solr - 安装ik中文分词 和初始化富文本检索
1.下载安装包
https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler/7.4.0/solr-dataimporthandler-7.4.0.jar https://repo1.maven.org/maven2/org/apache/tika/tika-app/1.19.1/tika-app-1.19.1.jar https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler-extras/7.4.0/solr-dataimporthandler-extras-7.4.0.jar
ik分词器 ,我放在git 了
https://github.com/cen-xi/netty-tcp-spring-boot/tree/0458cb5626dcde976270b5351d67e96b162356d0/src/main/resources
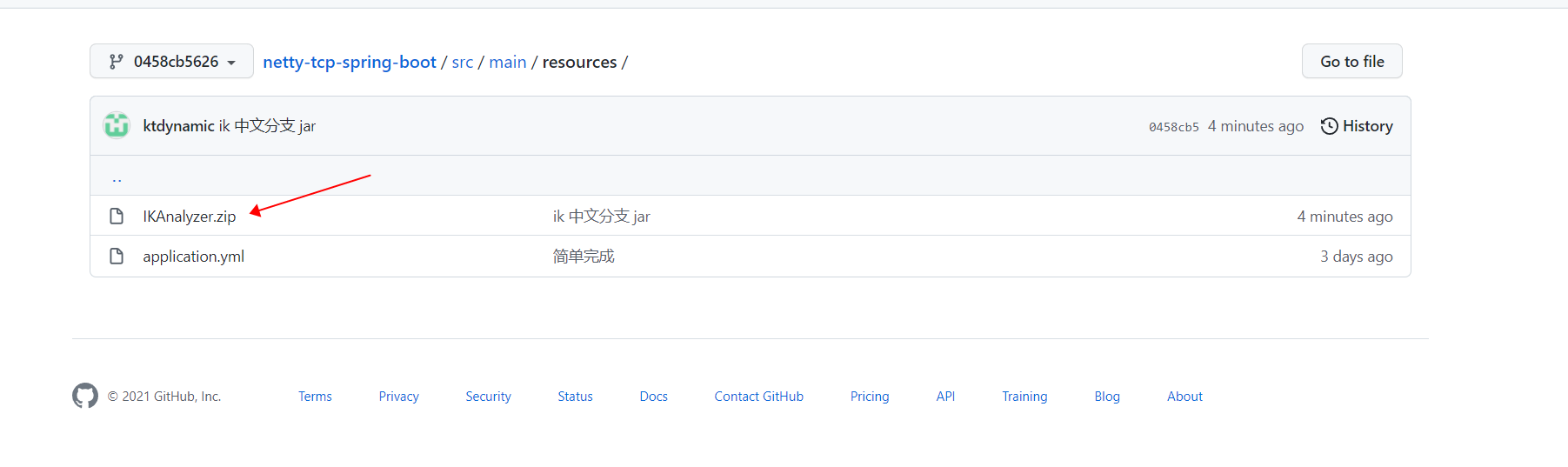
一共四个包,
把ik 的jar放到 E:\plug\solr\solr-7.7.3\server\solr-webapp\webapp\WEB-INF\lib 里面
其他的放到 E:\plug\solr\solr-7.7.3\contrib\extraction\lib
在 E:\plug\solr\solr-7.7.3\server\solr-webapp\webapp\WEB-INF 新建 classes 文件夹
然后在里面新建 IKAnalyzer.cfg.xml ,
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">hotword.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry> </properties>
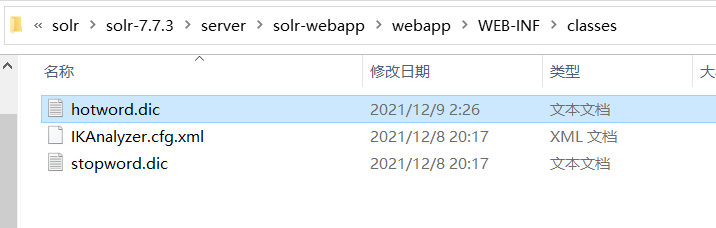
