Hadoop 安装及目录结构
一、准备工作
【1】创建用户:useradd 用户名
【2】配置创建的用户具有 root权限,修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示:(注意:需要先给sudoer 文件赋权限,修改完会后,将权限修改回来)修改完毕,现在可以用创建的帐号登录,然后用命令 su - ,即可获得 root权限进行操作。
1 ## Allow root to run any commands anywhere
2 root ALL=(ALL) ALL
3 创建的用户 ALL=(ALL) ALL
【3】在/opt目录下创建module、software文件夹,同时修改文件的所有者 sudo chmod 777 文件地址。
1 sudo mkdir module
2 sudo mkdir software
二、下载地址
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
解压:tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
三、配置环境变量
【1】查看 Hadoop解压目录
1 [zzx@localhost hadoop-2.7.2-src]$ pwd
2 /opt/module/hadoop-2.7.2-src
【2】打开 /etc/profile
[zzx@localhost etc]$ sudo vi profile
【3】在文件中添加 Hadoop的环境变量
1 ##HADOOP_HOME
2 export HADOOP_HOME=/opt/module/hadoop-2.7.2
3 export PATH=$PATH:$HADOOP_HOME/bin
4 export PATH=$PATH:$HADOOP_HOME/sbin
【4】重启配置文件,让修改的配置文件生效
[root@localhost etc]# source /etc/profile
【5】测试是否安装成功(如果Hadoop命令不生效就重启试试 reboot)
1 [root@localhost soft]# hadoop version
2 Hadoop 2.7.2
3 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r b165c4fe8a74265c792ce23f546c64604acf0e41
4 Compiled by jenkins on 2016-01-26T00:08Z
5 Compiled with protoc 2.5.0
6 From source with checksum d0fda26633fa762bff87ec759ebe689c
7 This command was run using /opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar
四、可能会遇见的问题
【问题描述】Error: JAVA_HOME is not set and could not be found.
【解决办法】在安装目录下/etc/hadoop/ 下,找到 hadoop-env.sh
1 #将下面的 $JAVA_HOME 修改为绝对路径,下面一行为默认的,错误展示
2 export JAVA_HOME=$JAVA_HOME
3
4 #修改后的正确展示
5 export JAVA_HOME=/usr/local/soft/jdk8
五、Hadoop目录结构
【1】查看Hadoop目录结构
1 [root@localhost hadoop-2.7.2]# ll
2 总用量 28
3 drwxr-xr-x. 2 10011 10011 194 1月 26 2016 bin
4 drwxr-xr-x. 3 10011 10011 20 1月 26 2016 etc
5 drwxr-xr-x. 2 10011 10011 106 1月 26 2016 include
6 drwxr-xr-x. 3 10011 10011 20 1月 26 2016 lib
7 drwxr-xr-x. 2 10011 10011 239 1月 26 2016 libexec
8 -rw-r--r--. 1 10011 10011 15429 1月 26 2016 LICENSE.txt
9 -rw-r--r--. 1 10011 10011 101 1月 26 2016 NOTICE.txt
10 -rw-r--r--. 1 10011 10011 1366 1月 26 2016 README.txt
11 drwxr-xr-x. 2 10011 10011 4096 1月 26 2016 sbin
12 drwxr-xr-x. 4 10011 10011 31 1月 26 2016 share
【2】重要目录:
◕‿-。 bin目录:存放对 Hadoop相关服务(HDFS,YARN)进行操作的脚本,里面常用的就是hadoop这个配置;
。◕‿◕。 etc目录:Hadoop的配置文件目录,存放 Hadoop的配置文件。后期会修改大量配置文件;
◕‿-。 lib目录:存放 Hadoop的本地库(对数据进行压缩解压缩功能);
。◕‿◕。 sbin目录:存放启动或停止Hadoop相关服务的脚本,很重要;
◕‿-。 share目录:存放Hadoop的依赖jar包、文档、和官方案例;
六、启动 HDFS并运行 MapReduce程序
【1】配置:hadoop-env.sh:在 etc/hadoop/hadoop-en.sh 修改JAVA_HOME 路径为 JDK的绝对路径。
export JAVA_HOME=/usr/local/soft/jdk8

