Spark 2.2.0 分布式集群环境搭建
集群机器:
1台 装了 ubuntu 14.04的 台式机
1台 装了ubuntu 16.04 的 笔记本 (机器更多时同样适用)
1.需要安装好Hadoop分布式环境
参照:Hadoop分类 -->http://www.cnblogs.com/soyo/p/7868282.html
2.安装Spark2.2.0 到/usr/local2
sudo chmod -R 777 Spark( 此/usr/local2路径下的被解压的spark("spark"名字是自己改的) )
3.配置环境变量
vim ~/.bashrc
添加:
export SPARK_HOME=/usr/local2/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin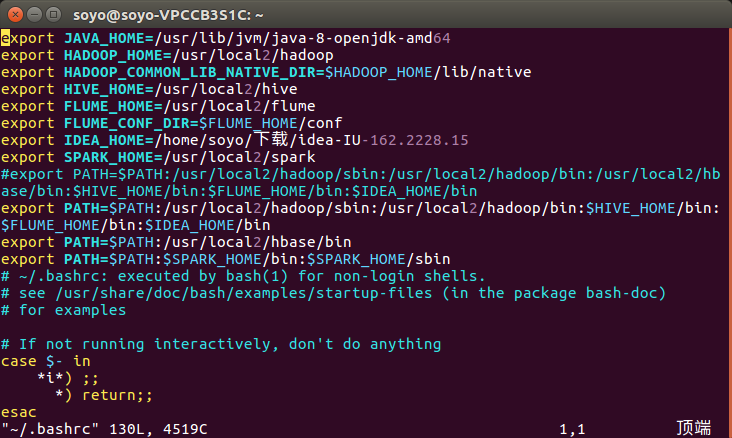
source ~/.bashrc
4.Spark分布式配置:
在Master节点主机上进行如下操作:
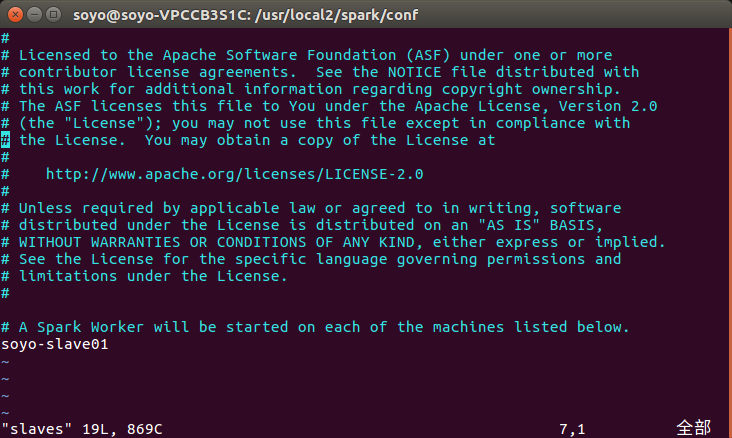
1.配置 slaves:slaves文件设置Worker节点
cd /usr/local2/spark/conf
cp ./slaves.template ./slaves
vim slaves
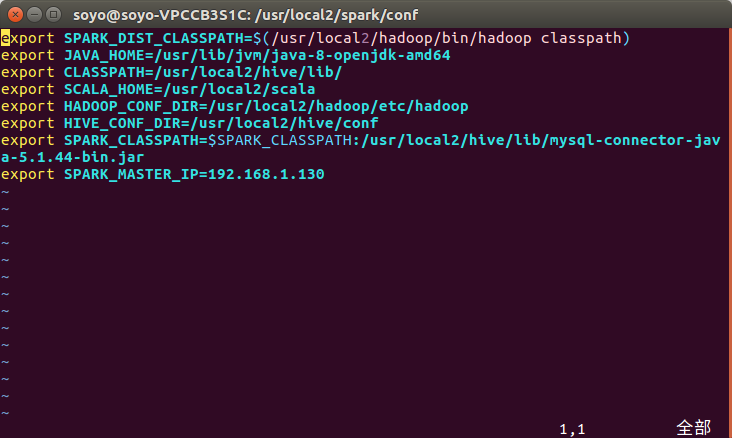
2.配置 spark-env.sh (刚开始这个文件也是没有的)( cp ./spark-env.sh.template ./spark-env.sh)
这里就加了 export SPARK_MASTER_IP=192.168.1.130 (别的是以前在非分布式情况下使用Spark需要时添加的)
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
4.给节点分发Spark配置:
cd /usr/local2
tar -zcf ~/ spark.tar.gz ./spark
cd ~
scp ./spark.tar.gz soyo-slave01:/home/soyo
在soyo-slave01节点上分别执行下面同样的操作:
sudo tar -zxf spark.tar.gz -C /usr/local2
sudo chmod -R 777 spark
4.启动Spark集群:
4.1先启动分布式Hadoop:
在master节点执行:start-all.sh
4.2启动Spark:
启动Master节点:
在master节点执行:start-master.sh (在soyo-VPCCB3S1C节点执行jps:多了Master这个进程)

启动slave节点:
在master节点执行:start-slaves.sh (在soyo-slave01节点执行jps:多了Worker这个进程)

