Spark Streaming和Kafka整合是如何保证数据零丢失
转载:https://www.iteblog.com/archives/1591.html
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制。为了体验这个关键的特性,你需要满足以下几个先决条件:
1、输入的数据来自可靠的数据源和可靠的接收器;
2、应用程序的metadata被application的driver持久化了(checkpointed );
3、启用了WAL特性(Write ahead log);
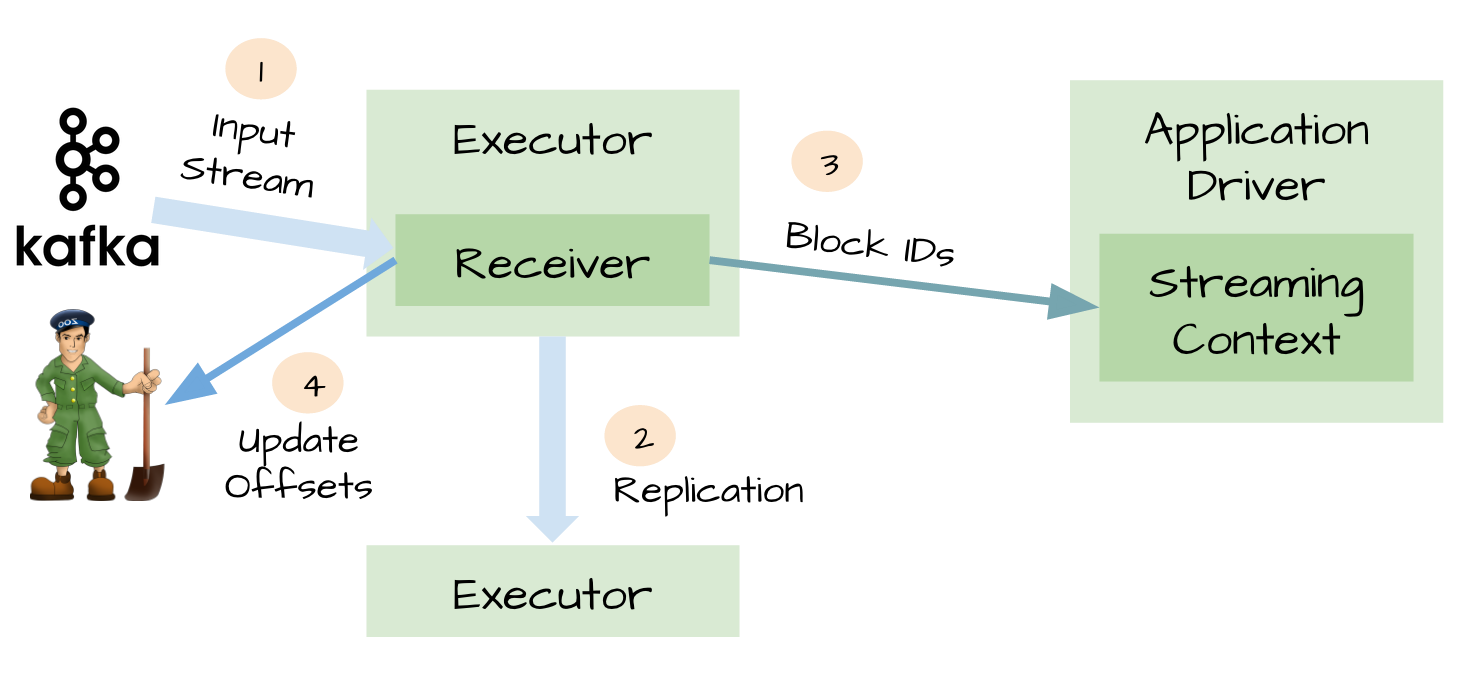
一、可靠的数据源和可靠的接收器
对于一些输入数据源(比如Kafka),Spark Streaming可以对已经接收的数据进行确认。输入的数据首先被接收器(receivers )所接收,然后存储到Spark中(默认情况下,数据保存到2个执行器中以便进行容错)。数据一旦存储到Spark中,接收器可以对它进行确认(比如,如果消费Kafka里面的数据时可以更新Zookeeper里面的偏移量)。这种机制保证了在接收器突然挂掉的情况下也不会丢失数据:因为数据虽然被接收,但是没有被持久化的情况下是不会发送确认消息的。所以在接收器恢复的时候,数据可以被原端重新发送。
二、元数据持久化(Metadata checkpointing)
可靠的数据源和接收器可以让我们从接收器挂掉的情况下恢复(或者是接收器运行的Exectuor和服务器挂掉都可以)。但是更棘手的问题是,如果Driver挂掉如何恢复?对此开发者们引入了很多技术来让Driver从失败中恢复。其中一个就是对应用程序的元数据进行Checkpint。利用这个特性,Driver可以将应用程序的重要元数据持久化到可靠的存储中,比如HDFS、S3;然后Driver可以利用这些持久化的数据进行恢复。元数据包括:
1、配置;
2、代码;
3、那些在队列中还没有处理的batch(仅仅保存元数据,而不是这些batch中的数据)

由于有了元数据的Checkpint,所以Driver可以利用他们重构应用程序,而且可以计算出Driver挂掉的时候应用程序执行到什么位置。
三、可能存在数据丢失的场景
令人惊讶的是,即使是可靠的数据源、可靠的接收器和对元数据进行Checkpint,仍然不足以阻止潜在的数据丢失。我们可以想象出以下的糟糕场景:
1、两个Exectuor已经从接收器中接收到输入数据,并将它缓存到Exectuor的内存中;
2、接收器通知输入源数据已经接收;
3、Exectuor根据应用程序的代码开始处理已经缓存的数据;
4、这时候Driver突然挂掉了;
5、从设计的角度看,一旦Driver挂掉之后,它维护的Exectuor也将全部被kill;
6、既然所有的Exectuor被kill了,所以缓存到它们内存中的数据也将被丢失。结果,这些已经通知数据源但是还没有处理的缓存数据就丢失了;
7、缓存的时候不可能恢复,因为它们是缓存在Exectuor的内存中,所以数据被丢失了。
这对于很多关键型的应用程序来说非常的糟糕,不是吗?
