论文翻译:2020_Attention Wave-U-Net for Acoustic Echo Cancellation
论文地址:http://www.interspeech2020.org/uploadfile/pdf/Thu-1-10-10.pdf
Attention Wave-U-Net 的回声消除
摘要
提出了一种基于U-Net的具有注意机制的AEC方法,以联合抑制声学回声和背景噪声。该方法由U-Net、一个辅助编码器和一个注意网络组成。在该方法中,Wave-U-Net从混合语音中提取估计的近端语音,辅助编码器提取远端语音的潜在特征,其中相关特征通过注意机制提供给Wave-U-Net。利用注意网络,可以有效地抑制混合噪声中的回声。在TIMIT数据集上的实验结果表明,该方法在单讲周期的ERLE和双讲周期的PESQ评分方面均优于现有方法。此外,实验结果也验证了该方法对看不见的噪声条件的鲁棒性。
关键字:回声消除,Attention Wave-U-Net,辅助编码器,注意机制
1 引言
在许多应用中,如免提电话、音频/视频会议系统和助听器,声音回声是由于通信系统中扬声器和麦克风之间的耦合而产生的。也就是说,如果麦克风接收到扬声器发出的远端语音,远端用户就会听到自己声音的回声。在这种情况下,我们希望消除回声并只向远端用户传递干净的近端语音。此外,由于在诸如移动电话[1]等音频设备中小型化扬声器产生的非线性失真,抑制回声变得更具挑战性。
传统的声学回声消除方法是采用自适应滤波算法来预测从扬声器到麦克风的声学回声路径。为了在双讲、背景噪声共存或非线性回声出现时提高性能,人们提出了各种基于自适应滤波器的AEC算法。为了解决双讲问题,可以将自适应滤波器与双讲检测器相关联,在双讲过程中停止滤波器的自适应,或者采用“\(\ell_{1}\)范数最小化[2]”等鲁棒判据设计自适应滤波器本身,使其对双讲具有鲁棒性。当回声噪声和背景噪声并存时,噪声抑制模块是独立开发的,简单地与回声抑制模块串联在一起,整体性能依赖于其集成结构[3],因此性能不佳。此外,扩音器造成的非线性失真也可以引入到AEC系统中。为了克服这一困难,一些非线性模型如Volterra模型、Hammerstein模型和神经网络已经被使用[4]。尽管做了大量的工作,但自适应滤波方法在各种实际环境中仍然没有取得令人满意的效果。
近年来,DNN由于其复杂的非线性建模能力而备受关注,并且已成功应用于各种语音信号处理任务,例如语音增强,源分离和AEC。在AEC应用中,引入了基于DNN的残余回声抑制(RES),以通过使用残余回声和远端语音来估计最佳RES增益[5]。在[3]中,以一种顺序的方式堆叠DNN模型,一种用于噪声抑制,另一种用于声学回声抑制,被开发来同时抑制声学回声和背景噪声。此外,还提出了一种基于双向长期短期记忆(LSTM)的模型,以根据混合信号的幅度谱估计用于重新合成近端语音的理想比率掩码[6]。最近在[7]中提出了具有基于LSTM语音检测器的卷积递归网络(CRN),其中CRN根据远端语音和混合信号的频谱估计近端语音的复杂频谱图,并且基于LSTM语音检测器估计近端语音的活动,以进一步抑制残余回声并在单个通话期间降低噪声。在[8]中,引入了基于深度递归单元(GRU)的网络,该网络具有估计回声和近端语音的多任务学习。
然而,上述算法[3,5-8]大多是在短时傅里叶变换(STFT)域内执行的,这意味着由于性能对帧大小的依赖以及没有可用的正确相位信息[9]等原因,它们的性能可能会下降。为了解决这个问题,最近提出了几种基于时域的网络,它们在各个领域都表现出了优于STFT域网络的性能[9-11]。
