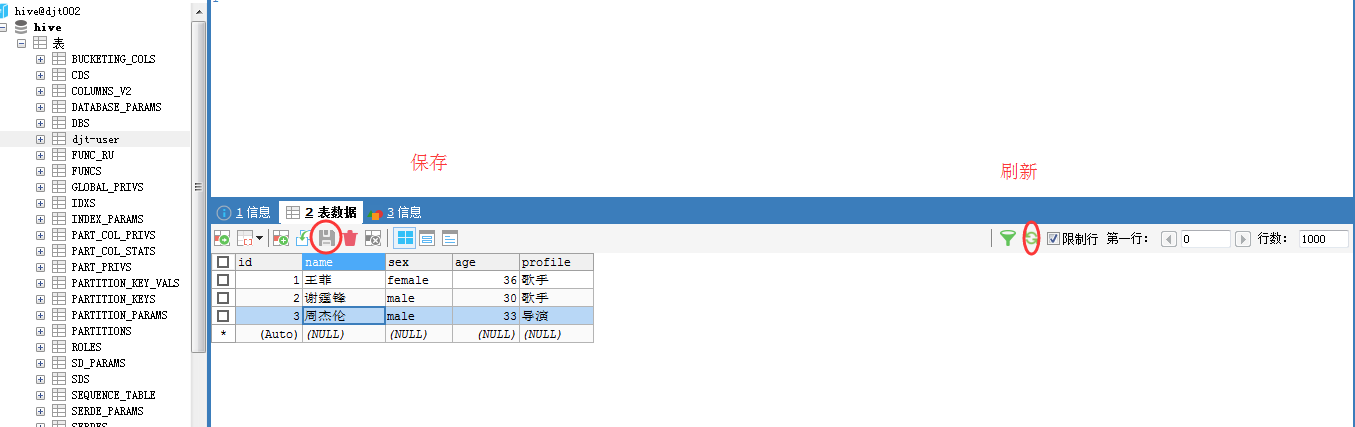
[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /user/hadoop/djt-user/part-m-*
1,王菲,female,36,歌手
2,谢霆锋,male,30,歌手
3,周杰伦,male,33,导演
[hadoop@djt002 ~]$
总结
不指定目录 sqoop import \
--connect 'jdbc:mysql://192.168.128.200/hive \
--username hive \
--password-file /user/hadoop/.password \
--table djt_user
不指定目录 (推荐这种) sqoop import \
--connect 'jdbc:mysql://192.168.128.200/hive?useUnicode=true&characterEncoding=utf-8' \
--username hive \
--password-file /user/hadoop/.password \
--table djt_user
即,djt_user是在MySQL里,通过Sqoop工具,导入到HDFS里,这里是在/user/hadoop/djt_user。
(2)指定目录
任意可以指定的。
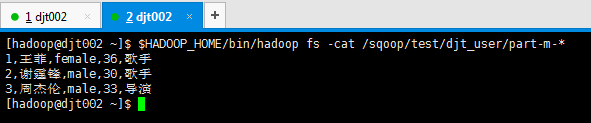
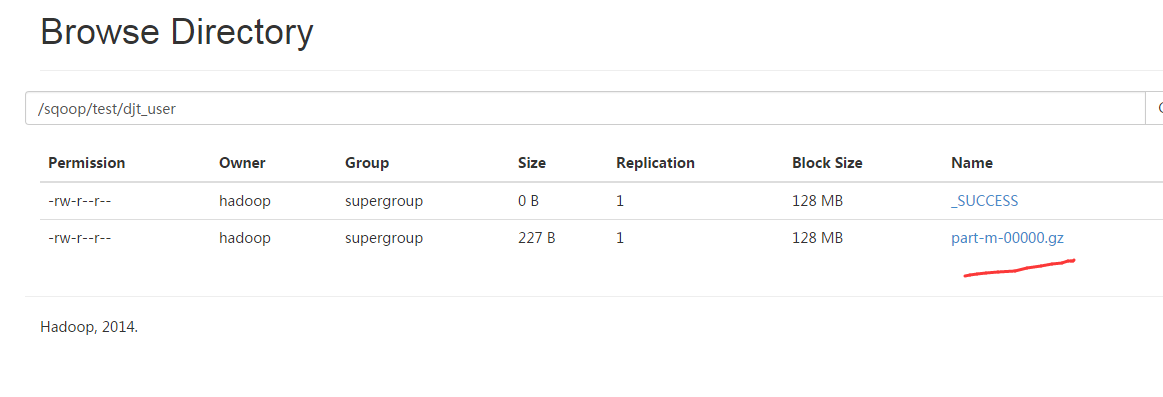
[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
1,王菲,female,36,歌手
2,谢霆锋,male,30,歌手
3,周杰伦,male,33,导演
[hadoop@djt002 ~]$
这里,为统一标准和规范化,用数据表djt_user。
(3)目录已存在
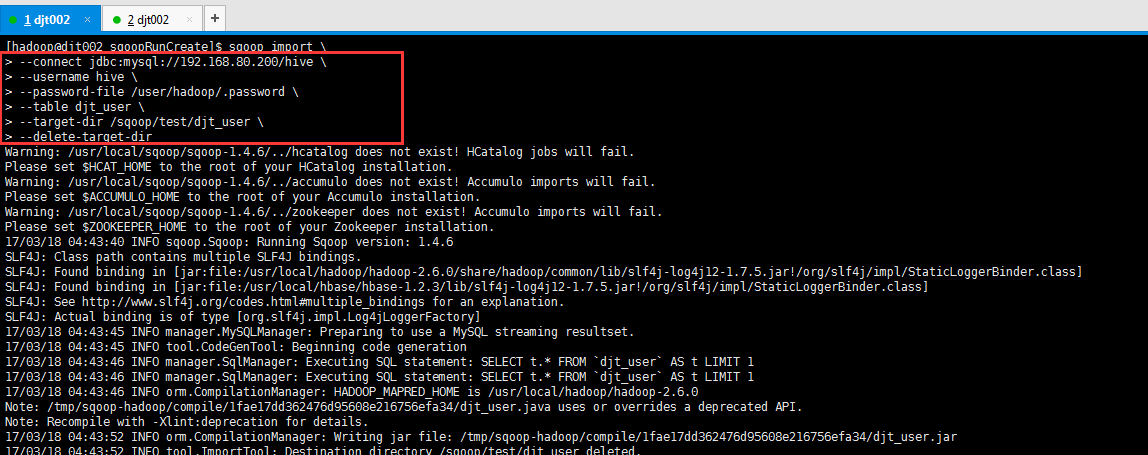
[hadoop@djt002 sqoopRunCreate]$ sqoop import \
> --connect jdbc:mysql://192.168.80.200/hive \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user \
> --target-dir /sqoop/test/djt_user \
> --delete-target-dir
Warning: /usr/local/sqoop/sqoop-1.4.6/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/sqoop-1.4.6/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop/sqoop-1.4.6/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
17/03/18 04:43:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hbase/hbase-1.2.3/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
17/03/18 04:43:45 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/03/18 04:43:45 INFO tool.CodeGenTool: Beginning code generation
17/03/18 04:43:46 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `djt_user` AS t LIMIT 1
17/03/18 04:43:46 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `djt_user` AS t LIMIT 1
17/03/18 04:43:46 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop/hadoop-2.6.0
Note: /tmp/sqoop-hadoop/compile/1fae17dd362476d95608e216756efa34/djt_user.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
17/03/18 04:43:52 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/1fae17dd362476d95608e216756efa34/djt_user.jar
17/03/18 04:43:52 INFO tool.ImportTool: Destination directory /sqoop/test/djt_user deleted.
17/03/18 04:43:52 WARN manager.MySQLManager: It looks like you are importing from mysql.
17/03/18 04:43:52 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
17/03/18 04:43:52 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
17/03/18 04:43:52 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
17/03/18 04:43:52 INFO mapreduce.ImportJobBase: Beginning import of djt_user
17/03/18 04:43:52 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/03/18 04:43:52 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/03/18 04:43:53 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/03/18 04:44:02 INFO db.DBInputFormat: Using read commited transaction isolation
17/03/18 04:44:02 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`id`), MAX(`id`) FROM `djt_user`
17/03/18 04:44:02 INFO mapreduce.JobSubmitter: number of splits:3
17/03/18 04:44:03 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1489767532299_0005
17/03/18 04:44:03 INFO impl.YarnClientImpl: Submitted application application_1489767532299_0005
17/03/18 04:44:03 INFO mapreduce.Job: The url to track the job: http://djt002:8088/proxy/application_1489767532299_0005/
17/03/18 04:44:03 INFO mapreduce.Job: Running job: job_1489767532299_0005
17/03/18 04:44:23 INFO mapreduce.Job: Job job_1489767532299_0005 running in uber mode : false
17/03/18 04:44:23 INFO mapreduce.Job: map 0% reduce 0%
17/03/18 04:45:21 INFO mapreduce.Job: map 67% reduce 0%
17/03/18 04:45:23 INFO mapreduce.Job: map 100% reduce 0%
17/03/18 04:45:23 INFO mapreduce.Job: Job job_1489767532299_0005 completed successfully
17/03/18 04:45:24 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=370635
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=295
HDFS: Number of bytes written=80
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Job Counters
Launched map tasks=3
Other local map tasks=3
Total time spent by all maps in occupied slots (ms)=163316
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=163316
Total vcore-seconds taken by all map tasks=163316
Total megabyte-seconds taken by all map tasks=167235584
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=295
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=3240
CPU time spent (ms)=8480
Physical memory (bytes) snapshot=356696064
Virtual memory (bytes) snapshot=2535596032
Total committed heap usage (bytes)=181862400
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=80
17/03/18 04:45:24 INFO mapreduce.ImportJobBase: Transferred 80 bytes in 91.6189 seconds (0.8732 bytes/sec)
17/03/18 04:45:24 INFO mapreduce.ImportJobBase: Retrieved 3 records.
[hadoop@djt002 sqoopRunCreate]$