![]()
【2】配置:core-site.xml:hadoop01 需要配置hosts映射,存储系统会自动创建
1 <!-- 指定HDFS中NameNode的地址 -->
2 <property>
3 <name>fs.defaultFS</name>
4 <value>hdfs://hadoop1:9000</value>
5 </property>
6
7 <!-- 指定Hadoop运行时产生文件的存储目录 -->
8 <property>
9 <name>hadoop.tmp.dir</name>
10 <value>/opt/module/hadoop-2.7.2/data/tmp</value>
11 </property>

![]()
【3】配置:hdfs-site.xml:默认副本数是3个
1 <!-- 指定HDFS副本的数量 -->
2 <property>
3 <name>dfs.replication</name>
4 <value>1</value>
5 </property>
【4】格式化NameNode(第一次启动时格式化,以后就不要总格式化)
[root@localhost hadoop-2.7.2]# bin/hdfs namenode -format
【5】启动 NameNode
[root@localhost hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode
【问题描述】 可能会出现:Error: Cannot find configuration directory: /etc/hadoop
【问题解决】 在hadoop-env.sh 修改 hadoop配置文件所在目录,并进行重启 source xx。同时,需要删除 namenode 的data中的数据和 logs中的namenode 和 namedate 所有文件。
export HADOOP_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop/
【6】启动 DataNode
[root@localhost hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
【7】 使用JPS命令查看是否启动成功,JPS 是JDK中的命令,不是Linux命令。不安装JDK不能使用 JPS
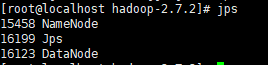
![]() 【8】web端查看 HDFS文件系统(注意需要配置hosts):http://hadoop1:50070/dfshealth.html#tab-overview
【8】web端查看 HDFS文件系统(注意需要配置hosts):http://hadoop1:50070/dfshealth.html#tab-overview
![]() 【9】查看产生的 Log日志,在企业中遇到Bug时,经常根据日志提示信息去分析问题、解决Bug。当前目录:/opt/module/hadoop-2.7.2/logs
【9】查看产生的 Log日志,在企业中遇到Bug时,经常根据日志提示信息去分析问题、解决Bug。当前目录:/opt/module/hadoop-2.7.2/logs

![]()
【10】操作集群:在 HDFS文件系统上创建一个 input文件夹,-P创建多级目录
[root@localhost hadoop-2.7.2]# bin/hdfs dfs -mkdir -p /user/zzx/input
【11】 将测试文件内容上传到文件系统上:
[root@localhost hadoop-2.7.2]# bin/hdfs dfs -put input/zzx /user/zzx/input/
【12】 查看上传的文件是否正确
1 [root@localhost hadoop-2.7.2]# bin/hdfs dfs -ls /user/zzx/input/
2 Found 1 items
3 -rw-r--r-- 1 root supergroup 74 2020-06-20 16:44 /user/zzx/input/zzx
【13】查看上传的文件是否正确
1 [root@localhost hadoop-2.7.2]# bin/hdfs dfs -cat /user/zzx/input/zzx
2 zzx
3 jinlong
4 tangjin
5 zzx
6 zzx
7 jinlong
8 jian
9 fanjing
10 fanjing
11 fanjing
12 fanjing
【14】 运行 MapReduce程序,与开始时执行的本地是一致的。
[root@localhost hadoop-2.7.2]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/zzx/input/ /user/zzx/output/
【15】查看输出结果,命令行查看
1 [root@localhost hadoop-2.7.2]# bin/hdfs dfs -cat /user/zzx/output/*
2 fanjing 4
3 jian 1
4 jinlong 2
5 tangjin 1
6 zzx 3
【16】查看输出结果,浏览器查看:Utilities-Brower...-user-zzx-output

![]()
七、启动 YARN并运行 MapReduce程序
【1】配置 yarn-env.sh,配置一下JAVA_HOME
export JAVA_HOME=/usr/local/soft/jdk8
【2】配置yarn-site.xml
1 <!-- Reducer获取数据的方式 -->
2 <property>
3 <name>yarn.nodemanager.aux-services</name>
4 <value>mapreduce_shuffle</value>
5 </property>
6
7 <!-- 指定YARN的ResourceManager的地址 -->
8 <property>
9 <name>yarn.resourcemanager.hostname</name>
10 <value>hadoop1</value>
11 </property>

![]()
【3】配置:mapred-env.sh,配置一下JAVA_HOME
export export JAVA_HOME=/usr/local/soft/jdk8
【4】 配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
【5】配置:mapred-site.xml
1 <!-- 指定MR运行在YARN上 -->
2 <property>
3 <name>mapreduce.framework.name</name>
4 <value>yarn</value>
5 </property>