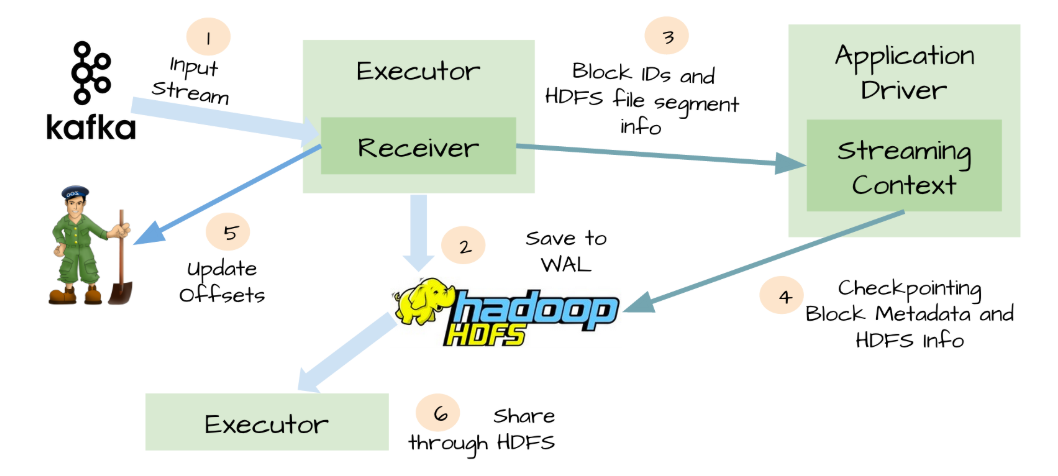
四、WAL(Write ahead log)
为了解决上面提到的糟糕场景,Spark Streaming 1.2开始引入了WAL机制。
启用了WAL机制,所以已经接收的数据被接收器写入到容错存储中,比如HDFS或者S3。由于采用了WAl机制,Driver可以从失败的点重新读取数据,即使Exectuor中内存的数据已经丢失了。在这个简单的方法下,Spark Streaming提供了一种即使是Driver挂掉也可以避免数据丢失的机制。
五、At-least-once语义
虽然WAL可以确保数据不丢失,它并不能对所有的数据源保证exactly-once语义。想象一下可能发生在Spark Streaming整合Kafka的糟糕场景。
1、接收器接收到输入数据,并把它存储到WAL中;
2、接收器在更新Zookeeper中Kafka的偏移量之前突然挂掉了;
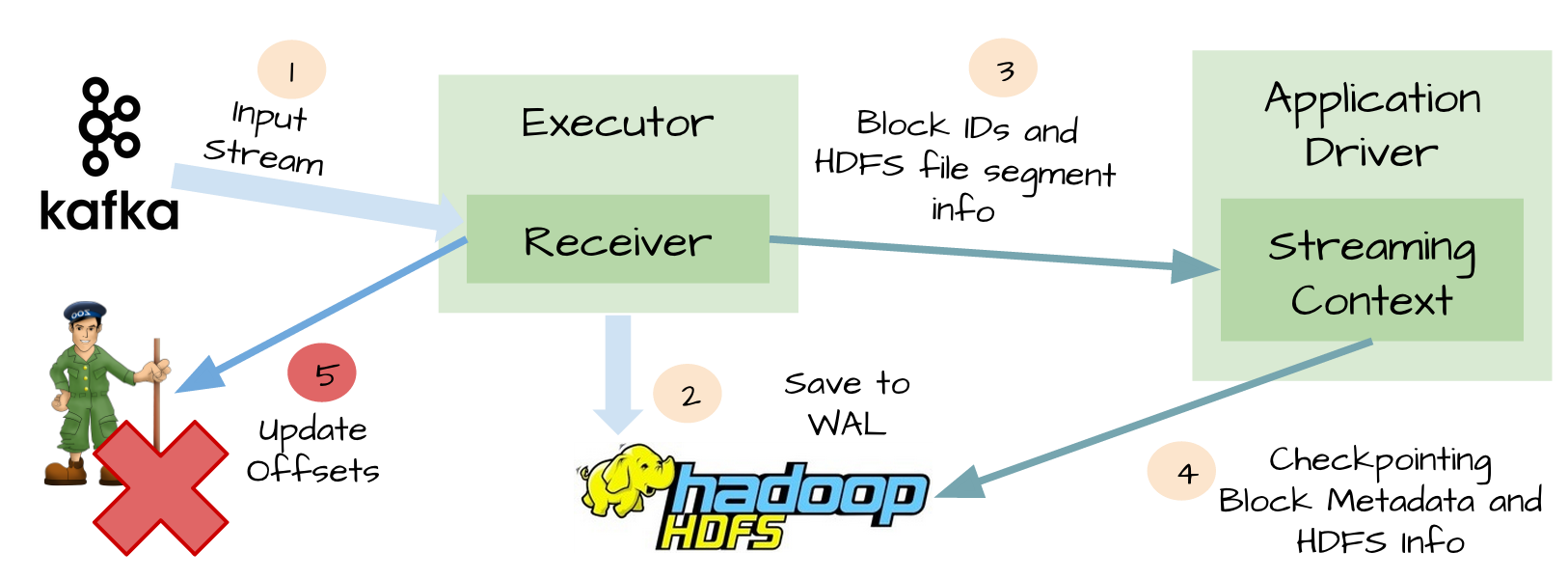
3、Spark Streaming假设输入数据已成功收到(因为它已经写入到WAL中),然而Kafka认为数据被没有被消费,因为相应的偏移量并没有在Zookeeper中更新;
4、过了一会,接收器从失败中恢复;
5、那些被保存到WAL中但未被处理的数据被重新读取;
6、一旦从WAL中读取所有的数据之后,接收器开始从Kafka中消费数据。因为接收器是采用Kafka的High-Level Consumer API实现的,它开始从Zookeeper当前记录的偏移量开始读取数据,但是因为接收器挂掉的时候偏移量并没有更新到Zookeeper中,所有有一些数据被处理了2次。
六、WAL的缺点
除了上面描述的场景,WAL还有其他两个不可忽略的缺点:
1、WAL减少了接收器的吞吐量,因为接受到的数据必须保存到可靠的分布式文件系统中。
2、对于一些输入源来说,它会重复相同的数据。比如当从Kafka中读取数据,你需要在Kafka的brokers中保存一份数据,而且你还得在Spark Streaming中保存一份。
七、Kafka direct API