受到时域方法成功的启发,我们提出了一种针对AEC应用程序的注意Wave-U-Net。 Wave-U-Net [9]在时域中运行,最初是为音频分离而设计的,其变体已成功应用于其他领域[11-13]。与Wave-U-Net相比,该方法包括一个辅助编码器,用于提取远端语音的特征。通过利用注意力机制[13],辅助编码器提取的特征被传递到Wave- U-Net中,该机制有效地抑制了潜在空间中的回声。实验结果验证了注意力机制的有效性。此外,还将显示,所提出的方法在可见和看不见的噪声条件下均产生相似的性能,从而验证了其针对看不见的噪声条件的鲁棒性。
本文主要内容如下:第2节,简要定义了AEC问题。然后,在第三节中提出了基于U-Net的注意机制。在第4节中,我们提供了几个在不同AEC环境下的实验结果来验证所提方法的性能。最后,第五节给出了结论。
2 问题陈述
在AEC应用中,混合信号\(y(n)\)由声学回声\(d(n)\)、近端语音\(s(n)\)和背景噪声\(v(n)\)组成,如下所示:
\]
声波回声\(d(n)\)也可以被扬声器非线性地失真,它是房间脉冲响应(RIR)对远端语音的修正。AEC的目的是通过联合抑制声学回声\(d(n)\)和背景噪声\(v(n)\),从混合物\(y(n)\)中估计干净的近端语音\(s(n)\)。
3 提出的attention Wave-U-Net
3.1 总体结构
在本节中,提出了用于AEC应用的注意Wave-U-Net,如图1所示。该结构由U-Net、辅助编码器和注意网络组成。在Wave-U-Net中,混合信号作为输入,近端语音作为输出估计。辅助编码器采用与U-Net相同的编码结构对远端语音进行编码,并通过注意网络将远端语音的意义特征传递给U-Net,有效地抑制了混合信号的回声。

图1 提出的注意Wave-U-Net的结构。在1D卷积块中,
括号中的三个数字分别代表1D卷积的通道数,内核大小和步幅。
原始Wave-U-Net和拟议的attention Wave-U-Net之间有几个明显的特征。首先,由于Wave-U-Net最初是为解决音频源分离问题而设计的;因此,它需要混合信号的单个输入,并提供分离信号的多个输出。在提出的方法中,attention Wave-U-Net在Wave-U-Net处接收混合信号,在辅助编码器处接收远端语音,并在Wave-U-Net处估计近端语音。其次,与原始的Wave-U-Net相比,拟议的注意力Wave-U-Net具有辅助编码器,可以产生远端语音的潜在特征。第三,在注意力机制的启发下[13],通过使用注意力网络来强调远端语音的有意义的特征。然后,将远端语音的重音特征与Wave-U-Net相同第I个编码器层中的混合音的特征串联在一起,并将这些级联特征通过Wave-U-Net的编码器以提取潜在空间中的相关特征。最后,利用从编码器提取的特征,通过Wave-U-Net的解码器恢复干净的近端语音。
3.2 注意网络
如上所述,所提出的体系结构利用注意力机制[13]从潜在空间中的远端语音中识别相关特征,从而提高了性能。如图2所示,首先使用内核大小为1且带有偏差项的一维卷积将第i层中远端语音的潜在特征和第(i-1)层中的混合语音的潜在特征映射到具有相同\(u\)维的中间特征空间。在这里,可以将\(u\)设置为两个输入通道尺寸中的最小值。通过指数线性单位(ELU)激活函数并将其相加后,通过使用另一个具有内核大小1和偏差项的一维卷积将它们另外映射到一维特征空间,以生成attention掩码。最后,将远端语音的特征与获得的attention掩码逐元素相乘,然后将掩码特征与Wave-U-Net的第i个编码器层的特征进行级联。