Sqoop Import 应用场景——控制并行度
(1)控制并行度
默认是4个,当然我这里数据量小,指定1个就行了。

[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -rm /sqoop/test/djt_user/part-m-*
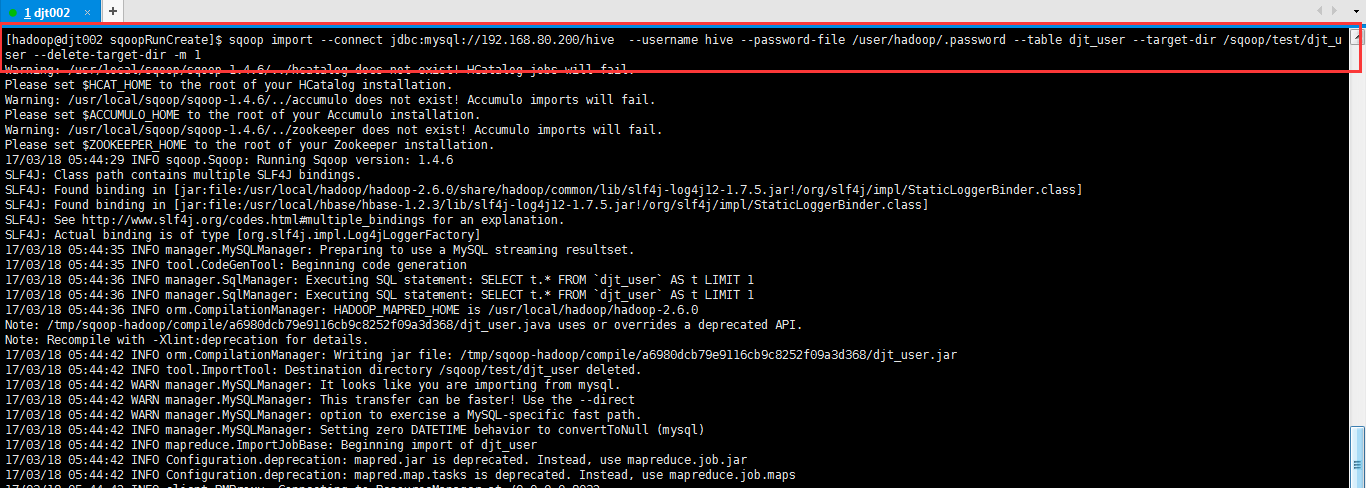
[hadoop@djt002 sqoopRunCreate]$ sqoop import \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user \
> --target-dir /sqoop/test/djt_user \
> --delete-target-dir \
> -m 1
在这里,可能会遇到这个问题。
Sqoop异常解决ERROR tool.ImportTool: Encountered IOException running import job: java.io.IOException: No columns to generate for ClassWriter问题
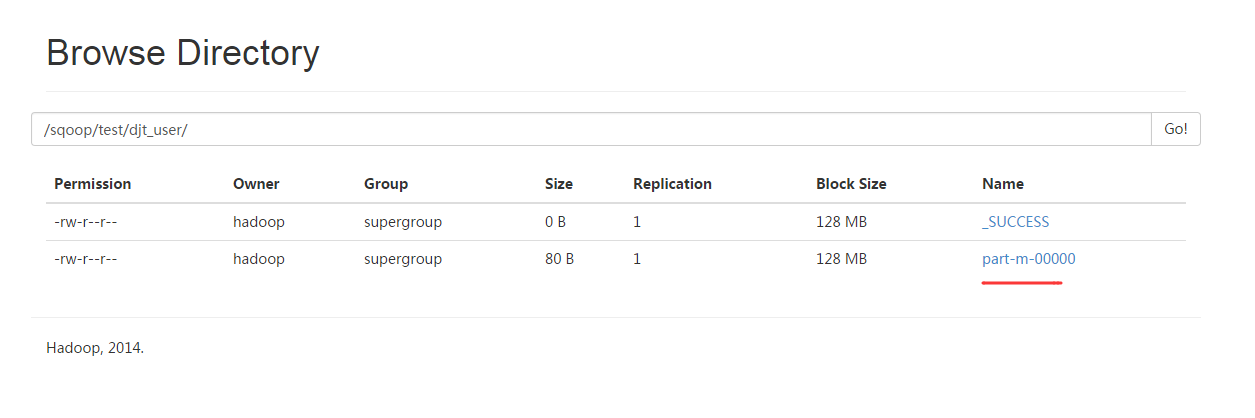
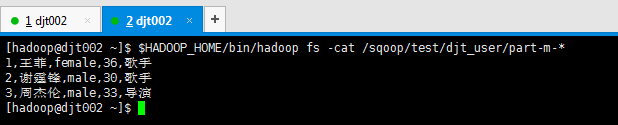
[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
Sqoop Import 应用场景——控制字段分隔符
(1)控制字段分隔符
注意,默认的控制分段分隔符是逗号,我们这里自定义。
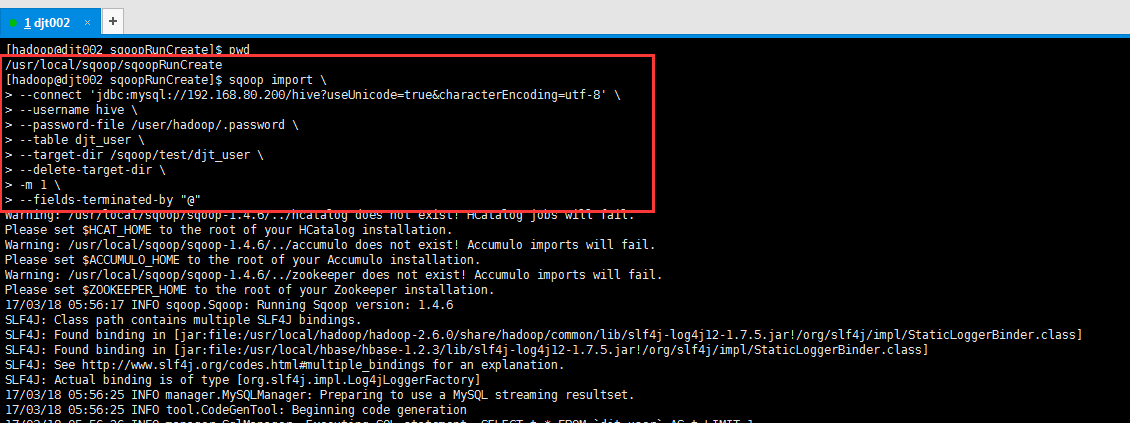
[hadoop@djt002 sqoopRunCreate]$ sqoop import \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user \
> --target-dir /sqoop/test/djt_user \
> --delete-target-dir \
> -m 1 \
> --fields-terminated-by "@"
这里,djt_user是在MySQL里,通过Sqoop工具,导入到HDFS里,是在/sqoop/test/djt_user。
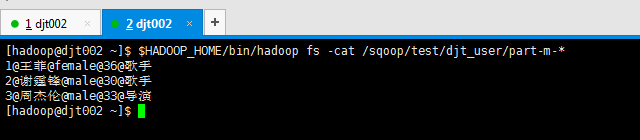
[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
1@王菲@female@36@歌手
2@谢霆锋@male@30@歌手
3@周杰伦@male@33@导演
[hadoop@djt002 ~]$
(2)手动增量导入
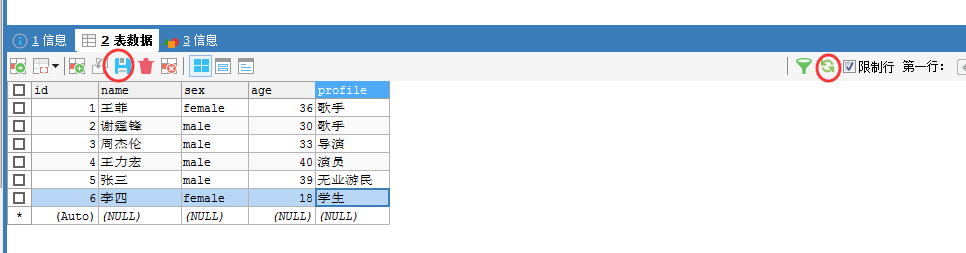
我们加入,4、5和6。
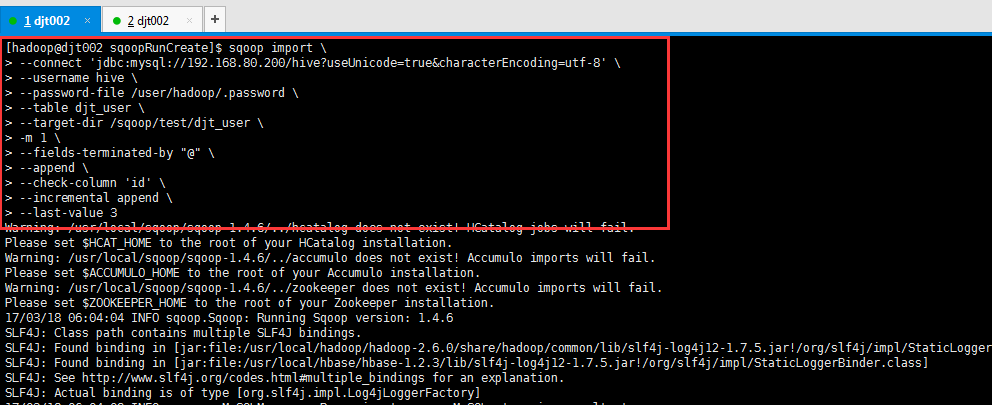
[hadoop@djt002 sqoopRunCreate]$ sqoop import \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user \
> --target-dir /sqoop/test/djt_user \
> -m 1 \
> --fields-terminated-by "@" \
> --append \
> --check-column 'id' \
> --incremental append \
> --last-value 3
这里,djt_user是在MySQL里,通过Sqoop工具,导入到HDFS里,是在/sqoop/test/djt_user。