![]()
八、启动集群
【1】启动前必须保证 NameNode和 DataNode已经启动;
【2】启动 ResourceManager
[root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager
【3】 启动NodeManager
[root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager
【4】YARN的浏览器页面查看:http://hadoop1:8088/cluster
![]()
【5】 删除文件系统上的 output文件
1 [root@localhost hadoop-2.7.2]# bin/hdfs dfs -rm -R /user/zzx/output
2 20/06/20 17:20:20 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
3 Deleted /user/zzx/output
【6】执行MapReduce程序
[root@localhost hadoop-2.7.2]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/zzx/input /user/zzx/output
【7】查看运行结果,刷新页面即可

![]()
九、配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
【1】配置mapred-site.xml,在该文件里面增加如下配置。
1 <!-- 历史服务器端地址 -->
2 <property>
3 <name>mapreduce.jobhistory.address</name>
4 <value>hadoop1:10020</value>
5 </property>
6 <!-- 历史服务器web端地址 -->
7 <property>
8 <name>mapreduce.jobhistory.webapp.address</name>
9 <value>hadoop1:19888</value>
10 </property>
【2】启动历史服务器
[root@localhost hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh start historyserver
【3】查看历史服务器是否启动 JPS
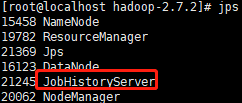
![]()
【4】查看JobHistory:http://hadoop1:19888/jobhistory
十、配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动 NodeManager 、ResourceManager和 HistoryManager。
开启日志聚集功能具体步骤如下:
【1】配置yarn-site.xml,在该文件里面增加如下配置
1 <!-- 日志聚集功能使能 -->
2 <property>
3 <name>yarn.log-aggregation-enable</name>
4 <value>true</value>
5 </property>
6
7 <!-- 日志保留时间设置7天 -->
8 <property>
9 <name>yarn.log-aggregation.retain-seconds</name>
10 <value>604800</value>
11 </property>
【2】关闭NodeManager 、ResourceManager和 HistoryManager
1 [root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh stop resourcemanager
2 stopping resourcemanager
3 [root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh stop nodemanager
4 stopping nodemanager
5 nodemanager did not stop gracefully after 5 seconds: killing with kill -9
6 [root@localhost hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh stop historyserver
7 stopping historyserver
【3】 启动NodeManager 、ResourceManager和 HistoryManager
1 [root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager
2 starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-resourcemanager-localhost.localdomain.out
3 [root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager
4 starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-localhost.localdomain.out
5 [root@localhost hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh start historyserver
6 starting historyserver, logging to /opt/module/hadoop-2.7.2/logs/mapred-root-historyserver-localhost.localdomain.out
7 [root@localhost hadoop-2.7.2]# jps
8 21937 ResourceManager
9 15458 NameNode
10 22197 NodeManager
11 22374 JobHistoryServer
12 16123 DataNode
13 22415 Jps
【4】删除 HDFS上已经存在的输出文件
[root@localhost hadoop-2.7.2]# bin/hdfs dfs -rm -R /user/zzx/output
【5】执行 WordCount程序
[root@localhost hadoop-2.7.2]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/zzx/input /user/zzx/output
【6】 查看日志,进入JobHistory 点击 JobID
![]() 【7】点击 logs
【7】点击 logs 
![]() 【8】日志的具体信息
【8】日志的具体信息
![]()
十一、配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
【1】默认配置文件:
|
要获取的默认文件 |
文件存放在Hadoop的jar包中的位置 |
|
[core-default.xml] |
hadoop-common-2.7.2.jar/ core-default.xml |
|
[hdfs-default.xml] |
hadoop-hdfs-2.7.2.jar/ hdfs-default.xml |
|
[yarn-default.xml] |
hadoop-yarn-common-2.7.2.jar/ yarn-default.xml |
|
[mapred-default.xml] |
hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml |
【2】 自定义配置文件:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在 $HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
十二、完全分布式运行模式
【1】将 /etc/profile 和 /opt/module 下的文件拷贝到其它两台服务器上,并进行 source xxx。可以自己去拉hadoop1,hadoop1也可自行给你推,hadoop1 也可以将hadoop2 中的文件推给 hadoop3,当传文件夹的时记得加 -r 递归复制。
1 [root@localhost ~]# scp root@192.168.52.131:/etc/bash.bashrc /etc/bash.bashrc
2 [root@localhost opt]# scp -r root@hadoop1:/opt /opt
【2】集群部署规划:根据这个配置修改上面的伪分布式就可以了
|
hadoop1 |
hadoop2 |
hadoop3 |
|
|
HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
【3】hadoop1配置 hdfs-site.xml
1 <!-- 指定HDFS副本的数量 -->
2 <property>
3 <name>dfs.replication</name>
4 <value>3</value>
5 </property>
6 <!-- 指定Hadoop辅助名称节点主机配置 -->
7 <property>
8 <name>dfs.namenode.secondary.http-address</name>
9 <value>hadoop3:50090</value>
10 </property>