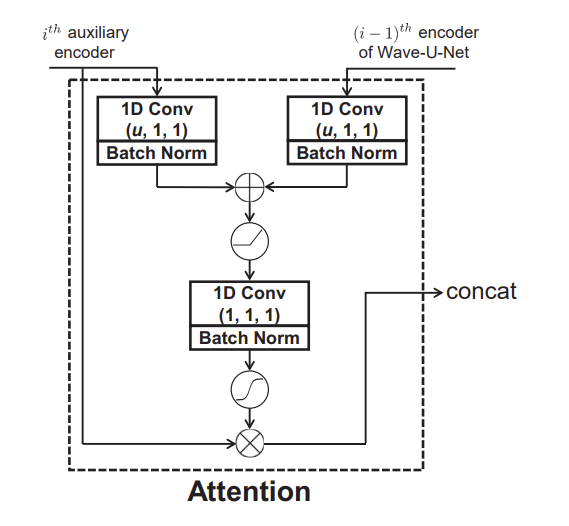
图2 attention 网络结构
3.3 损失函数
在回归任务中,信号失真比(SDR)作为损失函数已被广泛使用。因此,该算法最小化负SDR函数来训练attention Wave-U-Net。SDR函数定义如下:
\]
其中\(\|\cdot\|\)为\(\ell_{2}\)范数函数,\(\hat{s}(n)\)为估计的近端语音。
4 实验结果
4.1 实验设置
为了验证所提出的注意力Wave-U-Net的性能,对实验进行了与[7,8]中类似的设置。具体而言,TIMIT数据集被用作远端和近端语音。在总共630名演讲者中,随机选择了100对远端讲者(即40名男女,30名男性,30名女性-女性)进行训练。为了生成远端语音,将同一位远端讲话者的三个随机选择的语音连接在一起。对于每个近端语音,随机地选择一种话语,并通过填充零将其扩展到与远端信号相同的长度。对于每个远端讲话者,创建了五种不同的远端讲话,并且为每个近端讲话者生成了七种不同的近端讲话,这导致总共3500种训练混合(约9小时)。为了进行验证和测试,从剩余的430个扬声器中随机选择了30对远端和近端扬声器。这一次,将五种不同的近端语音与三种不同的远端语音混合在一起,分别得到450种混合验证和测试。为了模拟AEC系统的非线性,对远端信号\(x(n)\)进行剪切和失真,如下所示:
-x_{\max }, & \text { if } & x(n)<-x_{\max }, \\
x(n), & \text { if } & |x(n)| \leq x_{\max }, \\
x_{\max }, & \text { if } & x(n)>x_{\max }
\end{array}\right. (3)
\]
\]
其中\(x_{\max }\)设置为原始远端信号\(x(n)\)的最大幅度的0.8倍,\(b(n)=1.5 x_{\mathrm{cl}}(n)-0.3 x_{\mathrm{cl}}^{2}(n)\),并且
\]
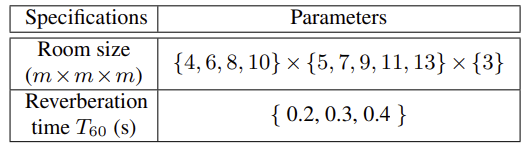
然后,将修改后的远端信号与随机选择的房间脉冲响应(RIR)卷积,利用[14]图像法生成房间脉冲响应。具体来说,生成200组RIRs用于训练,创建另外两组2组RIR s用于验证和测试。在生成RIR时,随机选取表1中的参数。另外,麦克风-扬声器的距离设置为1m, RIR的长度固定为512。
表1 生成RIR的规范
为了创建训练和验证混合物,将近端语音和声学回声以五种不同的信号回声比(SER)水平混合(即{−6,−3,0,3,6}dB)。在4个不同信噪比(SNR)水平(即{8,10,12,14}dB)下,对噪声进行随机剪切并与近端信号混合。为了测试,我们使用了三种不同的SERs({−1.5,1,5,4.5}dB)和信噪比({11,13,15}dB)来测试在失配条件下所提出方法的性能。此外,ITU-T建议501数据库[15]使用了10种可见噪声(即公共汽车,咖啡馆,汽车,建筑,孩子,地铁,办公室,铁路,餐厅,街道噪声)进行训练和验证。 并从NOISEX92数据库[16]中使用了7种类型的看不见的噪音(i.e., babble, bucaneer1, destroyer engine, f16,leopard, volvo, and white noises)进行测试。