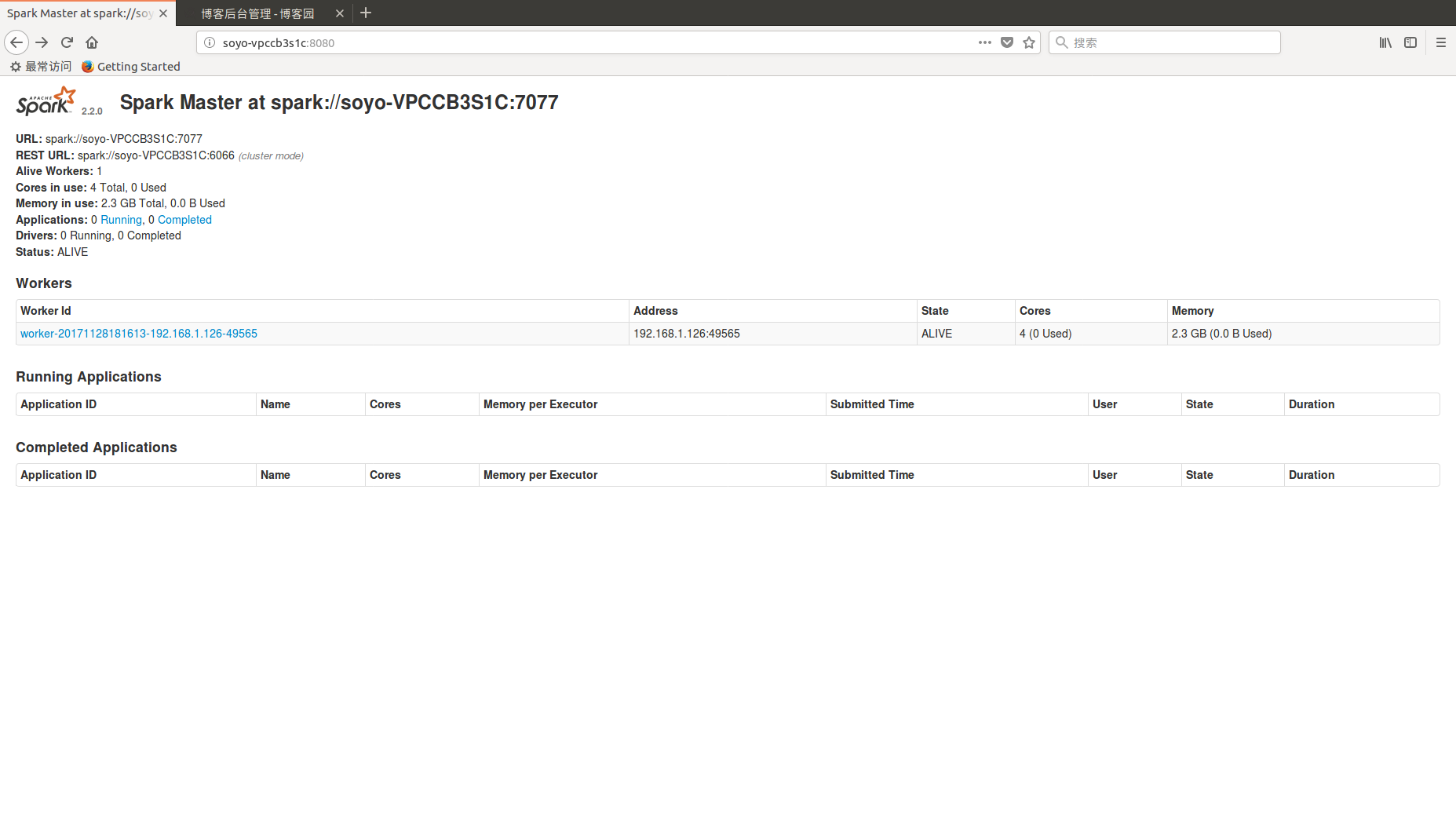
4.3在浏览器上查看Spark独立集群管理器的集群信息
http://soyo-vpccb3s1c:8080/
4.关闭Spark集群:

最新文章
- set和enum类型的用法和区别
- 高性能网站架构设计之缓存篇(6)- Redis 集群(中)
- PyCharm/IntelliJ IDEA Golang开发环境搭建(最方便快捷的GO语言开发环境)
- 如何理解css中的float
- 扫描函数sweep
- Responsive布局技巧
- ADO.NET(很精彩全面)
- 讲解HTML服务器推送相关技术知识(转)
- pcap 安装(debian7 linux) qt 使用pcap.h
- 用Markdown优雅的渲染我们的网页
- 一些收费的vpn或ssh代理
- jquery1.7.2的源码分析(六)基本功能
- Binary Tree Level Order Traversal II 解答
- HDU 1074 Doing Homework(状态压缩)
- elasticsearch的percolator操作
- 带着萌新看springboot源码13(手写一个自己的starter)
- Ubuntu16.04安装Redis并配置
- axure原型设计
- 零基础python入门(1)
- 运行 python *.py 文件出错,如:python a.py