MPI聚合函数
2024-10-09 15:16:31
MPI聚合通信
- MPI_Barrier
int MPI_Barrier(
MPI_Comm comm
);
所有在该通道的函数都执行完后,才开始其他步骤。

0进程在状态T1调用MPI_Barrier函数,并在该位置挂起,等待其他进程到达。最后在T4状态同时进行。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nprocs;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Barrier(MPI_COMM_WORLD);
printf("Hello,world,I am %d of %d\n", rank, nprocs);
MPI_Finalize();
return 0;
}
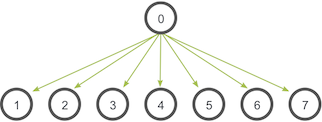
- MPI_Bcast
int MPI_Bcast(
void *buffer,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm comm
);
广播函数,root表示要广播的进程。发送和接收进程都需要写该函数。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank,nproc;
int ibuf;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) ibuf = 8888;
else ibuf = 0;
MPI_Bcast(&ibuf, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (rank != 0)
{
printf("rank = %d ibuf = %d\n", rank, ibuf);
}
MPI_Finalize();
return 0;
}
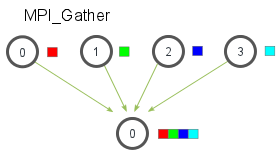
- MPI_Gather
int MPI_Gather(
void *sendbuf,
int sendcnt,
MPI_Datatype sendtype,
void *recvbuf,
int recvcnt,
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
每个进程(包括root进程)都要发送buffer给root进程,root进程接收到这些buffer并且按照顺序排好序。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
int isend, irecv[32];
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
isend = rank + 1;
MPI_Gather(&isend, 1, MPI_INT, irecv, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (rank == 0)
{
for (int i = 0; i < nproc; i++)
{
printf("%d \n", irecv[i]);
}
}
MPI_Finalize();
return 0;
}
- MPI_Gatherv
int MPI_Gatherv(
void *sendbuf,
int sendcnt,
MPI_Datatype sendtype,
void *recvbuf,
int *recvcnts,
int *displs,// 接收的数据放在说明位置,即位移。
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
是MPI_Gather函数的一个扩展,recvcnts是数组,允许每个进程的数量不同,而且每个进程的位置更灵活。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
//这里为了简单,假设有4个进程。
int send_buffer[6];
int recv_buffer[6];
int rank, nproc;
int receive_counts[4] = { 0,1,2,3 };
int receive_disp[4] = { 0,0,1,3 };//偏移数组
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
//初始化数据
for (int i = 0; i < rank; i++)
{
send_buffer[i] = rank;
recv_buffer[i] = rank+1;
}
MPI_Gatherv(send_buffer, rank, MPI_INT, recv_buffer, receive_counts, receive_disp, MPI_INT, 0, MPI_COMM_WORLD);
if (rank == 0)
{
for (int i = 0; i < 6; i++)
{
printf("[%d]", recv_buffer[i]);
}
}
MPI_Finalize();
return 0;
}
- MPI_Scatter
int MPI_Scatter(
void *sendbuf,
int sendcnt,
MPI_Datatype sendtype,
void *recvbuf,
int recvcnt,
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
MPI_Scatter与MPI_Bcast非常相似,都是一对多的通信方式,不同的是后者的0号进程将相同的信息发送给所有的进程,而前者则是将一段array 的不同部分发送给所有的进程。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
#define MAX_PRO 10//最大进程数
int main(int argc, char* argv[])
{
int rank, nproc;
int table[MAX_PRO][MAX_PRO];
int row[MAX_PRO];
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0)
{
for (int i = 0; i < nproc; i++)
{
for (int j = 0; j < MAX_PRO; j++)
{
table[i][j] = i + j;
}
}
}
MPI_Scatter(&table[0][0], MAX_PRO, MPI_INT, &row[0], MAX_PRO, MPI_INT, 0, MPI_COMM_WORLD);
if (rank != 0)
{
for (int i = 0; i < MAX_PRO; i++)
{
printf("%d ", row[i]);
}
printf("processs of %d\n",rank);
}
MPI_Finalize();
return 0;
}
- MPI_Alltoall
int MPI_Alltoall(
void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
MPI_Comm comm
);
当前进程向其他每个进程(包括自己)要发送数据,都是发送sendbuf中的数据。接收到不同进程的数据。