最后,从单说话周期的回声损耗增强(ERLE)和双说话周期的语音质量感知评价(PESQ)两方面评价了所提注意波网的性能。
4.2 实验结果
为了验证所提出的注意力Wave-U-Net的性能,我们考虑了以下基于STFT域和时域的算法:对于基于STFT域的模型,我们考虑了堆叠DNN[3]和CRN[7];对于基于时域的模型,我们考虑了针对AEC问题进行改进的Wave-U-Net[9]。在CRN中,可以采用[7]中提出的近端语音检测器;但在本实验中,CRN模型之所以被使用,只是因为它在双通话期间的PESQ性能优于[7]中描述的带近端检测器的CRN。对于基于STFT域的模型,为了获得更好的性能,建议将堆叠DNN[3]的帧大小设置为320,CRN[7]的帧大小设置为640。对于时域模型(Wave-U-Net和建议的attention Wave-U-Net),帧大小设置为[9]中推荐的16384帧。所有模型均采用\(\beta_{1}=0.9\)和\(\beta_{1}=0.999\)的Adam优化器进行训练,但每种算法的学习率都经过调整。进行训练直到验证损失停止改善20个epoch。
在各种SER条件下的PESQ和ERLE性能在表2中列出了可见和不可见噪声条件。需要注意的是,表2中的每一幅图都是通过对各种信噪比条件(即{11,13,15}dB)的结果进行平均得到的。与基于STFT域的方法相比[3,7],基于时域的方法(即Wave-U-Net[9]和本文提出的方法)在ERLE和PSEQ方面都表现得更好。此外,从表2中我们可以看出,时域方法包括该方法取得了类似的看见和看不见的噪声条件下的性能,基于STFT域算法,特别是堆放款[3],经历了性能下降看不见的噪声条件,揭示了基于时域算法的鲁棒性与看不见的噪声条件。与原无注意机制的Wave-U-Net相比,该方法在单话音和双话音期间都取得了更好的性能。特别的是,该方法通过注意网络有效地去除混合信号中的回声,使单话音期间的性能增益比双话音期间的性能增益更高。图3描述了在-1.5dB SER、11dB SNR和babble噪声条件下,Wave-U-Net和本文方法混合、干净的近端语音和估计的近端语音的波形和谱图。图3也验证了注意机制的有效性,特别是在单通话期间(见图3 (e)和(f)中的红色矩形框)。
表2 可见噪声和不可见噪声的PESQ和ERLE性能。

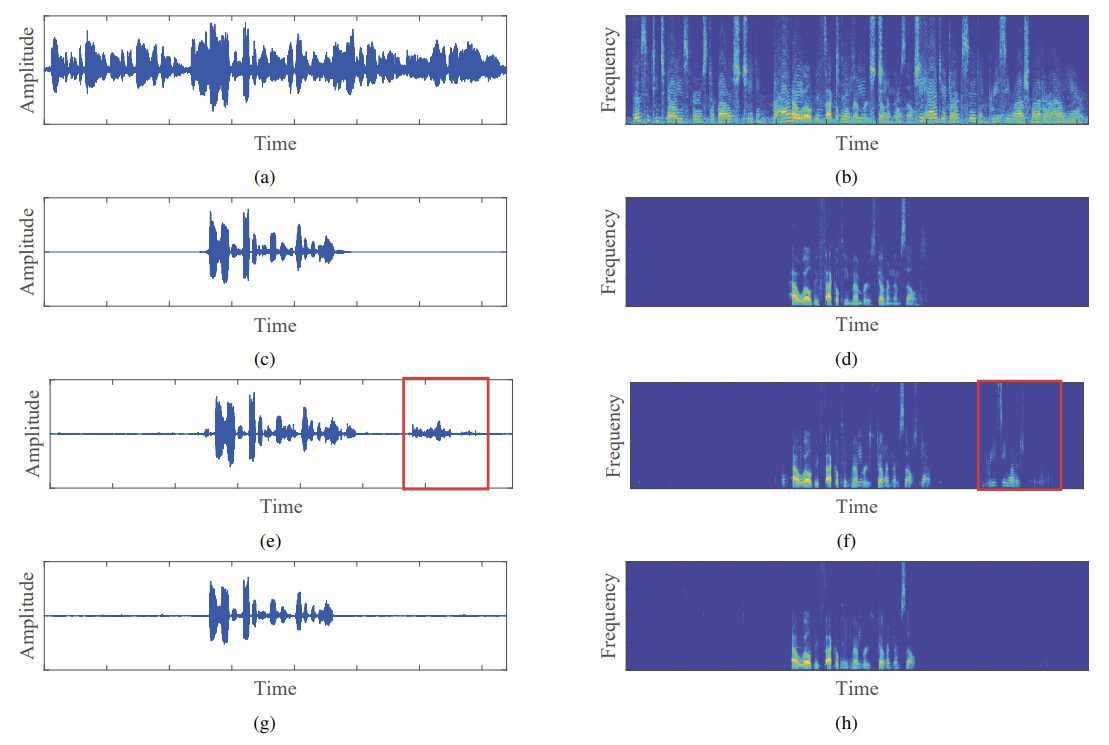
图3 在-1.5dB SER,11dB SNR和Babble噪声条件下的波形和频谱图
(a)混合语音(c)纯净近端语音(e)估计Wave-U-Net[9]的近端语音
(g)所提出方法估计的近端语音
(b)、(d)、(f)和(h)显示它们各自的谱图。
5 结论
本文提出了一种新型的注意力Wave-U-Net。该方法通过辅助编码器提取远端语音的相关特征,并利用注意机制将其传递到Wave-U-Net中,通过适当提取特征,Wave-U-Net可以有效抑制混合语音的回声。与现有的Wave-U-Net算法相比,所提出的注意Wave-U-Net在可见噪声和不可见噪声条件下的单话音和双话音周期都取得了优异的性能。
6 参考文献
[1] M. M. Halimeh, C. Huemmer, and W. Kellermann, “A neural network-based nonlinear acoustic echo canceller,” IEEE Signal Processing Letters, vol. 26, no. 12, pp. 1827–1831, 2019.