[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
1@王菲@female@36@歌手
2@谢霆锋@male@30@歌手
3@周杰伦@male@33@导演
4@王力宏@male@40@演员
5@张三@male@39@无业游民
6@李四@female@18@学生
[hadoop@djt002 ~]$
(3)自动增量导入
[hadoop@djt002 sqoopRunCreate]$ sqoop job \
> --create job_import_djt_user \
> -- import \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user \
> --target-dir /sqoop/test/djt_user \
> -m 1 \
> --fields-terminated-by "@" \
> --append \
> --check-column 'id' \
> --incremental append \
> --last-value 6 [hadoop@djt002 sqoopRunCreate]$ sqoop job --exec job_import_djt_user
这里,djt_user是在MySQL里,通过Sqoop工具,导入到HDFS里,是在/sqoop/test/djt_user。
删除某个job
[hadoop@djt002 sqoopRunCreate]$ sqoop job --delete job_import_djt_user
查看当前可用的job
[hadoop@djt002 sqoopRunCreate]$ sqoop job --list

查看某个具体job的信息
[hadoop@djt002 sqoopRunCreate]$ sqoop job --show job_import_djt_user
[hadoop@djt002 sqoopRunCreate]$ sqoop job --show
Warning: /usr/local/sqoop/sqoop-1.4.6/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/sqoop-1.4.6/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop/sqoop-1.4.6/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
17/03/18 06:50:58 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
Missing argument for option: show
[hadoop@djt002 sqoopRunCreate]$ clear
[hadoop@djt002 sqoopRunCreate]$ sqoop job --show job_import_djt_user
Warning: /usr/local/sqoop/sqoop-1.4.6/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/sqoop-1.4.6/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop/sqoop-1.4.6/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
17/03/18 06:51:47 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hbase/hbase-1.2.3/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Job: job_import_djt_user
Tool: import
Options:
----------------------------
verbose = false
incremental.last.value = 10
db.connect.string = jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8
codegen.output.delimiters.escape = 0
codegen.output.delimiters.enclose.required = false
codegen.input.delimiters.field = 0
hbase.create.table = false
hdfs.append.dir = true
db.table = djt_user
codegen.input.delimiters.escape = 0
import.fetch.size = null
accumulo.create.table = false
codegen.input.delimiters.enclose.required = false
db.username = hive
reset.onemapper = false
codegen.output.delimiters.record = 10
import.max.inline.lob.size = 16777216
hbase.bulk.load.enabled = false
hcatalog.create.table = false
db.clear.staging.table = false
incremental.col = id
codegen.input.delimiters.record = 0
db.password.file = /user/hadoop/.password
enable.compression = false
hive.overwrite.table = false
hive.import = false
codegen.input.delimiters.enclose = 0
accumulo.batch.size = 10240000
hive.drop.delims = false
codegen.output.delimiters.enclose = 0
hdfs.delete-target.dir = false
codegen.output.dir = .
codegen.auto.compile.dir = true
relaxed.isolation = false
mapreduce.num.mappers = 1
accumulo.max.latency = 5000
import.direct.split.size = 0
codegen.output.delimiters.field = 64
export.new.update = UpdateOnly
incremental.mode = AppendRows
hdfs.file.format = TextFile
codegen.compile.dir = /tmp/sqoop-hadoop/compile/d81bf23cb3eb8eb11e7064a16df0b92b
direct.import = false
hdfs.target.dir = /sqoop/test/djt_user
hive.fail.table.exists = false
db.batch = false
[hadoop@djt002 sqoopRunCreate]$
Sqoop Import 应用场景——启动压缩
启动压缩
默认是gzip压缩,具体去看官网
[hadoop@djt002 sqoopRunCreate]$ sqoop import \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> -table djt_user \
> --target-dir /sqoop/test/djt_user \
> --delete-target-dir \
> -m 1 \
> --fields-terminated-by "@" \
> -z
这里,djt_user是在MySQL里,通过Sqoop工具,导入到HDFS里,是在/sqoop/test/djt_user。

