CeiT:Incorporating Convolution Designs into Visual Transformers
2024-09-08 15:08:43
CeiT:Incorporating Convolution Designs into Visual Transformers
将CNN提取low-level特征,强化局部特征提取的能力,与Transformer获取long-range信息的能力相结合提高模型性能。
Step1 : image-->tokens 利用卷积提取浅层特征信息
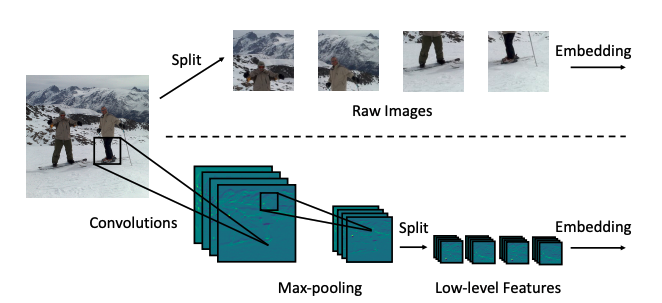
Vit将输入图像直接split成patch; CeiT利用conv+BN+Max-pooling提取浅层特征
Step 2 : 在空间维度上促进相邻token的相关性
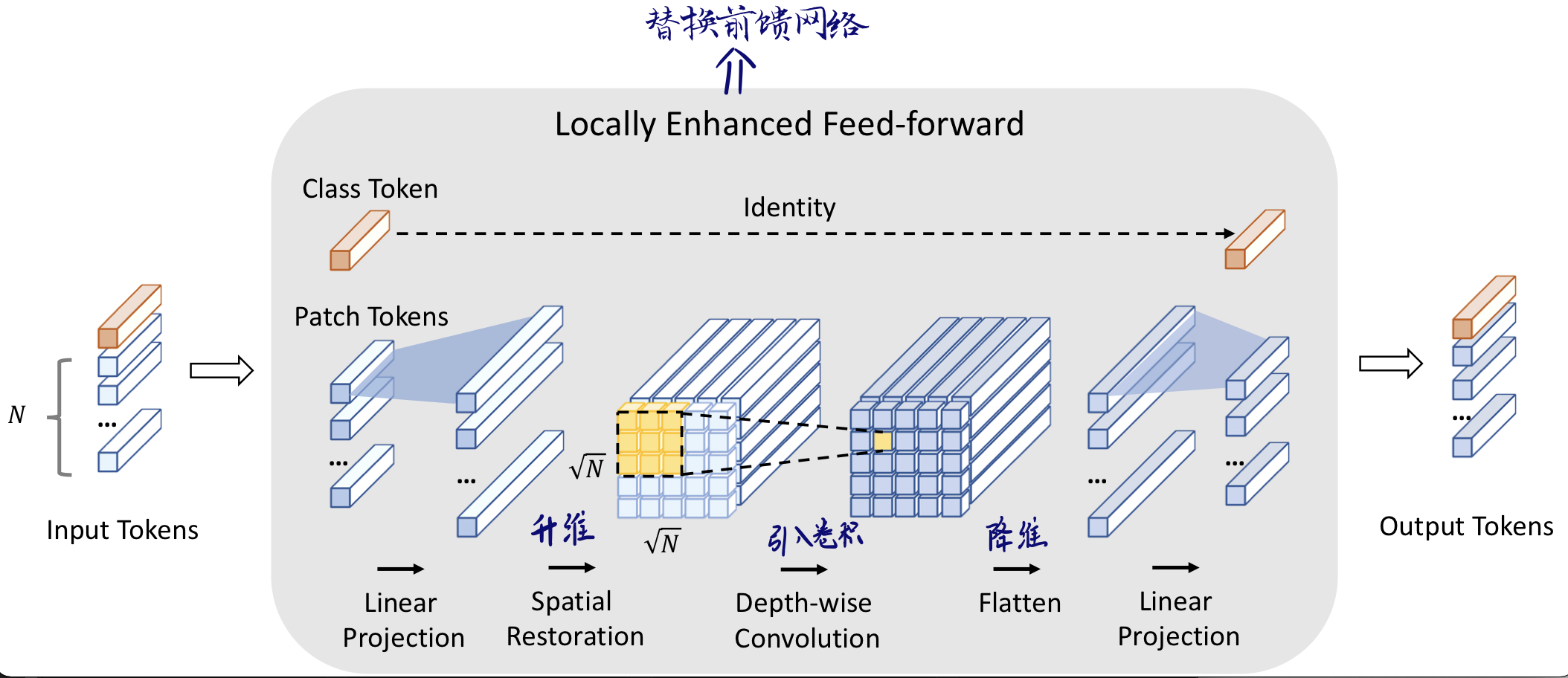
Step3: 综合不同层的信息,提出Layer-wise Class token Attention模块计算每层的class token的相互关系
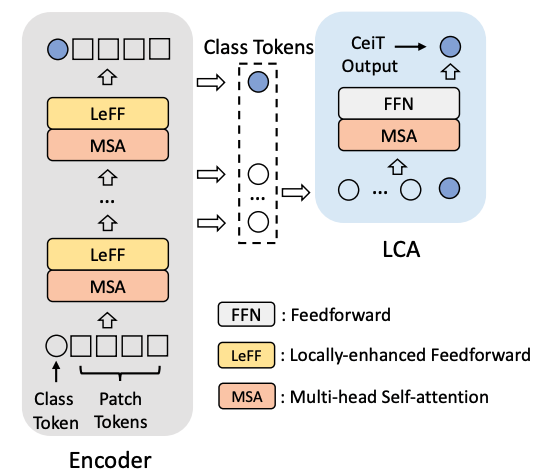
LCA模块的输入是不同层的class token
最新文章
- f2fs解析(六)
- Yii源码阅读笔记(十八)
- Linux 通过 load average 判断服务器负载情况
- 访谈将源代码的函数 strcpy/memcpy/atoi/kmp/quicksort
- 关于.ToList(): LINQ to Entities does not recognize the method ‘xxx’ method, and this method cannot be translated into a store expression.
- 如何在Byte[]和String之间进行转换
- 移动端touch点穿(穿透)解决办法
- Logistic Regression理论总结
- JPA:identifier of an instance of was altered from
- [Redux] redux之combineReducers
- Android艺术——深看Activity的生命周期
- python 中range函数的用法
- jquery <img> 图片懒加载 和 标签如果没有加载出图片或没有图片,就显示默认的图片
- SQL语句执行性能
- k近邻算法(KNN)
- DELPHI新的变量的声明方法
- windows下 两个版本的JDK环境变量进行切换 MARK
- clang命令理解程序
- ubuntu桌面安装常用软件&及常见问题
- BFC(块级格式化上下文)