[2] J.-H. Kim, J. Kim, J. H. Jeon, and S. W. Nam, “Delayless individual-weighting-factors sign subband adaptive filter with band-dependent variable step-size,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 7, pp. 1526–1534, Jul. 2017.
[3] H. Seo, M. Lee, and J.-H. Chang, “Integrated acoustic echo and background noise suppression based on stacked deep neural networks,” Applied Acoustics, vol. 133, pp. 194–201, Apr. 2018.
[4] J. Park and J.-H. Chang, “Frequency-domain Volterra filter based on data-driven soft decision for nonlinear acoustic echo suppression,” IEEE Signal Processing Letters, vol. 21, no. 9, pp. 1088–1092, Sep. 2014.
[5] C. M. Lee, J. W. Shin, and N. S. Kim, “DNN-based residual echo suppression,” in Proc. INTERSPEECH, Sep. 2015, pp. 1775–1779.
[6] H. Zhang and D. L. Wang, “Deep learning for acoustic echo cancellation in noisy and double-talk scenarios,” in Proc. INTERSPEECH, Sep. 2018, pp. 3239–3243.
[7] H. Zhang, K. Tan, and D. L. Wang, “Deep learning for joint acoustic echo and noise cancellation with nonlinear distortions,” in Proc. INTERSPEECH, Sep. 2019, pp. 4255–4259.
[8] A. Fazel, M. El-Khamy, and J. Lee, “Deep multitask acoustic echo cancellation,” in Proc. INTERSPEECH, Sep. 2019, pp. 4250–4254.
[9] D. Stoller, S. Ewert, and S. Dixon, “Wave-U-Net: A multi-scale neural network for end-to-end audio source separation,” in Proc. International Society for Music Information Retrieval Conference (ISMIR), Sep. 2018, pp. 334–340.
[10] Y. Luo and N. Mesgarani, “Conv-TasNet: Surpassing ideal time-frequency magnitude masking for speech separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing,vol. 27, no. 8, pp. 1256–1266, Aug. 2019.
[11] X. Hao, X. Su, Z. Wang, H. Zhang, and Batushiren, “UNetGAN: A robust speech enhancement approach in time domain for extremely low signal-to-noise ratio condition,” in Proc. INTERSPEECH, Sep. 2019, pp. 1786–1790.
[12] T. Nakamura and H. Saruwatari, “Time-domain audio source separation based on wave-u-net combined with discrete wavelet transform,” in Proc. IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP), May 2020, pp. 386–390.
[13] R. Giri, U. Isik, and A. Krishnaswamy, “Attention Wave-U-Net for speech enhancement,” in Proc. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), Oct. 2019, pp. 249–253.
[14] J. B. Allen and D. A. Berkley, “Image method for efficiently simulating small-room acoustics,” Journal of the Acoustical Society of America, vol. 65, no. 4, pp. 943–950, Apr. 1979.
[15] ITU-T, “Test signals for use in telephonometry,” International Telecommunication Union, 2007.
[16] A. Varga and H. J. Steeneken, “Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems,”Speech Communication, vol. 12, no. 3, pp. 247–251, Jul. 1993.
最新文章
- 使用rdesktop连接Windows远程桌面
- Flash Builder如何自定义工作目录
- 2016.5.27 PHP连接数据库与查询
- ArcGIS API for Silverlight 调用WebService出现跨域访问报错的解决方法
- 上传图片到阿里云OSS和获取上传图片的外网url的步骤
- 019. Asp.net将SqlServer中的数据保存到xls/txt中
- python的whl文件安装
- Qt浅谈之三十九圆形进度条(已经有50篇了)
- Protostuff自定义序列化(Delegate)解析
- C++沉思录之一
- Hadoop--初识Hadoop
- 使用纯css3写出来的表情包 (^v^)
- python空字典列表两种生成方式对赋值带来的不同影响
- SpriteBuilder中音频文件格式的需要注意的地方
- PL/SQL中查询Oracle大数(17位以上)时显示科学计数法的解决方法
- saltstack系列~第二篇
- angular-translate
- windows编程之窗口抖动
- Ubuntu下配置PHP和CakePHP记录
- 多媒体文件格式之AVI
热门文章
- [转]sizeof计算空间大小的总结
- gen already exists but is not a source folder. Convert to a source folder or rename it 的解决办法
- Linux:awk与cut命令的区别
- java使用在线api实例
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
- [BUUCTF]PWN8——jarvisoj_level0
- 任务关联的类型(Project)
- java 8 启动脚本优化 2
- Java面向对象~类和对象&方法,类方法
- libevent源码学习(13):事件主循环event_base_loop