[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
Sqoop Import 应用场景——导入空值处理
(1)导入空值处理
先,不加空值处理,看是怎样的。

[hadoop@djt002 sqoopRunCreate]$ sqoop import \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> -table djt_user \
> --target-dir /sqoop/test/djt_user \
> --delete-target-dir \
> -m 1 \
> --fields-terminated-by "@"
>
这里,djt_user是在MySQL里,通过Sqoop工具,导入到HDFS里,是在/sqoop/test/djt_user。

[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
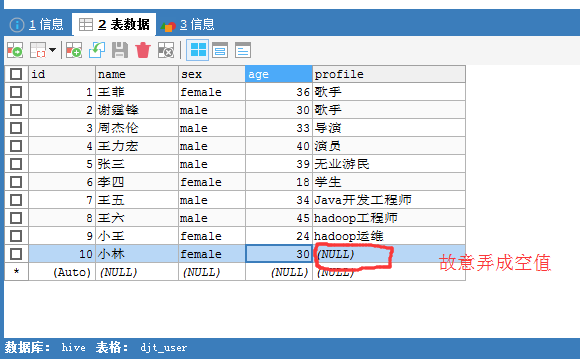
所以,一般需要对null进行转换,即需对空值进行处理。比如年龄那列,要么给他假如是18岁定死,要么就是0等。
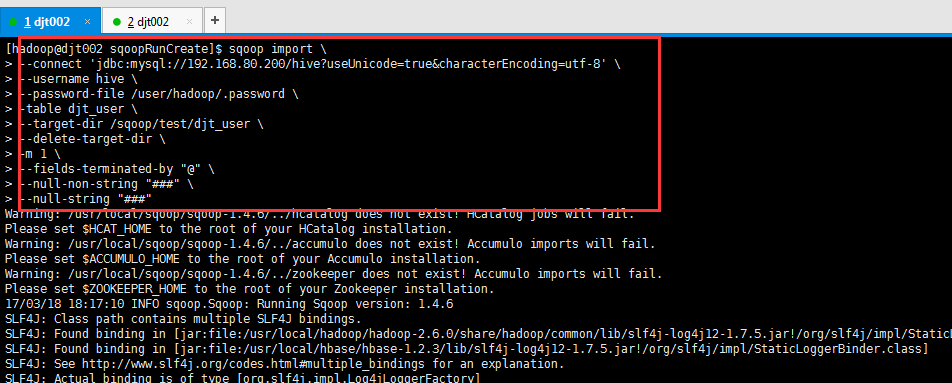
[hadoop@djt002 sqoopRunCreate]$ sqoop import \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> -table djt_user \
> --target-dir /sqoop/test/djt_user \
> --delete-target-dir \
> -m 1 \
> --fields-terminated-by "@" \
> --null-non-string "###" \
> --null-string "###"
这里,djt_user是在MySQL里,通过Sqoop工具,导入到HDFS里,是在/sqoop/test/djt_user。
我这里,将空值null转换成###,这个,大家可以根据自己的需要,可以转换成其它的,不多赘述。自行去举一反三。
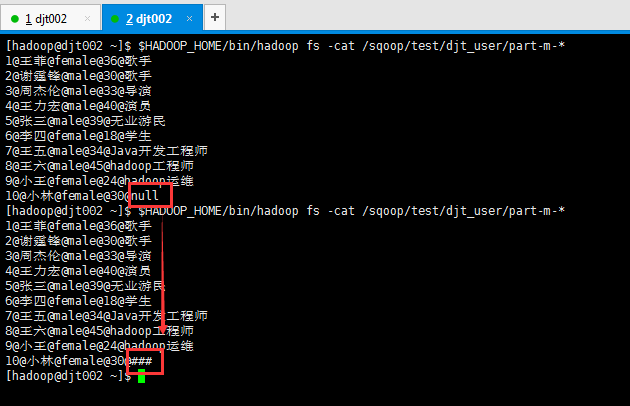
[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
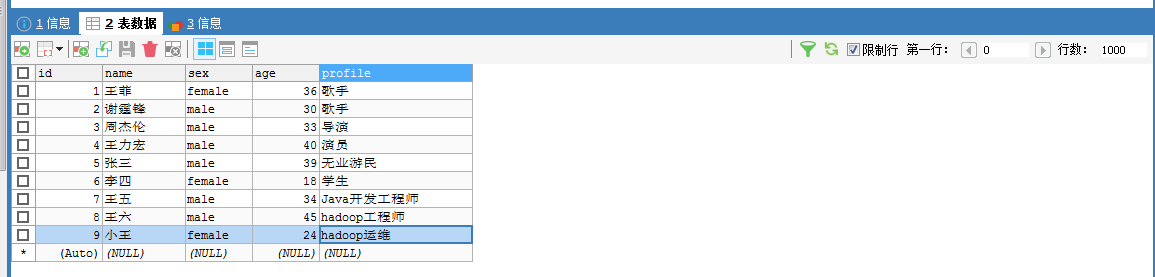
下面呢,这个场景,比如,如下,我不需全部的字段导出,非空值的某部分字段呢,该如何操作啊?
Sqoop Import 应用场景——导入部分数据
(1)使用–columns
即,指定某个或某些字段导入
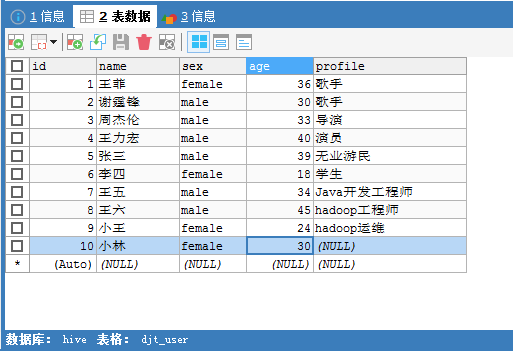
比如,我这里,指定只导入id和name,当然,你可以去指定更多,我这里只是个参考和带入门的引子实例罢了。
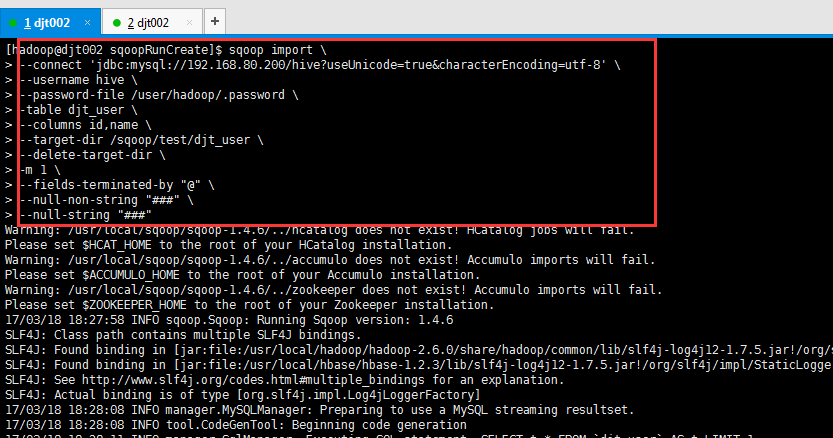
[hadoop@djt002 sqoopRunCreate]$ sqoop import \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> -table djt_user \
> --columns id,name \
> --target-dir /sqoop/test/djt_user \
> --delete-target-dir \
> -m 1 \
> --fields-terminated-by "@" \
> --null-non-string "###" \
> --null-string "###"
这里,djt_user是在MySQL里,通过Sqoop工具,导入到HDFS里,是在/sqoop/test/djt_user。

