吴裕雄--天生自然python编程:实例(2)
2024-10-07 06:43:32
list1 = [10, 20, 4, 45, 99]
list1.sort() print("最小元素为:", *list1[:1])
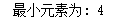
list1 = [10, 20, 1, 45, 99]
print("最小元素为:", min(list1))
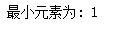
list1 = [10, 20, 4, 45, 99]
list1.sort()
print("最大元素为:", list1[-1])
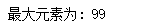
list1 = [10, 20, 1, 45, 99]
print("最大元素为:", max(list1))
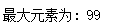
test_str = "Runoob" # 输出原始字符串
print ("原始字符串为 : " + test_str) # 移除第三个字符 n
new_str = "" for i in range(0, len(test_str)):
if i != 2:
new_str = new_str + test_str[i] print ("字符串移除后为 : " + new_str)

def check(string, sub_str):
if (string.find(sub_str) == -1):
print("不存在!")
else:
print("存在!") string = "www.runoob.com"
sub_str ="runoob"
check(string, sub_str)

str = "runoob"
print(len(str))

def findLen(str):
counter = 0
while str[counter:]:
counter += 1
return counter str = "runoob"
print(findLen(str))

import re def Find(string):
# findall() 查找匹配正则表达式的字符串
url = re.findall('https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+', string)
return url string = 'Runoob 的网页地址为:https://www.runoob.com,Google 的网页地址为:https://www.google.com'
print("Urls: ", Find(string))
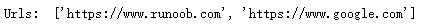
def exec_code():
LOC = """
def factorial(num):
fact=1
for i in range(1,num+1):
fact = fact*i
return fact
print(factorial(5))
"""
exec(LOC) exec_code()
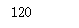
str='Runoob'
print(str[::-1])

str='Runoob'
print(''.join(reversed(str)))
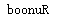
def rotate(input,d):
Lfirst = input[0 : d]
Lsecond = input[d :]
Rfirst = input[0 : len(input)-d]
Rsecond = input[len(input)-d : ]
print( "头部切片翻转 : ", (Lsecond + Lfirst) )
print( "尾部切片翻转 : ", (Rsecond + Rfirst) ) if __name__ == "__main__":
input = 'Runoob'
d=2 # 截取两个字符
rotate(input,d)

def dictionairy():
# 声明字典
key_value ={} # 初始化
key_value[2] = 56
key_value[1] = 2
key_value[5] = 12
key_value[4] = 24
key_value[6] = 18
key_value[3] = 323
print ("按键(key)排序:")
# sorted(key_value) 返回一个迭代器
# 字典按键排序
for i in sorted (key_value) :
print ((i, key_value[i]), end =" ") def main():
# 调用函数
dictionairy() # 主函数
if __name__=="__main__":
main()
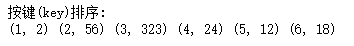
def dictionairy():
# 声明字典
key_value ={}
# 初始化
key_value[2] = 56
key_value[1] = 2
key_value[5] = 12
key_value[4] = 24
key_value[6] = 18
key_value[3] = 323
print ("按值(value)排序:")
print(sorted(key_value.items(), key = lambda kv:(kv[1], kv[0]))) def main():
dictionairy() if __name__=="__main__":
main()

lis = [{ "name" : "Taobao", "age" : 100},
{ "name" : "Runoob", "age" : 7 },
{ "name" : "Google", "age" : 100 },
{ "name" : "Wiki" , "age" : 200 }]
# 通过 age 升序排序
print ("列表通过 age 升序排序: ")
print (sorted(lis, key = lambda i: i['age']) )
print ("\r")
# 先按 age 排序,再按 name 排序
print ("列表通过 age 和 name 排序: ")
print (sorted(lis, key = lambda i: (i['age'], i['name'])) )
print ("\r")
# 按 age 降序排序
print ("列表通过 age 降序排序: ")
print (sorted(lis, key = lambda i: i['age'],reverse=True) )