为了解决由WAL引入的性能损失,并且保证 exactly-once 语义,Spark Streaming 1.3中引入了名为Kafka direct API。
这个想法对于这个特性是非常明智的。Spark driver只需要简单地计算下一个batch需要处理Kafka中偏移量的范围,然后命令Spark Exectuor直接从Kafka相应Topic的分区中消费数据。换句话说,这种方法把Kafka当作成一个文件系统,然后像读文件一样来消费Topic中的数据。

在这个简单但强大的设计中:
1、不再需要Kafka接收器,Exectuor直接采用Simple Consumer API从Kafka中消费数据。
2、不再需要WAL机制,我们仍然可以从失败恢复之后从Kafka中重新消费数据;
3、exactly-once语义得以保存,我们不再从WAL中读取重复的数据。
最新文章
- 浏览器内核、渲染引擎、js引擎
- Installation of Theano on Windows
- 【POJ】【3537】Crosses and Crosses
- 何使用CSS写出一个下拉菜单。
- 【REDO】删除REDO LOG重做日志组后需要手工删除对应的日志文件(转)
- 【数据标识】iOS App下载渠道的统计需求
- Mysql 保留最新的10条数据
- windy数(数位DP)
- python开发【第一篇】
- 浏览器中直接是使用react系列包开发,非打包方式。
- 文件上传详解 (HTML FILE)
- JDK动态代理深入理解分析并手写简易JDK动态代理(下)
- 【原创】大叔经验分享(23)spark sql插入表时的文件个数研究
- CDH 报错:under replicated blocks
- webpack学习笔记(六)优化
- .NET提供了三种后台输出js的方式:
- 基于python的websocket开发,tomcat日志web页面实时打印监控案例
- 转 $(document).ready()与window.onload的区别
- (面试题)如何查找Oracle数据库中的重复记录
- 重新找回spyder3-editor 里的code completion