[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
1@王菲
2@谢霆锋
3@周杰伦
4@王力宏
5@张三
6@李四
7@王五
8@王六
9@小王
10@小林
[hadoop@djt002 ~]$
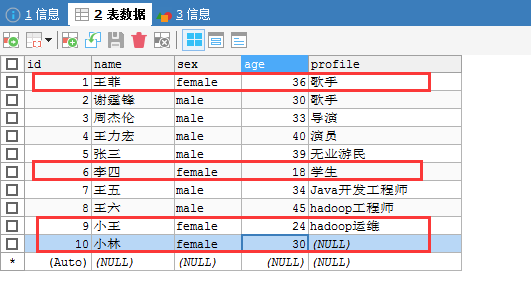
(2)使用–where
刚是导入指定的字段,也可以用筛选来导入达到目的。
比如,我这里,只想导入sex=female的。
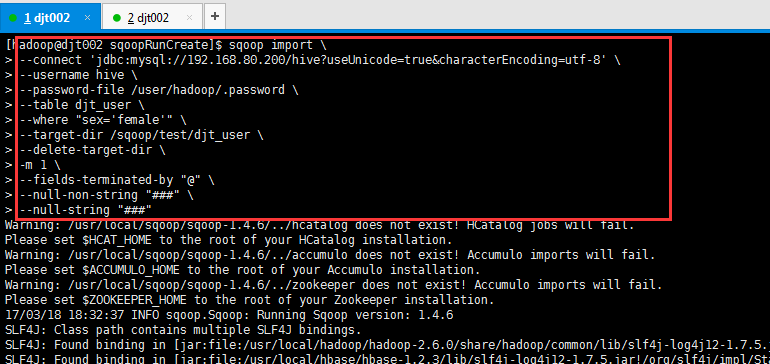
[hadoop@djt002 sqoopRunCreate]$ sqoop import \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user \
> --where "sex='female'" \
> --target-dir /sqoop/test/djt_user \
> --delete-target-dir \
> -m 1 \
> --fields-terminated-by "@" \
> --null-non-string "###" \
> --null-string "###"
这里,djt_user是在MySQL里,通过Sqoop工具,导入到HDFS里,是在/sqoop/test/djt_user。
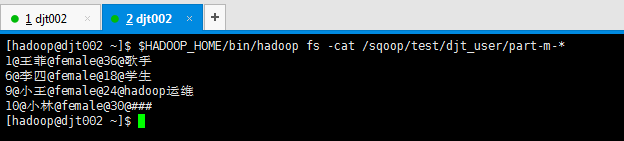
[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
1@王菲@female@36@歌手
6@李四@female@18@学生
9@小王@female@24@hadoop运维
10@小林@female@30@###
[hadoop@djt002 ~]$
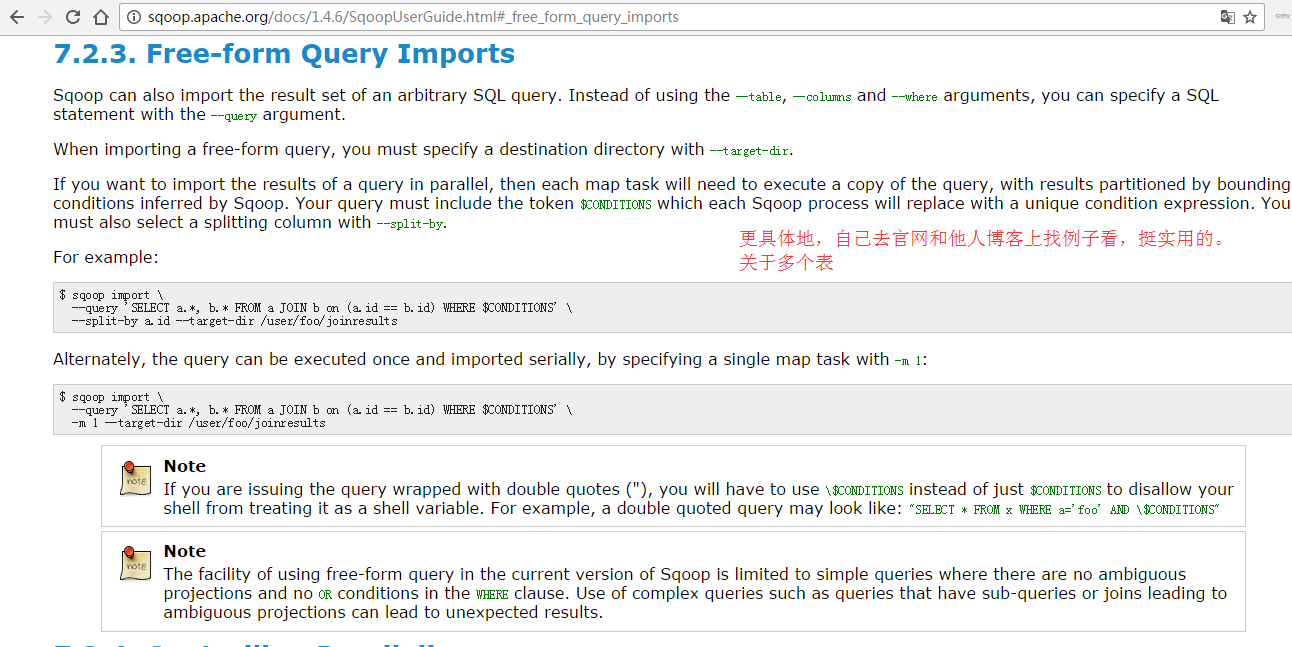
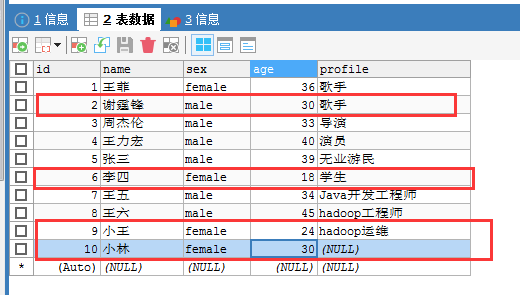
(3)使用–query
比如,导入比较复杂更实用。
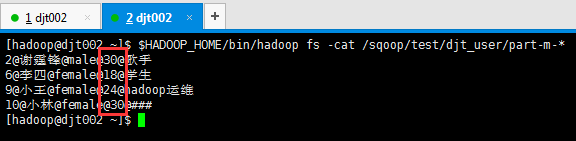
[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
2@谢霆锋@male@30@歌手
6@李四@female@18@学生
9@小王@female@24@hadoop运维
10@小林@female@30@###
[hadoop@djt002 ~]$
注意
若,从MySQL数据库导入数据到HDFS里,出现中断情况了怎么办?
答:好比MapReduce作业丢失一样,有个容错机制。但是这里,我们不用担心,任务中断导致数据重复插入,这个不需担心。
它这里呢,要么就是全部导入才成功,要么就是一条都导不进不成功。
即,Sqoop Import HDFS 里没有“脏数据”的情况发生。
MySQL里的数据通过Sqoop import HDFS(作为扩展)
下面我们看一下 Sqoop 如何使用命令行来导入数据的,其命令行语法如下所示。
sqoop import \
--connect jdbc:mysql://192.168.80.128:3306/db_hadoop \
--username sqoop \
--password sqoop \
--table user \
--target-dir /junior/sqoop/ \ //可选,不指定目录,数据默认导入到/user下
--where "sex='female'" \ //可选
--as-sequencefile \ //可选,不指定格式,数据格式默认为 Text 文本格式
--num-mappers 10 \ //可选,这个数值不宜太大
--null-string '\\N' \ //可选
--null-non-string '\\N' \ //可选
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名。
--table:要读取的数据库表。
--target-dir:将数据导入到指定的 HDFS 目录下,文件名称如果不指定的话,会默认数据库的表名称。
--where:过滤从数据库中要导入的数据。
--as-sequencefile:指定数据导入数据格式。
--num-mappers:指定 Map 任务的并发度。
--null-string,--null-non-string:同时使用可以将数据库中的空字段转化为'\N',因为数据库中字段为 null,会占用很大的空间。
下面我们介绍几种 Sqoop 数据导入的特殊应用(作为扩展)
1、Sqoop 每次导入数据的时候,不需要把以往的所有数据重新导入 HDFS,只需要把新增的数据导入 HDFS 即可,下面我们来看看如何导入新增数据。
sqoop import \
--connect jdbc:mysql://192.168.80.128:3306/db_hadoop \
--username sqoop \
--password sqoop \
--table user \
--incremental append \ //代表只导入增量数据
--check-column id \ //以主键id作为判断条件
--last-value 999 //导入id大于999的新增数据
上述三个组合使用,可以实现数据的增量导入。
2、Sqoop 数据导入过程中,直接输入明码存在安全隐患,我们可以通过下面两种方式规避这种风险。
1)-P:sqoop 命令行最后使用 -P,此时提示用户输入密码,而且用户输入的密码是看不见的,起到安全保护作用。密码输入正确后,才会执行 sqoop 命令。
sqoop import \
--connect jdbc:mysql://192.168.80.128:3306/db_hadoop \
--username sqoop \
--table user \
-P
2)--password-file:指定一个密码保存文件,读取密码。我们可以将这个文件设置为只有自己可读的文件,防止密码泄露。
sqoop import \
--connect jdbc:mysql://192.168.80.128:3306/db_hadoop \
--username sqoop \
--table user \
--password-file my-sqoop-password
二、通过Sqoop Export HDFS里的数据到MySQL
它的功能是将数据从 HDFS 导入关系型数据库表中,其流程图如下所示。
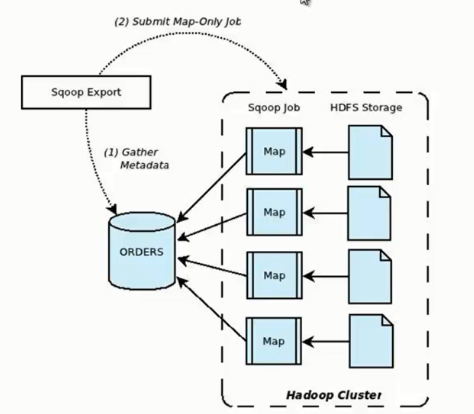
我们来分析一下 Sqoop 数据导出流程,首先用户输入一个 Sqoop export 命令,它会获取关系型数据库的 schema,
建立 Hadoop 字段与数据库表字段的映射关系。 然后会将输入命令转化为基于 Map 的 MapReduce作业,
这样 MapReduce作业中有很多 Map 任务,它们并行的从 HDFS 读取数据,并将整个数据拷贝到数据库中。

