sklearn KMeans聚类算法(总结)
2024-08-29 07:29:25
基本原理
Kmeans是无监督学习的代表,没有所谓的Y。主要目的是分类,分类的依据就是样本之间的距离。比如要分为K类。步骤是:
- 随机选取K个点。
- 计算每个点到K个质心的距离,分成K个簇。
- 计算K个簇样本的平均值作新的质心
- 循环2、3
- 位置不变,距离完成
距离
Kmeans的基本原理是计算距离。一般有三种距离可选:
- 欧氏距离
\[d(x,u)=\sqrt{\sum_{i=1}^n(x_i-\mu_i)^2}
\] - 曼哈顿距离
\[d(x,u)=\sum_{i=1}^n(|x_i-\mu|)
\] - 余弦距离
\[cos\theta=\frac{\sum_{i=1}^n(x_i*\mu)}{\sqrt{\sum_i^n(x_i)^2}*\sqrt{\sum_1^n(\mu)^2}}
\]
inertia
每个簇内到其质心的距离相加,叫inertia。各个簇的inertia相加的和越小,即簇内越相似。(但是k越大inertia越小,追求k越大对应用无益处)
代码
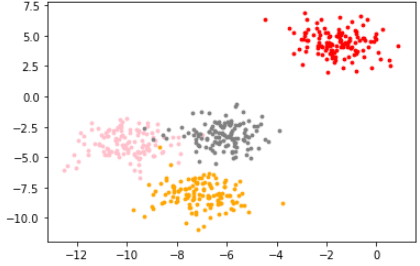
模拟数据:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=500, # 500个样本
n_features=2, # 每个样本2个特征
centers=4, # 4个中心
random_state=1 #控制随机性
)
画出图像:
color = ['red', 'pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(4):
axi1.scatter(X[y==i, 0], X[y==i,1],
marker='o',
s=8,
c=color[i]
)
plt.show()
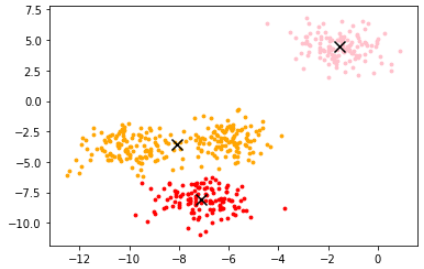
使用KMeans类建模:
from sklearn.cluster import KMeans
n_clusters=3
cluster = KMeans(n_clusters=n_clusters,random_state=0).fit(X)
也可先用fit, 再用predict,但是可能数据不准确。用于数据量较大时。
此时就可以查看其属性了:质心、inertia.
centroid=cluster.cluster_centers_
centroid # 查看质心
查看inertia:
inertia=cluster.inertia_
inertia
画出所在位置。
color=['red','pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(n_clusters):
axi1.scatter(X[y_pred==i, 0], X[y_pred==i, 1],
marker='o',
s=8,
c=color[i])
axi1.scatter(centroid[:,0],centroid[:,1],marker='x',s=100,c='black')
最新文章
- ssh 与 irc
- spring 注入静态变量
- [Tex学习笔记]写文章需要规范、需要引用到位. [LaTeX代码]
- easyui中tree使用simpleData的形式加载数据
- [Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒
- thread_fork/join并发框架1
- C# 之屏幕找图
- Android系列之Fragment(二)----Fragment的生命周期和返回栈
- jQuery使用ajax跨域获取数据
- Java1.8.0_05 环境配置
- Android的事件处理机制详解(二)-----基于监听的事件处理机制
- js控制不同的时间段显示不同的css样式
- ora 32021 设置参数时参数值长度超过255处理办法
- Web前端常见问题处理
- [原创]python MySQLdb在windows环境下的安装、出错问题以及解决办法
- 编译lua5.3.2报错提示libreadline.so存在未定义的引用解决方法
- EF数据存贮问题二之“无法定义这两个对象之间的关系,因为它们附加到不同的 ObjectContext 对象”
- vue数组语法兼容问题
- nginx反向代理node.js获取客户端IP
- Android:更好的自定义字体方案