剩下的两个 hotword.dic 和 stopword.dic ,用sublime来创建 ,格式为 utf8且无bom的 ,否则不生效
更改hotword.dic 和 stopword.dic 后需要重启solr才生效
2.如果需要加载数据源 ,用在添加富文本检索数据 【代码里一般是在上传文件时就用tk来抽取检索内容然后存入solr的 ,这样用来初始化solr的检索文件的 ,比如数据丢失 ,一般将备份检索数据存在mysql里,启动时初始化检索数据】
需要在 进入创建的 core 里 ,E:\plug\solr\solr-7.7.3\server\solr\mycore1\conf 找到 solrconfig.xml
添加
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">tika-data-config.xml</str>
</lst>
</requestHandler>

在同级目录添加 tika-data-config.xml 文件
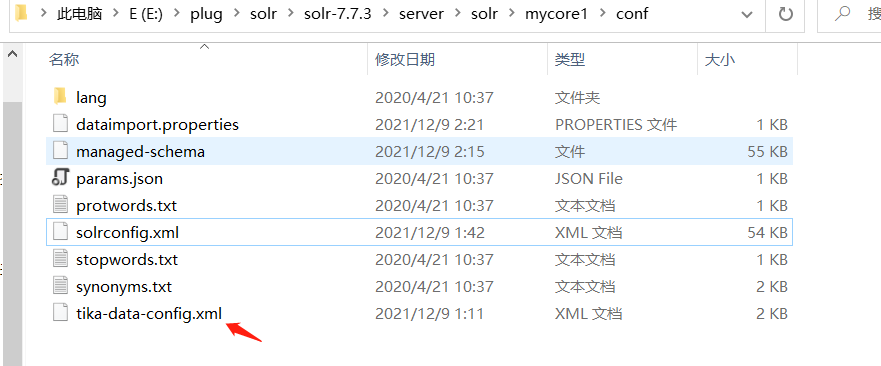
内容为
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="BinFileDataSource"/>
<document>
<entity name="file" processor="FileListEntityProcessor" dataSource="null"
baseDir="E:/plug/solr/testfile/" fileName=".(doc)|(pdf)|(docx)|(txt)|(csv)|(json)|(xml)|(pptx)|(pptx)|(ppt)|(xls)|(xlsx)"
rootEntity="false">
<field column="file" name="id"/>
<field column="fileSize" name="fileSize"/>
<field column="fileLastModified" name="fileLastModified"/>