例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
int send[1];
int recv[10];
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
send[0] = rank*rank;
for (int i = 0; i < 10; i++)
{
recv[i] = 0;
}
MPI_Alltoall(&send, 1, MPI_INT, recv, 1, MPI_INT, MPI_COMM_WORLD);
if (rank == 0)
{
for (int i = 0; i < 10; i++)
{
printf("%d ", recv[i]);
}
}
MPI_Finalize();
return 0;
}
MPI归约操作
- MPI_Reduce
int MPI_Reduce(
void *sendbuf,
void *recvbuf,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm comm
);
MPI_Op有如下类型:
| 运算操作符 | 描述 | 运算操作符 | 描述 |
|---|---|---|---|
| MPI_MAX | 最大值 | MPI_LOR | 逻辑或 |
| MPI_MIN | 最小值 | MPI_BOR | 位与 |
| MPI_SUM | 求和 | MPI_LXOR | 逻辑异或 |
| MPI_PROD | 求积 | MPI_BXOP | 位异或 |
| MPI_LAND | 逻辑与 | MPI_MINLOC | 计算一个全局最小值 |
| MPI_BAND | 位与 | MPI_MAXLOC | 计算一个全局最大值 |
将通信子内各进程的同一个变量参与规约计算,并向指定的进程输出计算结果。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int send = rank;
int recv;
MPI_Reduce(&send, &recv, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0)
{
printf("%d", recv);
}
MPI_Finalize();
return 0;
}
- MPI_Scan
int MPI_Scan(
void *sendbuf,
void *recvbuf,
int count,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm comm
);
前缀和函数 MPI_Scan(),将通信子内各进程的同一个变量参与前缀规约计算,并将得到的结果发送回每个进程,使用与函数 MPI_Reduce() 相同的操作类型。

例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int send = rank;
int recv;
MPI_Scan(&send, &recv, 1, MPI_INT, MPI_SUM, MPI_COMM_WORLD);
printf("the %d process is %d", rank, recv);
MPI_Finalize();
return 0;
}
- MPI_Reduce_scatter
int MPI_Reduce_scatter(
void *sendbuf,
void *recvbuf,
int *recvcnts,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm comm
);
将规约结果分片发送到各进程.
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char** argv)
{
int* sendbuf, recvbuf, * recvcounts;
int size, rank;
MPI_Comm comm;
MPI_Init(&argc, &argv);
comm = MPI_COMM_WORLD;
MPI_Comm_size(comm, &size);
MPI_Comm_rank(comm, &rank);
sendbuf = (int*)malloc(size * sizeof(int));
for (int i = 0; i < size; i++)
sendbuf[i] = i;
recvcounts = (int*)malloc(size * sizeof(int));
for (int i = 0; i < size; i++)
recvcounts[i] = 1;
MPI_Reduce_scatter(sendbuf, &recvbuf, recvcounts, MPI_INT, MPI_SUM, comm);
printf("the %d process is %d", rank, recvbuf);
MPI_Finalize();
return 0;
}
最新文章
- LINQ to SQL Select查询
- eclipse中去除build时总是js错误的问题
- win8 系统无法正常安装.net framework 2.0和3.0框架如何解决
- POJ 3464 ACM Computer Factory
- java面向对象编程——第二章 java基础语法
- 【DP】BZOJ 1260: [CQOI2007]涂色paint
- building Utils {{ant+ivy}、{maven}}怎么样手动将下载下来的 JAR 包添加到 Maven、ivy 的本地仓库
- [Locked] Paint Fence
- linux常用命令汇总(更新中...)
- 关于asp.net中链接数据库的问题
- Codeforces Round #129 (Div. 1)E. Little Elephant and Strings
- 第六次作业———numpy数据集练习
- ASP.NET MVC - XML节点查找
- BZOJ3560 DZY Loves Math V 数论 快速幂
- Linux常用命令1-50(持续更新中)
- jQuery插件初级练习4答案
- nor flash 和 nand flash
- svn简单记录
- 收集一些常用Javascripot
- bzoj千题计划162:bzoj2006: [NOI2010]超级钢琴