NLP(一)
“自然语言处理”(Natural Language Processing 简称 NLP)包含所有用计算机对自然语言进行的操作。
自然语言工具包(NLTK)
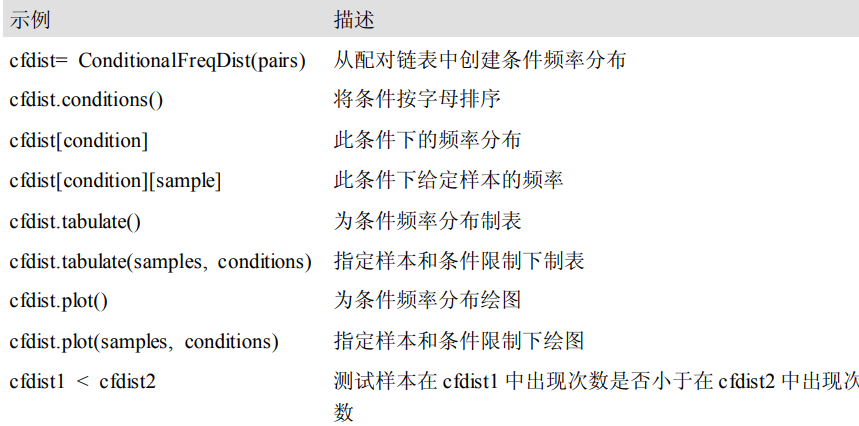
语言处理任务与相应 NLTK 模块以及功能描述
NLTK 频率分布类中定义的函数


示例:简单的语音对话系统的流程架构:
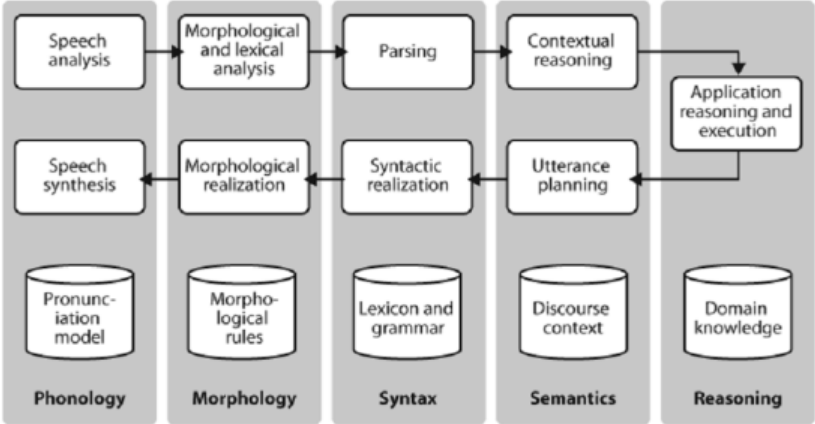
分析语音输入(左上),识别单词,文法分析和在 上下文中解释,应用相关的具体操作(右上);响应规划,实现文法结构,然后是适当的词 形变化,最后到语音输出;处理的每个过程都蕴含不同类型的语言学知识
在自然语言处理的实际项目中,通常要使用大量的语言数据或者语料库,
文本语料库的结构
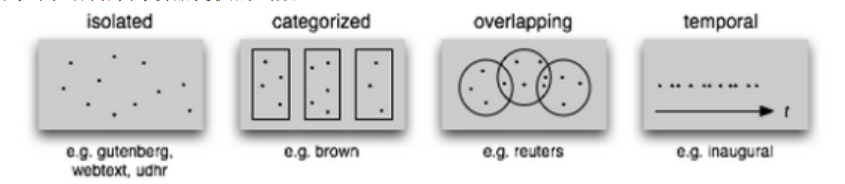
通常,文本会按照其可能对应的文体、来源、作者、 语言等分类。有时,这些类别会重叠,尤其是在按主题分类的情况下,因为一个文本可能与 多个主题相关。偶尔的,文本集有一个时间结构,新闻集合是最常见的例子
文本语料库的常见结构:最简单的一种语料库是一些孤立的没有什么特别的组织的 文本集合;一些语料库按如文体等分类组织结构;一些分类会重叠,如主题 类别;另外一些语料库可以表示随时间变化语言用法的改变。
NLTK 中定义的基本语料库函数



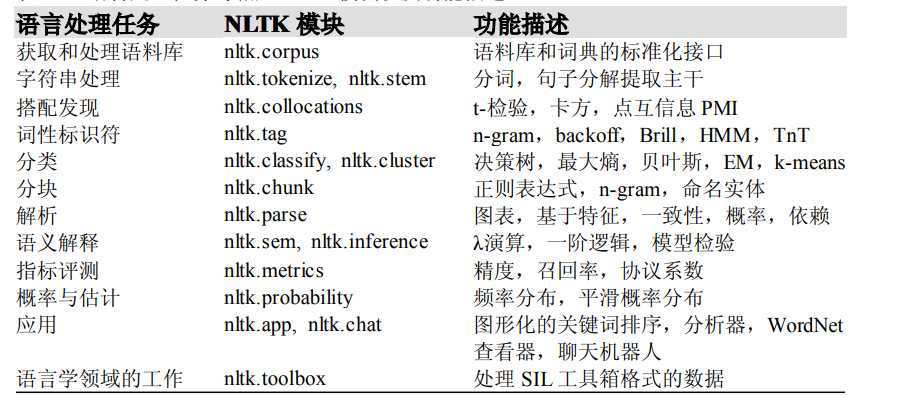
NLTK 中的条件频率分布:定义、访问和可视化一个计数的条件频率分布的常用方法和习惯用法
标注是典型的 NLP 流水线中分词之后的第二个步骤
将词汇按它们的词性(parts-of-speech,POS)分类以及相应的标注它们的过程被称为词 性标注(part-of-speech tagging, POS tagging)或干脆简称标注。词性也称为词类或词汇范 畴。用于特定任务的标记的集合被称为一个标记集。
