python-网络安全编程第十天(web目录扫描&&fake_useragent模块&&optionParser模块)
2024-08-28 06:06:11
前言


昨天的内容没有完成今天花了点时间继续完成了 感觉自己的学习效率太低了!想办法提高学习效率吧 嗯 ,再制定下今天的目标 开始健身。
python fake_useragent模块
1.UserAgent
userAgent 属性是一个只读的字符串,声明了浏览器用于 HTTP 请求的用户代理头的值。
2. fake_useragent
fake_useragent是一个集成了市面上大部分的user-agent,可以指定浏览器,也可随机生成任意一个
在工作中进行爬虫时,经常会需要提供User-Agent,如果不提供User-Agent,会导致爬虫在请求网页时,请求失败,所以需要大量User-Agent。如何生成合法的User-Agent?
使用fake-useragent库就可以解决该问题。
3.fake_useragent简单使用
示例代码1:
简单打印出几个user-agent
from fake_useragent import UserAgent
ua=UserAgent() #实例化 print(ua.ie) #随机打印一个ie浏览器的User-Agent
print(ua.random)#随机打印一个User-Agent
输出结果:

示例代码2:
将useragent带入到header请求头里面进行http请求
from fake_useragent import UserAgent
import requests
ua=UserAgent() #实例化 url="http://baidu.com"
ua=str(ua.random)
headers={'User-Agent':ua} r=requests.get(url=url,headers=headers)
print(r.url)
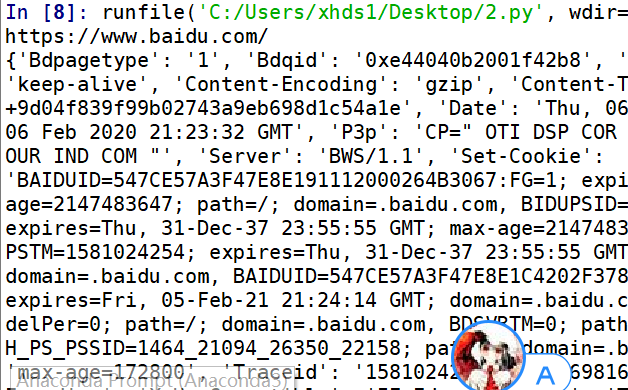
print(r.headers)
请求结果:
Python-optionParser模块
代码:
from optparse import OptionParser
parser=OptionParser() #dest是存储变量的 default是缺省值 help是帮助提示
#使用add_option()加入选项
parser.add_option("-u","--url",dest="url",help='target url for scan')
parser.add_option("-f","--file",dest="ext",help="target url ext")
parser.add_option("-t","--thread",dest="count",default=10,help="scan thread_count")
#最后通过parse_args()函数的解析
(options,args)=parser.parse_args() #当option.url 和option.ext里面的值都为真是则继续执行里面的函数
if options.url and options.ext:
print(options.url)
print(options.ext)
print(options.count)
else:
parser.print_help()
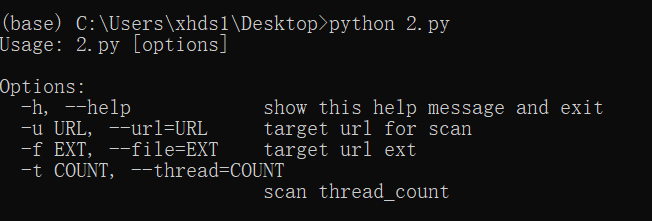
正常使用我们在cmd命令界面调用一一输入我们的值即可正常运行