def returnSum(myDict):
sum = 0
for i in myDict:
sum = sum + myDict[i]
return sum dict = {'a': 100, 'b':200, 'c':300}
print("Sum :", returnSum(dict))
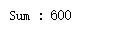
test_dict = {"Runoob" : 1, "Google" : 2, "Taobao" : 3, "Zhihu" : 4}
# 输出原始的字典
print ("字典移除前 : " + str(test_dict))
# 使用 del 移除 Zhihu
del test_dict['Zhihu']
# 输出移除后的字典
print ("字典移除后 : " + str(test_dict))
# 移除没有的 key 会报错
#del test_dict['Baidu']
test_dict = {"Runoob" : 1, "Google" : 2, "Taobao" : 3, "Zhihu" : 4}
# 输出原始的字典
print ("字典移除前 : ")
print(test_dict)
# 使用 del 移除 Zhihu
del test_dict['Zhihu']
# 移除没有的 key 会报错
#del test_dict['Baidu']
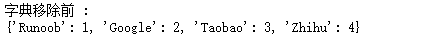
def Merge(dict1, dict2):
return(dict2.update(dict1)) # 两个字典
dict1 = {'a': 10, 'b': 8}
dict2 = {'d': 6, 'c': 4} # 返回 None
print(Merge(dict1, dict2)) # dict2 合并了 dict1
print(dict2)
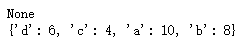
def Merge(dict1, dict2):
res = {**dict1, **dict2}
return res # 两个字典
dict1 = {'a': 10, 'b': 8}
dict2 = {'d': 6, 'c': 4}
dict3 = Merge(dict1, dict2)
print(dict3)
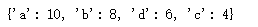
import time a1 = "2019-5-10 23:40:00"
# 先转换为时间数组
timeArray = time.strptime(a1, "%Y-%m-%d %H:%M:%S") # 转换为时间戳
timeStamp = int(time.mktime(timeArray))
print(timeStamp) # 格式转换 - 转为 /
a2 = "2019/5/10 23:40:00"
# 先转换为时间数组,然后转换为其他格式
timeArray = time.strptime(a2, "%Y/%m/%d %H:%M:%S")
otherStyleTime = time.strftime("%Y/%m/%d %H:%M:%S", timeArray)
print(otherStyleTime)

import time
import datetime # 先获得时间数组格式的日期
threeDayAgo = (datetime.datetime.now() - datetime.timedelta(days = 3))
# 转换为时间戳
timeStamp = int(time.mktime(threeDayAgo.timetuple()))
# 转换为其他字符串格式
otherStyleTime = threeDayAgo.strftime("%Y-%m-%d %H:%M:%S")
print(otherStyleTime)

import time
import datetime #给定时间戳
timeStamp = 1557502800
dateArray = datetime.datetime.utcfromtimestamp(timeStamp)
threeDayAgo = dateArray - datetime.timedelta(days = 3)
print(threeDayAgo)
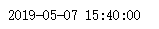
import time # 获得当前时间时间戳
now = int(time.time())
#转换为其他日期格式,如:"%Y-%m-%d %H:%M:%S"
timeArray = time.localtime(now)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(otherStyleTime)

import datetime # 获得当前时间
now = datetime.datetime.now()
# 转换为指定的格式
otherStyleTime = now.strftime("%Y-%m-%d %H:%M:%S")
print(otherStyleTime)
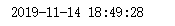
import time timeStamp = 1557502800
timeArray = time.localtime(timeStamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(otherStyleTime)