<field column="fileAbsolutePath" name="fileAbsolutePath"/>
<entity name="pdf" processor="TikaEntityProcessor" url="${file.fileAbsolutePath}" format="text">
<field column="Author" name="author" meta="true"/>
<!-- in the original PDF, the Author meta-field name is upper-cased, but in Solr schema it is lower-cased -->
<field column="title" name="title" meta="true"/>
<field column="text" name="text"/>
</entity>
</entity>
</document>
</dataConfig>
E:/plug/solr/testfile/ 是存放文件的目录
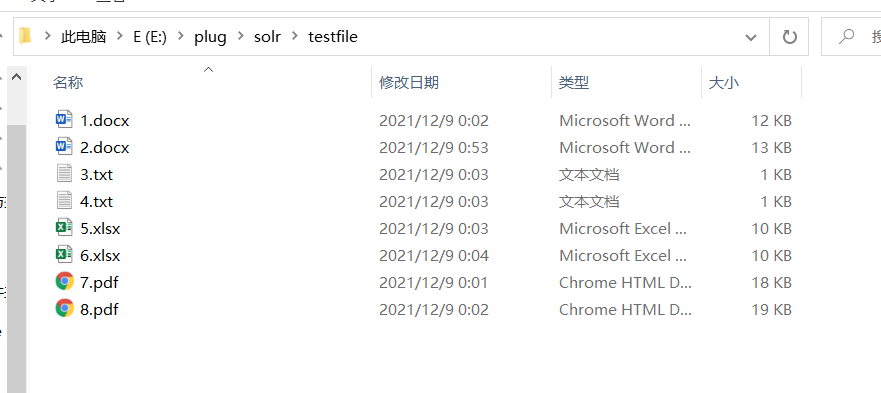
E:\plug\solr\solr-7.7.3\server\solr\mycore1\conf 找到 managed-schema
添加类型和字段 ,字段时根据需要来添加 ,但是 <fieldType name ="text_ik" class ="solr.TextField"> 则必须要有
<!-- ik-chinese-config , omitNorms ="true" , text_auto_phrase-->
<field name="title" type="text_ik" indexed="true" stored="true"/>
<field name="pdf" type="text_ik" indexed="true" stored="true"/>