大家,必须要去看官网!
Sqoop Export 应用场景——直接导出
直接导出
请去看我下面的这篇博客,对你有好处。我不多赘述。
SQLyog普通版与SQLyog企业版对比分析

CREATE TABLE djt_user_copy SELECT * FROM djt_user WHERE 1=2;
[hadoop@djt002 sqoopRunCreate]$ sqoop export \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user_copy \
> --export-dir /sqoop/test/djt_user \
> --input-fields-terminated-by "@"
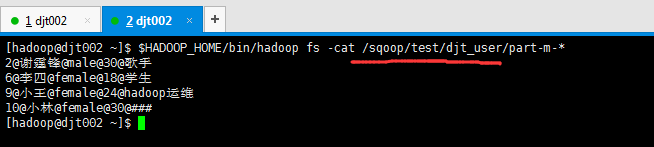
这里,HDFS里,是在/sqoop/test/djt_user,通过Sqoop工具,导出到djt_user_copy是在MySQL里。
因为啊,之前,/sqoop/test/djt_user的数据如下
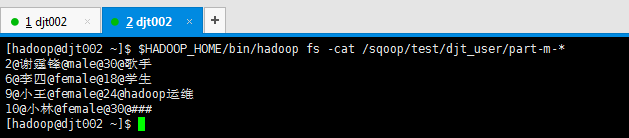

Sqoop Export 应用场景——指定map数
指定map数
Map Task默认是4个

[hadoop@djt002 sqoopRunCreate]$ sqoop export \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user_copy \
> --export-dir /sqoop/test/djt_user \
> --input-fields-terminated-by "@" \
> -m 1
这里,HDFS里,是在/sqoop/test/djt_user,通过Sqoop工具,导出到djt_user_copy是在MySQL里。
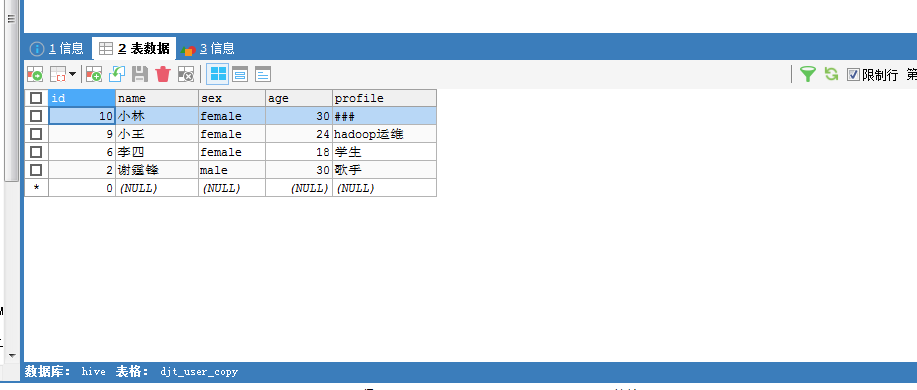
Sqoop Export 应用场景——插入和更新
插入和更新

[hadoop@djt002 sqoopRunCreate]$ sqoop export \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user_copy \
> --export-dir /sqoop/test/djt_user \
> --input-fields-terminated-by "@" \
> -m 1 \
> --update-key id \
> --update-mode allowinsert
这里,HDFS里,是在/sqoop/test/djt_user,通过Sqoop工具,导出到djt_user_copy是在MySQL里。
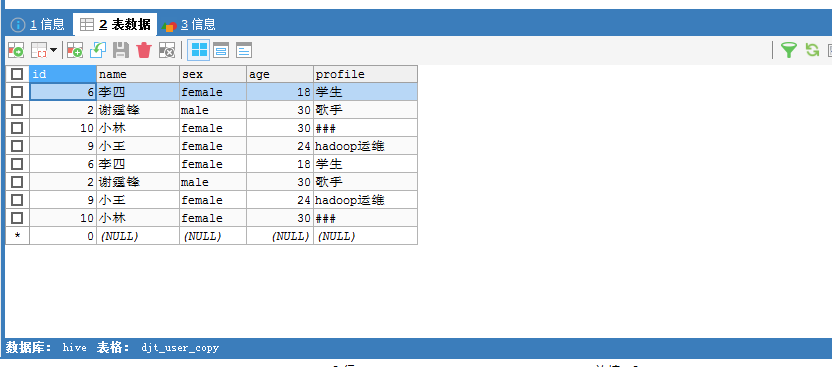
Sqoop Export 应用场景——事务处理
事务处理
比如,从HDFS里导出到MySQL。这个时候可能会出现意外情况,如出现中断,则会出现“脏数据”重复情况。
则提供了这个事务处理。
即 HDFS -> 先导出到 中间表(成功才可以,后续导出) -> MySQL
我这里是, /sqoop/test/djt_user (在HDFS里) -> djt_user_copy_tmp (在MySQL里) -> djt_user_copy (在MySQL里)
这里,HDFS里,是在/sqoop/test/djt_user,通过Sqoop工具,导出到djt_user_copy是在MySQL里。
注意这个中间表,需要创建djt_user_copy_tmp