![]()
【4】配置yarn-site.xml
1 <!-- Reducer获取数据的方式 -->
2 <property>
3 <name>yarn.nodemanager.aux-services</name>
4 <value>mapreduce_shuffle</value>
5 </property>
6
7 <!-- 指定YARN的ResourceManager的地址 -->
8 <property>
9 <name>yarn.resourcemanager.hostname</name>
10 <value>hadoop2</value>
11 </property>
十三、配置 SSH 免密配置
【链接】
十四、群起集群
【1】配置 slaves
[root@hadoop1 hadoop-2.7.2]# vi etc/hadoop/slaves
在该文件中增加如下内容: 该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
hadoop1
hadoop2
hadoop3
同步所有节点配置文件
[root@hadoop1 hadoop-2.7.2]# xsync etc/hadoop/slaves
【2】启动集群:如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[root@hadoop1 hadoop-2.7.2]# bin/hdfs namenode -format
【3】启动 HDFS(前提:终止之前运行namenode 等)
[root@hadoop1 hadoop-2.7.2]# sbin/start-dfs.sh
启动完成之后,Hadoop1 会启动 NameNode 和 DataNode,其他两台只会启动 DataNode
【4】在 Hadoop2 中启动YARN。注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在 ResouceManager所在的机器上启动 YARN。
[root@hadoop2 hadoop-2.7.2]# sbin/start-yarn.sh
【5】查看 SecondaryNameNode信息:http://hadoop3:50090/status.html
![]()
【6】 NameNode测试,创建 /user/zzx/input 并上传文件
1 [root@hadoop1 hadoop-2.7.2]# bin/hdfs dfs -mkdir -p /user/zzx/input
2 [root@hadoop1 hadoop-2.7.2]# bin/hdfs dfs -put input/zzx /user/zzx/input
【7】上传文件后查看文件存放在什么位置:查看 HDFS文件存储路径
1 [root@hadoop1 subdir0]# ll
2 总用量 8
3 -rw-r--r--. 1 root root 74 6月 21 19:19 blk_1073741825
4 -rw-r--r--. 1 root root 11 6月 21 19:19 blk_1073741825_1001.meta
5 [root@hadoop1 subdir0]# pwd
6 /opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-1538823143-192.168.52.131-1592727848753/current/finalized/subdir0/subdir0
十五、集群启动/停止方式总结
【1】 各个服务组件逐一启动/停止
1 #分别启动/停止HDFS组件
2 hadoop-daemon.sh start/stop namenode/datanode/secondarynamenode
3 #启动/停止YARN
4 yarn-daemon.sh start/stop resourcemanager/nodemanager
【2】 各个模块分开启动/停止(配置ssh是前提)
1 #整体启动/停止HDFS
2 start-dfs.sh/stop-dfs.sh
3 #整体启动/停止YARN
4 start-yarn.sh/stop-yarn.sh
最新文章
- 一些linux命令
- c语言结构体
- npm scripts构建
- ASP.NET MVC分页组件MvcPager 2.0版发布暨网站全新改版
- CodePen 作品秀:Canvas 粒子效果文本动画
- Mysql之mysqlbinlog使用
- 【转载】jQuery1.5之后的deferred对象详解
- Linux的学习路线图
- js的数组申明
- YTU 2621: B 继承 圆到圆柱体
- 单点登录系统构建之二——SSO原理及CAS架构
- 百度地图经纬度转换JS版
- Windows 8上强制Visual Studio以管理员身份运行
- 惠普 Compaq 6520s 无线开关打不开
- c++内存对齐 转载
- Weka学习 -- StringToWordVector 源代码学习(1)
- Duilib学习(一)
- Hibernate异常之Integer转float(自动类型转换错误)
- Spark思维导图之Shuffle
- LoadRunner脚本参数化之自动关联和手动关联