<field name="mytab666" type="text_ik" indexed="true" stored="true"/>
<field name="text" type="text_ik" indexed="true" stored="true" />
<field name="author" type="text_ik" indexed="true" stored="true"/>
<field name="fileSize" type="plong" indexed="true" stored="true"/>
<field name="fileLastModified" type="pdate" indexed="true" stored="true"/>
<field name="fileAbsolutePath" type="string" indexed="true" stored="true"/>
<fieldType name ="text_ik" class ="solr.TextField">
<analyzer type ="index" isMaxWordLength ="false" class ="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type ="query" isMaxWordLength ="true" class ="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
保存后,在 http://localhost:8983/solr/ 控制面板 的 core admin找到 这个code 然后点击 reload , 否则不生效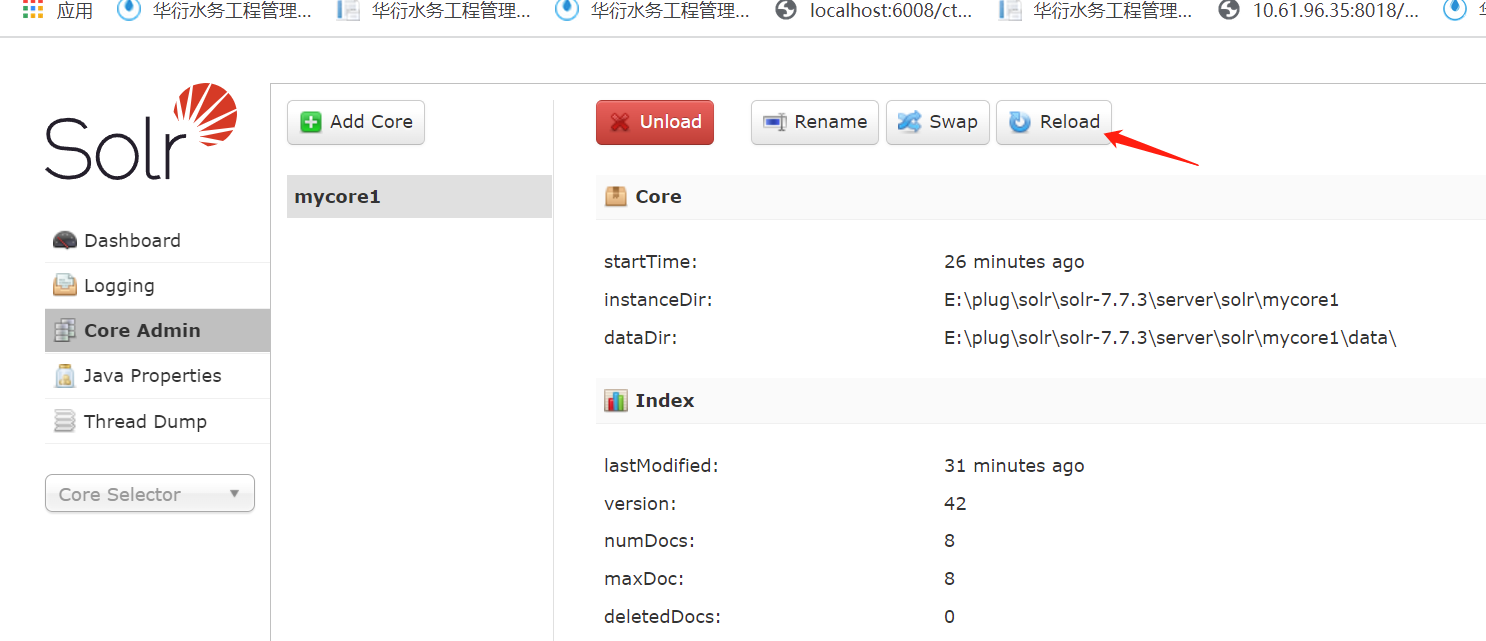
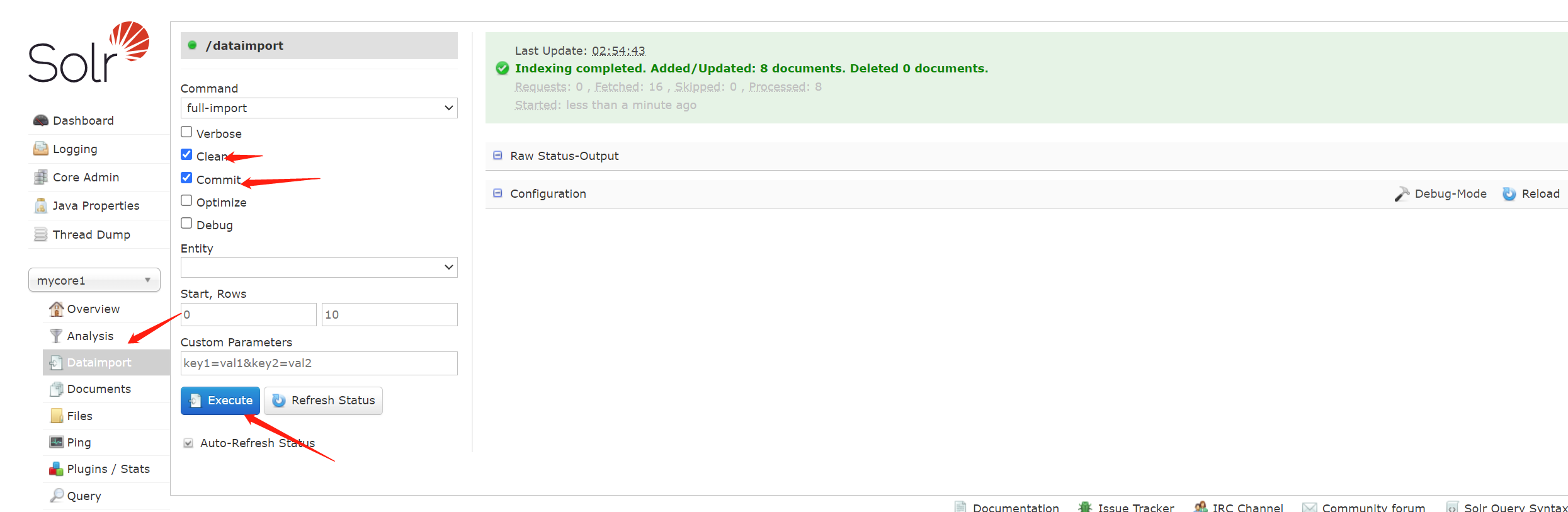
数据源配置完了,找到 Dataimport ,执行数据源的导入操作 ,否则不更新检索数据
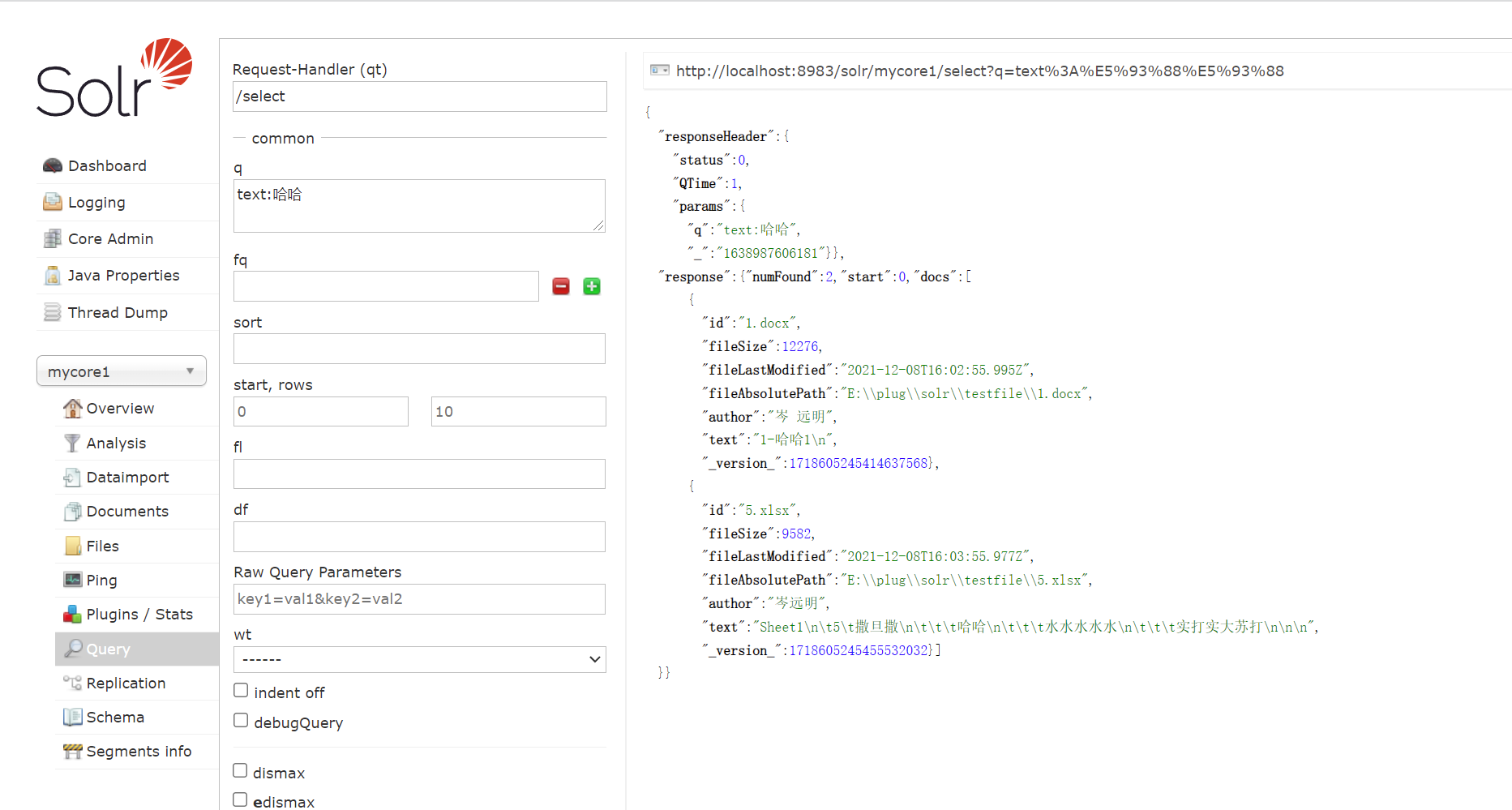
测试

最新文章