[hadoop@djt002 sqoopRunCreate]$ sqoop export \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user_copy \
> --staging-table djt_user_copy_tmp \
> --clear-staging-table \
> --export-dir /sqoop/test/djt_user \
> -input-fields-terminated-by "@"
这里,HDFS里,是在/sqoop/test/djt_user,通过Sqoop工具,先导出到中间表djt_user_copy_tmp是在MySQL里,再继续导出到djt_user_copy是在MySQL里。
因为,此刻HDFS里的
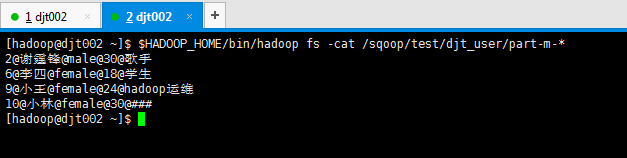

再次做测试,假设,我现在,把MySQL里的djt_user数据导入到HDFS里的/sqoop/test/djt_user。


[hadoop@djt002 sqoopRunCreate]$ sqoop import --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' --username hive --password-file /user/hadoop/.password -table djt_user --target-dir /sqoop/test/djt_user --delete-target-dir -m 1 --fields-terminated-by "@" --null-non-string "###" --null-string "###"
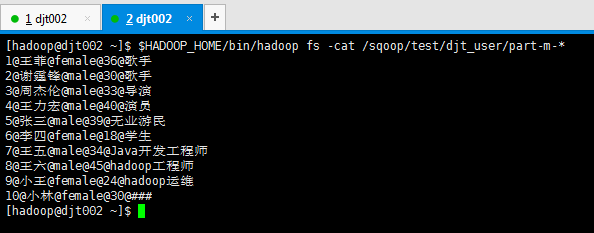
[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop fs -cat /sqoop/test/djt_user/part-m-*
1@王菲@female@36@歌手
2@谢霆锋@male@30@歌手
3@周杰伦@male@33@导演
4@王力宏@male@40@演员
5@张三@male@39@无业游民
6@李四@female@18@学生
7@王五@male@34@Java开发工程师
8@王六@male@45@hadoop工程师
9@小王@female@24@hadoop运维
10@小林@female@30@###
[hadoop@djt002 ~]$
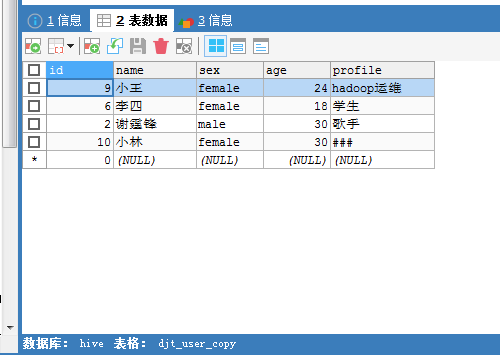
然后,接着,我们把HDFS里的/sqoop/test/djt_user 导出到 MySQL里的 djt_user_copydjt_user_copy。
说白了,就是再次做了一下 Sqoop Export 应用场景——事务处理。(自己好好理清思路去)
即 HDFS -> 先导出到 中间表(成功才可以,后续导出) -> MySQL
我这里是, /sqoop/test/djt_user(在HDFS里) -> djt_user_copy_tmp (在MySQL里) -> djt_user_copydjt_user_copy (在MySQL里)
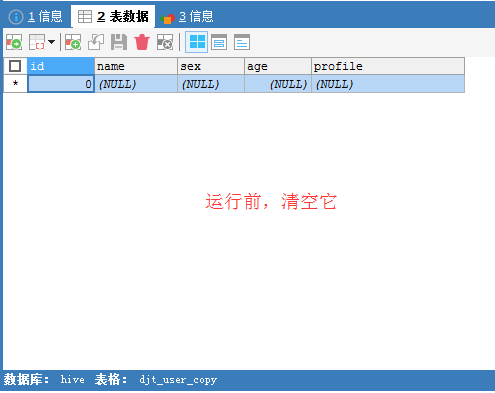