import datetime timeStamp = 1557502800
dateArray = datetime.datetime.utcfromtimestamp(timeStamp)
otherStyleTime = dateArray.strftime("%Y-%m-%d %H:%M:%S")
print(otherStyleTime)
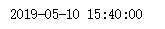
name = "RUNOOB" # 接收用户输入
# name = input("输入你的名字: \n\n") lngth = len(name)
l = "" for x in range(0, lngth):
c = name[x]
c = c.upper() if (c == "A"):
print("..######..\n..#....#..\n..######..", end = " ")
print("\n..#....#..\n..#....#..\n\n") elif (c == "B"):
print("..######..\n..#....#..\n..#####...", end = " ")
print("\n..#....#..\n..######..\n\n") elif (c == "C"):
print("..######..\n..#.......\n..#.......", end = " ")
print("\n..#.......\n..######..\n\n") elif (c == "D"):
print("..#####...\n..#....#..\n..#....#..", end = " ")
print("\n..#....#..\n..#####...\n\n") elif (c == "E"):
print("..######..\n..#.......\n..#####...", end = " ")
print("\n..#.......\n..######..\n\n") elif (c == "F"):
print("..######..\n..#.......\n..#####...", end = " ")
print("\n..#.......\n..#.......\n\n") elif (c == "G"):
print("..######..\n..#.......\n..#.####..", end = " ")
print("\n..#....#..\n..#####...\n\n") elif (c == "H"):
print("..#....#..\n..#....#..\n..######..", end = " ")
print("\n..#....#..\n..#....#..\n\n") elif (c == "I"):
print("..######..\n....##....\n....##....", end = " ")
print("\n....##....\n..######..\n\n") elif (c == "J"):
print("..######..\n....##....\n....##....", end = " ")
print("\n..#.##....\n..####....\n\n") elif (c == "K"):
print("..#...#...\n..#..#....\n..##......", end = " ")
print("\n..#..#....\n..#...#...\n\n") elif (c == "L"):
print("..#.......\n..#.......\n..#.......", end = " ")
print("\n..#.......\n..######..\n\n") elif (c == "M"):
print("..#....#..\n..##..##..\n..#.##.#..", end = " ")
print("\n..#....#..\n..#....#..\n\n") elif (c == "N"):
print("..#....#..\n..##...#..\n..#.#..#..", end = " ")
print("\n..#..#.#..\n..#...##..\n\n") elif (c == "O"):
print("..######..\n..#....#..\n..#....#..", end = " ")
print("\n..#....#..\n..######..\n\n") elif (c == "P"):
print("..######..\n..#....#..\n..######..", end = " ")
print("\n..#.......\n..#.......\n\n") elif (c == "Q"):
print("..######..\n..#....#..\n..#.#..#..", end = " ")
print("\n..#..#.#..\n..######..\n\n") elif (c == "R"):
print("..######..\n..#....#..\n..#.##...", end = " ")
print("\n..#...#...\n..#....#..\n\n") elif (c == "S"):
print("..######..\n..#.......\n..######..", end = " ")
print("\n.......#..\n..######..\n\n") elif (c == "T"):
print("..######..\n....##....\n....##....", end = " ")
print("\n....##....\n....##....\n\n") elif (c == "U"):
print("..#....#..\n..#....#..\n..#....#..", end = " ")
print("\n..#....#..\n..######..\n\n") elif (c == "V"):
print("..#....#..\n..#....#..\n..#....#..", end = " ")
print("\n...#..#...\n....##....\n\n") elif (c == "W"):
print("..#....#..\n..#....#..\n..#.##.#..", end = " ")
print("\n..##..##..\n..#....#..\n\n") elif (c == "X"):
print("..#....#..\n...#..#...\n....##....", end = " ")
print("\n...#..#...\n..#....#..\n\n") elif (c == "Y"):
print("..#....#..\n...#..#...\n....##....", end = " ")
print("\n....##....\n....##....\n\n") elif (c == "Z"):
print("..######..\n......#...\n.....#....", end = " ")
print("\n....#.....\n..######..\n\n") elif (c == " "):
print("..........\n..........\n..........", end = " ")
print("\n..........\n\n") elif (c == "."):
print("----..----\n\n")

最新文章
- View与Control间的数据交互
- mahout 安装测试
- asp.net 微信企业号办公系统-流程设计--保存与发布
- PLSQL_查询已执行SQL的绑定参数(案例)
- (转)Yale CAS + .net Client 实现 SSO(4)
- iOS - 文件操作(File Operating)
- POJ2222+暴力搜索
- common-httpclient 用户名密码认证示例
- 关于LEA指令(单周期就可以做简单的算术计算)
- Hbase 计数器
- 关于ubuntu 系统
- mybatis用logback日志不显示sql的解决办法
- nodejs 使用 ethers创建以太坊钱包
- Hive的DDL操作
- day059-60 ajax初识 登录认证练习 form装饰器, form和ajax上传文件 contentType
- SpringMVC参数绑定总结
- error: <item> inner element must either be a resource reference or empty.
- C和C指针小记(十五)-结构和联合
- mtr
- Toolbar 工具栏 菜单 标题栏 Menu
热门文章
- sklearn.metrics中的评估方法介绍(accuracy_score, recall_score, roc_curve, roc_auc_score, confusion_matrix)
- dotnet core 链接mongodb
- Java 工厂模式登陆系统实现
- HTML字符实体和转义字符串大全
- python爬虫破解带有CryptoJS的aes加密的反爬机制
- 创建Maven项目时Maven中的GroupID和ArtifactID的意思
- C++ malloc()函数的注意点及使用示例
- CodeForces 91B Queue (线段树,区间最值)
- 三十五、lamp经典组合搭建
- java 解析URL里的主域名及参数工具类