【Hadoop离线基础总结】数据仓库和hive的基本概念
数据仓库和Hive的基本概念
数据仓库
概述
数据仓库英文全称为 Data Warehouse,一般简称为DW。主要目的是构建面向分析的集成化数据环境,主要职责是对仓库中的数据进行分析,支持我们做决策。主要特征
面向主题(Subject-Oriented):数据分析有一定的范围,需要选取一定的主题进行分析。
集成性(Integrated):集成各个其他方面关联的数据,比如分析订单购买人的情况,就涉及到用户信息的数据。
非易失性(Non-Volatile):数据分析主要是分析过去已经发生的数据,都是既成的事实,不会再改变
时变性(Time-varient):随着时间的推移发展,数据的形态也在发生变化,数据分析的手段也要相应的改变数据仓库与数据库的区别

数据仓库分层架构
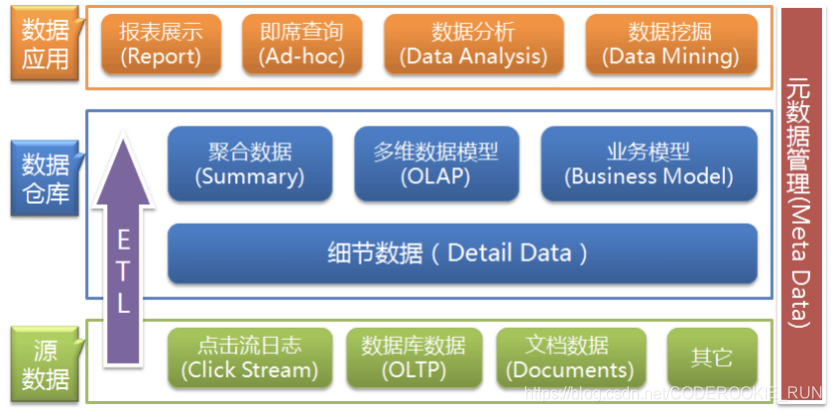
数据仓库架构可分为三层:源数据、数据仓库、数据应用
源数据层(ODS):是产生数据的地方。此层数据直接沿用外围系统数据结构和数据,不对外开放,为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。
数据仓库层(DW):也称为细节层,主要集中存储数据,面向主题进行分析。DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。
数据应用层(DA/APP):前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据,主要用于展示分析之后的数据结果。
ETL(抽取Extract, 转化Transfer, 装载Load):数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL的过程。ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持ETL的正常和稳定。
对数据仓库分层的原因:用空间换时间。通过数据分层管理可以简化数据清洗的过程,也就是把原来一步的工作分到了多个步骤去完成,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。数据仓库元数据管理
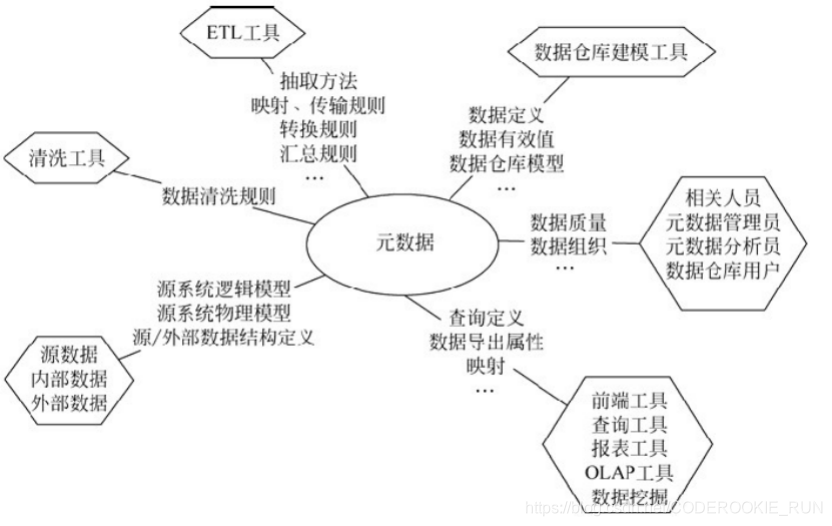
元数据(Meta Date):主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及ETL的任务运行状态。简单来讲,元数据记录了ETL一整套流程。如果要更为 详细地说,元数据定义了源数据系统到数据仓库的映射、数据转换的规则、数据仓库的逻辑结构、数据更新的规则、数据导入历史记录以及装载周期等相关内容。数据抽取和转换的专家以及数据仓库管理员正是通过元数据高效地构建数据仓库。
Hive的基本概念
概述
Hive是基于Hadoop的一个数据仓库处理工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。本质是将sql语句转换成MapReduce的任务进行执行,所以一定程度上可以说hive是MapReduce的一个客户端。结构化、半结构化、非结构化数据