[hadoop@djt002 sqoopRunCreate]$ sqoop export \
> --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' \
> --username hive \
> --password-file /user/hadoop/.password \
> --table djt_user_copy \
> --staging-table djt_user_copy_tmp \
> --clear-staging-table \
> --export-dir /sqoop/test/djt_user \
> -input-fields-terminated-by "@"
这里,HDFS里,是在/sqoop/test/djt_user,通过Sqoop工具,先导出到中间表djt_user_copy_tmp是在MySQL里,再继续导出到djt_user_copy是在MySQL里。
因为,HDFS里的
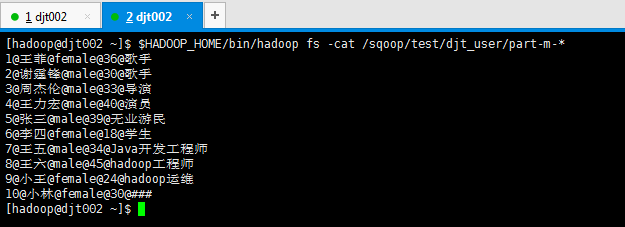
得到,
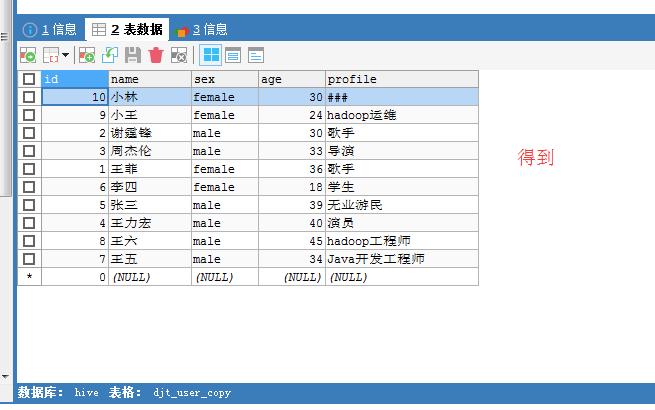
Sqoop Export HDFS 应用场景——字段不对应问题
字段不对应问题
因为,在Sqoop import时,我们有选择性的导入某个字段或某些字段对吧,那么,同样,对于Sqoop export也是一样!
[hadoop@djt002 sqoopRunCreate]$ sqoop import --connect 'jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8' --username hive --password-file /user/hadoop/.password -table djt_user --columns name,sex,age,profile --target-dir /sqoop/test/djt_user --delete-target-dir -m 1 --fields-terminated-by "@" --null-non-string "###" --null-string "###"
比如,HDFS里(的/sqoop/test/djt_user/)有4列, 数据库里(的djt_user_copy)有5列(因为会多出自增键)。那么,如何来处理这个棘手问题呢?
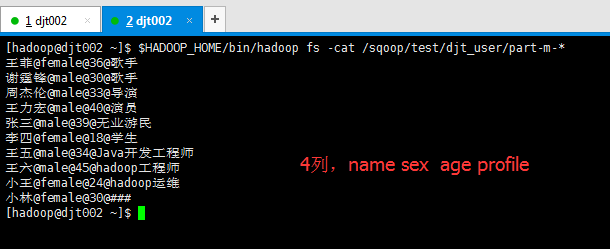
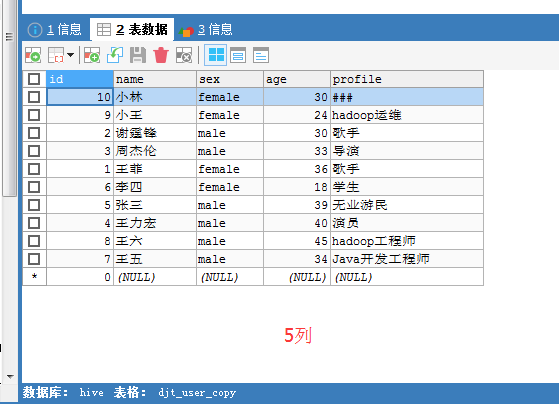
这样来处理,
照样sqoop export里也有 -columns name,sex,age,profile \
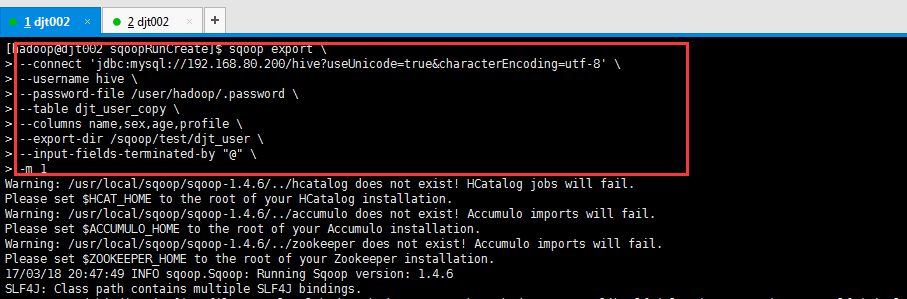
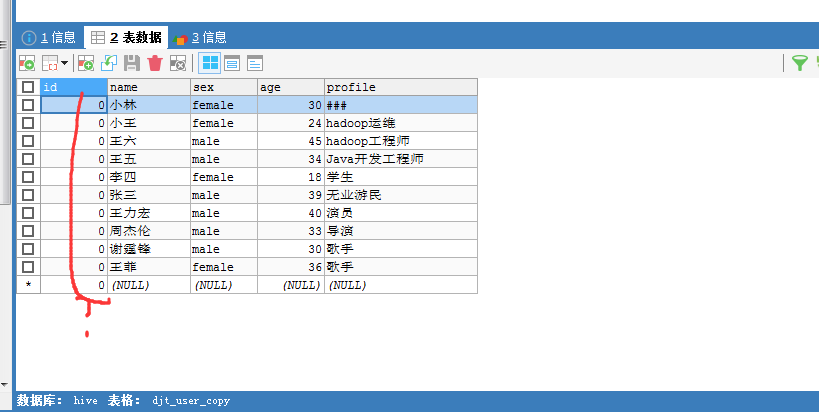
我的这里,自增键呢?/
通过Sqoop Export HDFS里的数据到MySQL(作为扩展)
下面我们看一下 Sqoop 如何使用命令行来导出数据的,其命令行语法如下所示。
sqoop export \
--connect jdbc:mysql://192.168.80.128:3306/db_hadoop \
--username sqoop \
--password sqoop \
--table user \
--export-dir user
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名和密码。
--table:要导入的数据库表。
--export-dir:数据在 HDFS 上的存放目录。
下面我们介绍几种 Sqoop 数据导出的特殊应用(作为扩展)
1、Sqoop export 将数据导入数据库,一般情况下是一条一条导入的,这样导入的效率非常低。这时我们可以使用 Sqoop export 的批量导入提高效率,其具体语法如下。
sqoop export \
--Dsqoop.export.records.per.statement=10 \
--connect jdbc:mysql://192.168.80.128:3306/db_hadoop \
--username sqoop \
--password sqoop \
--table user \
--export-dir user \
--batch
--Dsqoop.export.records.per.statement:指定每次导入10条数据,--batch:指定是批量导入。
2、在实际应用中还存在这样一个问题,比如导入数据的时候,Map Task 执行失败,
那么该 Map 任务会转移到另外一个节点执行重新运行,这时候之前导入的数据又要重新导入一份,造成数据重复导入。
因为 Map Task 没有回滚策略,一旦运行失败,已经导入数据库中的数据就无法恢复。
Sqoop export 提供了一种机制能保证原子性, 使用--staging-table 选项指定临时导入的表。
Sqoop export 导出数据的时候会分为两步:
第一步,将数据导入数据库中的临时表,如果导入期间 Map Task 失败,会删除临时表数据重新导入;
第二步,确认所有 Map Task 任务成功后,会将临时表名称为指定的表名称。
sqoop export \
--connect jdbc:mysql://192.168.80.128:3306/db_hadoop \
--username sqoop \
--password sqoop \
--table user \
--staging-table staging_user
3、在 Sqoop 导出数据过程中,如果我们想更新已有数据,可以采取以下两种方式。
1)通过 --update-key id 更新已有数据。
sqoop export \
--connect jdbc:mysql://192.168.80.128:3306/db_hadoop \
--username sqoop \
--password sqoop \
--table user \
--update-key id
2) 使用 --update-key id和--update-mode allowinsert 两个选项的情况下,如果数据已经存在,则更新数据,如果数据不存在,则插入新数据记录。
sqoop export \
--connect jdbc:mysql://192.168.80.128.:3306/db_hadoop \
--username sqoop \
--password sqoop \
--table user \
--update-key id \
--update-mode allowinsert
4、如果 HDFS 中的数据量比较大,很多字段并不需要,我们可以使用 --columns 来指定插入某几列数据。
sqoop export \
--connect jdbc:mysql://192.168.80.128:3306/db_hadoop \
--username sqoop \
--password sqoop \
--table user \
--column username,sex
5、当导入的字段数据不存在或者为null的时候,我们使用--input-null-string和--input-null-non-string 来处理。
sqoop export \
--connect jdbc:mysql://129.168.80.128:3306/db_hadoop \
--username sqoop \
--password sqoop \
--table user \
--input-null-string '\\N' \
--input-null-non-string '\\N'
推荐博客
http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html (sqoop官网文档)
http://blog.csdn.net/aaronhadoop/article/details/26713431
最新文章
- NPOI操作EXCEL(一)——npoi基础
- 下拉tableView实现类似微信中带图的灰色背景
- mongoVUE1.5.3 破解方法
- BZOJ 1449 球队收益(最小费用最大流)
- HDU 5693 D Game 区间dp
- 【M19】了解临时对象的来源
- bellman_ford算法
- iOS 导航栏不可点击
- Win10电脑经常自动掉线、自动断网的解决方法
- 移动端布局方案汇总&&原理解析
- 彻底删除mysql服务(清理注册表)
- 写一个ORM框架的第一步(Apache Commons DbUtils)
- pip 安装指定版本软件包
- hdu 2149 (巴什博奕)
- shiro的基本认识及做一个简单的授权登陆的例子
- 【转】使用SevenZipSharp压缩、解压文件
- Maven3版本的超级POM位置及中央仓库位置
- 4.1.2 A Funny Game(POJ 2484)
- Hadoop基本介绍
- 通过直接编码添加折线图到ChartControl