如果没有输入值则会打印出我们定义的help里面的信息
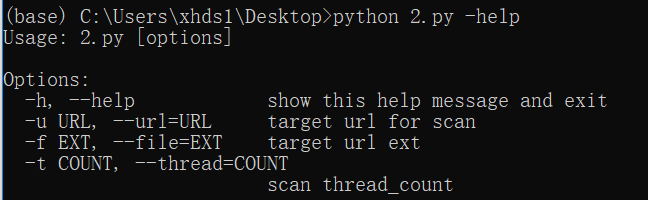
输入-help参数也会打印help信息
参考学习:https://blog.csdn.net/lwnylslwnyls/article/details/8199454
web目录扫描器
代码:
import requests
import queue
import sys
import threading
#from agent_proxy import USER_AGENT_LIST
from fake_useragent import UserAgent
queue=queue.Queue()
from optparse import OptionParser
import sys class DirScan(threading.Thread):
def __init__(self,queue):
threading.Thread.__init__(self)
self._queue=queue def run(self):
while not self._queue.empty():
url=self._queue.get() try: ua=UserAgent()
ua1=str(ua.random) headers={'User-Agent':ua1}
r=requests.get(url=url,headers=headers,timeout=8) if r.status_code==200:
print(r.url)
#sys.stdout.write('\r'+'[*]%s\t\t'%(url))
f=open('result.html','a+')
f.write('<a href="'+url+'" target="_blank">'+url+'</a>')
f.write('\r\n<br>')
f.close except Exception as e:
pass def start(url,ext,count): f=open('result.html','w')
f.close() f=open('./dics/%s.txt'%ext,'r') for i in f:
queue.put(url+i.rstrip('\n')) #
threads=[]
thread_count=int(count)
#
for i in range(thread_count):
threads.append(DirScan(queue))
for t in threads:
t.start()
for t in threads:
t.join()
##
#
#start("http://www.dokocom.com",'asp','10'); if __name__=='__main__':
print("=====================================\n榆林学院信息安全协会开发V1.0\n超级高速web目录敏感扫描器\n=====================================\n") parser=OptionParser()
# parser=OptionParser()
parser.add_option("-u","--url",dest="url",help='target url for scan')
parser.add_option("-f","--file",dest="ext",help="target url ext")
parser.add_option("-t","--thread",dest="count",default=10,help="scan thread_count")
(options,args)=parser.parse_args() if options.url and options.ext:
start(options.url,options.ext,options.count);
sys.exit(1)
else:
parser.print_help()
sys.exit(1)
#
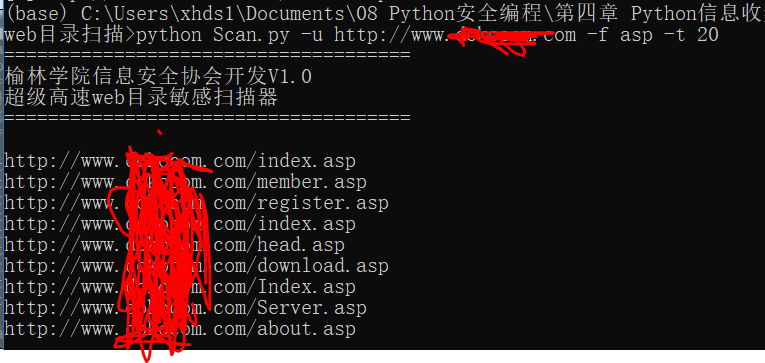
使用方法:
使用方法:python Scan.py http:xxx.com -f asp -t 20
-f: 脚本类型
-t :线程数
如果输入有误提示使用方式:

会在程序当前目录下生成result.html文件 打开就是扫描的结果
最新文章
- 分享一个递归无限级拼接Json的方法---ExtJs的TreePanel和TreeGrid均适用(Ef,Lambda,Linq,IQueryable,List)
- 数据字典生成工具之旅(4):NPOI操作EXECL
- [ACM_图论] Fire Net (ZOJ 1002 带障碍棋盘布炮,互不攻击最大数量)
- Unity3D 新人学习的一点感想
- js的基本概念详解
- dictionary ----- python
- 一张图讲解为什么需要自己搭建自己的git服务以及搭建的途径
- HDU 1532 Drainage Ditches
- java基础:简单实现线程池
- 201521123018 《Java程序设计》第12周学习总结
- 4种常用扒站工具(webzip、ha_TeleportPro、Offline Explorer、wget)
- selenium数据驱动模式实现163邮箱的登录及添加联系人自动化操作
- JS文件写法操作,DOM基本操作
- 21天打造分布式爬虫-Selenium爬取拉钩职位信息(六)
- 【Beta Scrum】冲刺!5/5
- How can R and Hadoop be used together?
- p1654 OSU!
- [CodeForces - 197F] F - Opening Portals
- spring+springMVC+mybatis+maven+mysql环境搭建(一)
- MySQL 第四篇:数据操作