- Ubuntu彻底删除MySQL然后重装MySQL
- EDA系列学习
- jellyfish K-mer analysis and genome size estimate
- 虚拟化之vmware-vsphere (web) client
- SNM2无法编辑HostGroup项
- Qt使用默认浏览器打开网页
- 函数fil_extend_space_to_desired_size
- windows 下安装使用ipython
- [刷题]算法竞赛入门经典(第2版) 6-7/UVa804 - Petri Net Simulation
- JS和OC交互的简单应用
- 【转】搭建自己的 sentry 服务
- 为什么我离开Mac for Windows:苹果已经放弃了[译]
- Spring 1 控制反转、依赖注入
- HTTP Server to Client Communication
- 【BZOJ4031】小Z的房间
- ceph存储集群测试方案
- [Localization] YOLO: Real-Time Object Detection
- mysql杂谈
- rnn实现三位数加法的训练
- BOM 对象--location、navigator、screen、history
热门文章
- 【Java 基础】Java 根据Class获取对象实例
- Java中方法和类的深入分析
- 【web】BUUCTF-web刷题记录
- TMS570LS3137笔记-内部Flash FEE使用
- 祭出“成本”列(Project)
- Python变量的作用域在编译过程中确定
- uni-app + Cloudbase——uni-app 项目中如何使用腾讯云开发后端服务
- HTTPS 握手过程理解
- JAVA获取六位随机数
- SpringBoot整合Elasticsearch启动报错处理 nested exception is java.lang.IllegalStateException: availableProcessors is already set to [8], rejecting [8]