结构化数据:体现为数据字段固定,数据类型固定(数据库的表就是一种最典型的结构化数据)
半结构化数据:XML,JSON,数据类型一定,但是数据的字段个数不定
非结构化数据:完全没有任何规律,字段类型不定、字段个数不定、数据类型不定,比如说音频、视频选择用Hive的原因
直接使用Hadoop的弊端:人员学习成本高、项目周期要求短、MapReduce实现复杂查询逻辑开发难度大
用Hive的好处:操作接口采用类sql语法,提供快速开发的能力。 避免了去写MapReduce,减少开发人员的学习成本。 功能扩展很方便Hive架构
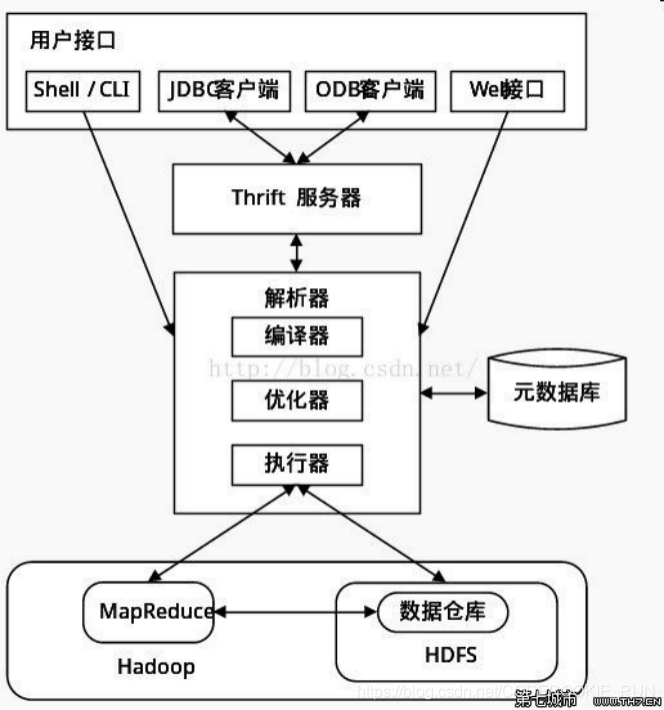
用户接口:就是提供写sql语句的地方。包括CLI、JDBC/ODBC、WebGUI。其中,CLI (command line interface) 为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
解析器:解析sql语句,转换成MepReduce的任务提交并准备执行,是重中之重。
元数据存储:通常是存储在关系数据库如mysql/derby中(Derby不好用,元数据一般都保存在mysql或者oracle中等)。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。Hive与Hadoop的关系

一句话来说明:Hive是MapReduce的一个客户端Hive和传统数据库的对比
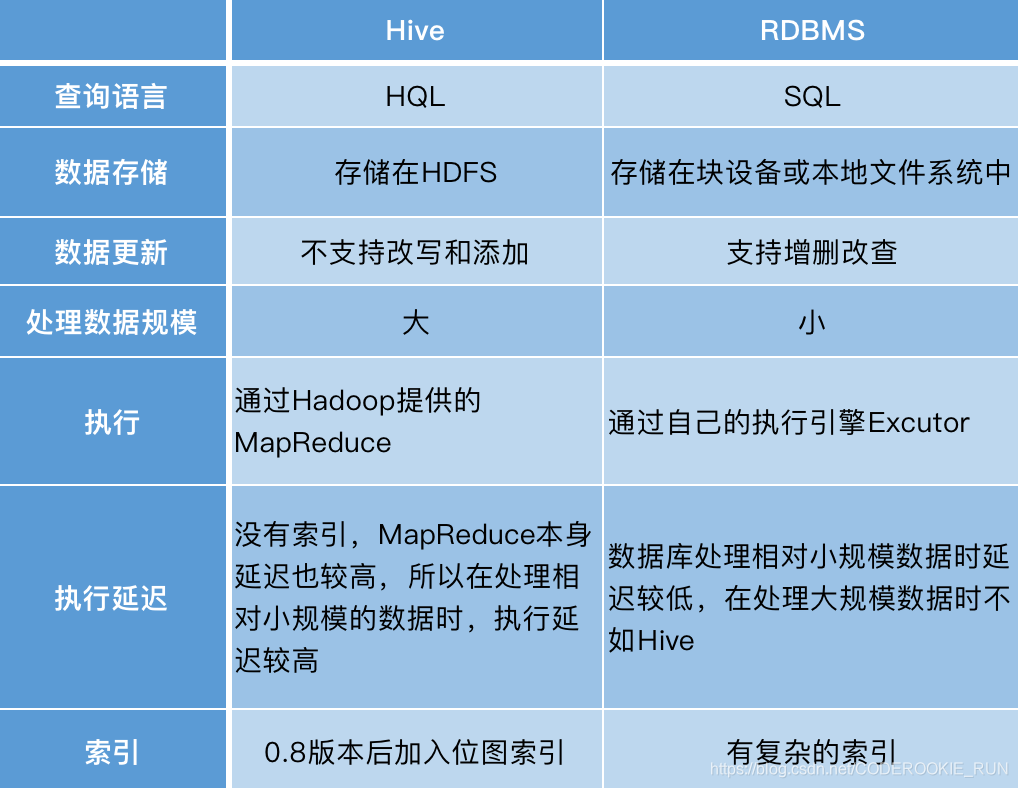
Hive的数据存储
Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,ORC,RCFILE等),只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
最新文章
- centos6 安装mysql报错Requires: libc.so.6(GLIBC_2.14)
- Model--汇总
- IIS 服务器下载apk文件报404错
- awstats 日志分析工具linux下的安装和使用
- NOJ 1072 The longest same color grid(尺取)
- Android编译系统详解(一)
- 文件和目录之link、unlink、remove和rename函数
- 网络流(最小费用最大流):POJ 2135 Farm Tour
- 转:VC中UpdateData()函数的使用
- PHP学习笔记三十五【Try】
- Java流
- Java项目转换成Web项目
- vue state
- Servlet JSP 二重修炼:Filter过滤器
- 前端使用node.js+express+mockjs+mysql实现简单服务端,2种方式模拟数据返回
- day29 网络编程
- sho
- 在GeoServer里设置图层的默认自定义样式,出现不显示预览图的情况(不起作用)
- vue.js相关UI组件收集
- python - argparse 模块学习