分类是为给定的输入选择正确的类标签的任务。在基本的分类任务中,每个输入被认为 是与所有其它输入隔离的,并且标签集是预先定义的
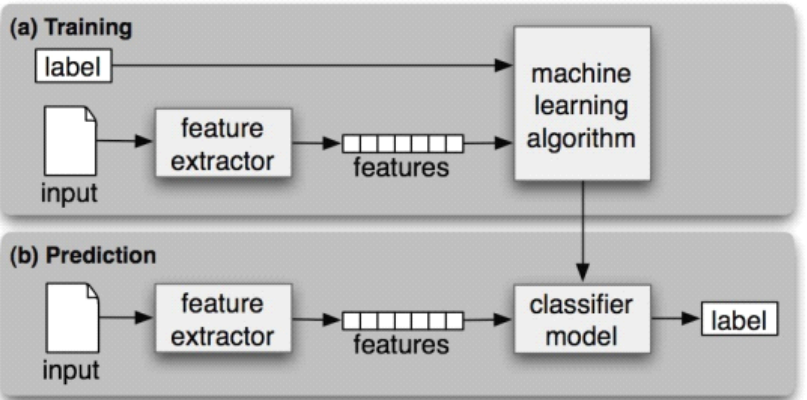
(a)在训练过程中,特征提取器用来将每一个输入值转换为特征集。 这些特征集捕捉每个输入中应被用于对其分类的基本信息,我们将在下一节中讨论它。特征 集与标签的配对被送入机器学习算法,生成模型。(b)在预测过程中,相同的特征提取器被 用来将未见过的输入转换为特征集。之后,这些特征集被送入模型产生预测标签
分类器可以帮助我们理解自然语言中存在的语言模式,允许我们建立明确的模型捕捉这些模式。
自动生成分类模型的三种机器学习方法:决策树、朴素贝叶斯分类器和最大熵分类器
最新文章
- 区块链(Blockchain)
- LINQ系列:Linq to Object相等操作符
- ASP.NET MVC之国际化(十一)
- Android QQ群:343816731 欢迎大家加入探讨
- Oracle索引简单介绍与示例
- 用友华表Cell一些用法小结(cs.net版本)
- 安装sqlserver2008r2 服务器配置,服务帐户配置出错,提示Sql server服务指定的凭据无效
- sublime相关设置
- 使用WebClient上传文件时的一些问题
- 破解简单Mifare射频卡密钥杂记
- Highcharts属性
- Linux笔记——linux下的语音合成系统
- SpringMVC拦截器和过滤器
- 01 The Learning Problem
- JAVA常见简答题
- Linux(Ubuntu)安装libpcap
- WebApi设置HttpContext.Current.User
- Paths on a Grid POJ - 1942 组合数学 (组合数的快速计算)
- AJAX请求头Content-type
- ACM-ICPC 2018 沈阳赛区网络预赛 J Ka Chang