Java对象布局
1. 引言
由于Java面向对象的思想,在JVM中需要大量存储对象,存储时为了实现一些额外的功能,需要在对象中添加一些标记字段用于增强对象功能 。在学习并发编程知识synchronized时,我们总是难以理解其实现原理,因为偏向锁、轻量级锁、重量级锁都涉及到对象头,所以了解java对象头是我们深入了解synchronized的前提条件
- 注意:本文所有代码基于JDK 1.8
2. 对象布局概述
HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)
从Java虚拟机Hotpot的源代码(openjdk)中,根据对象实例文件(jdk8/instanceOop.hpp at master · openjdk/jdk8 (github.com))中的代码:
#ifndef SHARE_VM_OOPS_INSTANCEOOP_HPP
#define SHARE_VM_OOPS_INSTANCEOOP_HPP
#include "oops/oop.hpp"
// An instanceOop is an instance of a Java Class
// Evaluating "new HashTable()" will create an instanceOop.
class instanceOopDesc : public oopDesc {
public:
// aligned header size.
static int header_size() { return sizeof(instanceOopDesc)/HeapWordSize; }
// If compressed, the offset of the fields of the instance may not be aligned.
static int base_offset_in_bytes() {
// offset computation code breaks if UseCompressedClassPointers
// only is true
return (UseCompressedOops && UseCompressedClassPointers) ?
klass_gap_offset_in_bytes() :
sizeof(instanceOopDesc);
}
static bool contains_field_offset(int offset, int nonstatic_field_size) {
int base_in_bytes = base_offset_in_bytes();
return (offset >= base_in_bytes &&
(offset-base_in_bytes) < nonstatic_field_size * heapOopSize);
}
};
#endif // SHARE_VM_OOPS_INSTANCEOOP_HPP
可以可到一个Java对象在内存中包含header、field、offset。Java对象的布局图示如下:
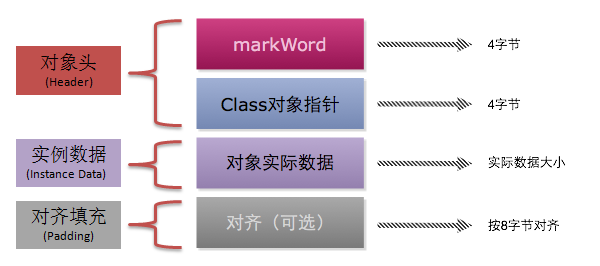
32位虚拟机:
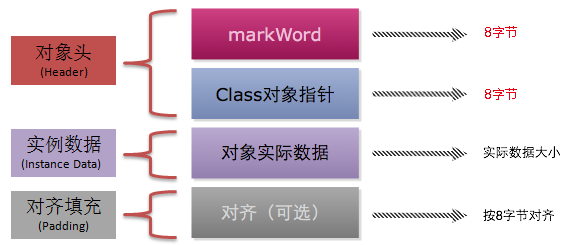
64位虚拟机:
图像来源:java对象在内存中的结构(HotSpot虚拟机) - duanxz - 博客园 (cnblogs.com)
如果对象是数组类型,占用4个字节/8个字节,因为JVM虚拟机可以通过Java对象的元数据信息确定Java对象的大小,但是无法从数组的元数据来确认数组的大小,所以用一块来记录数组长度:
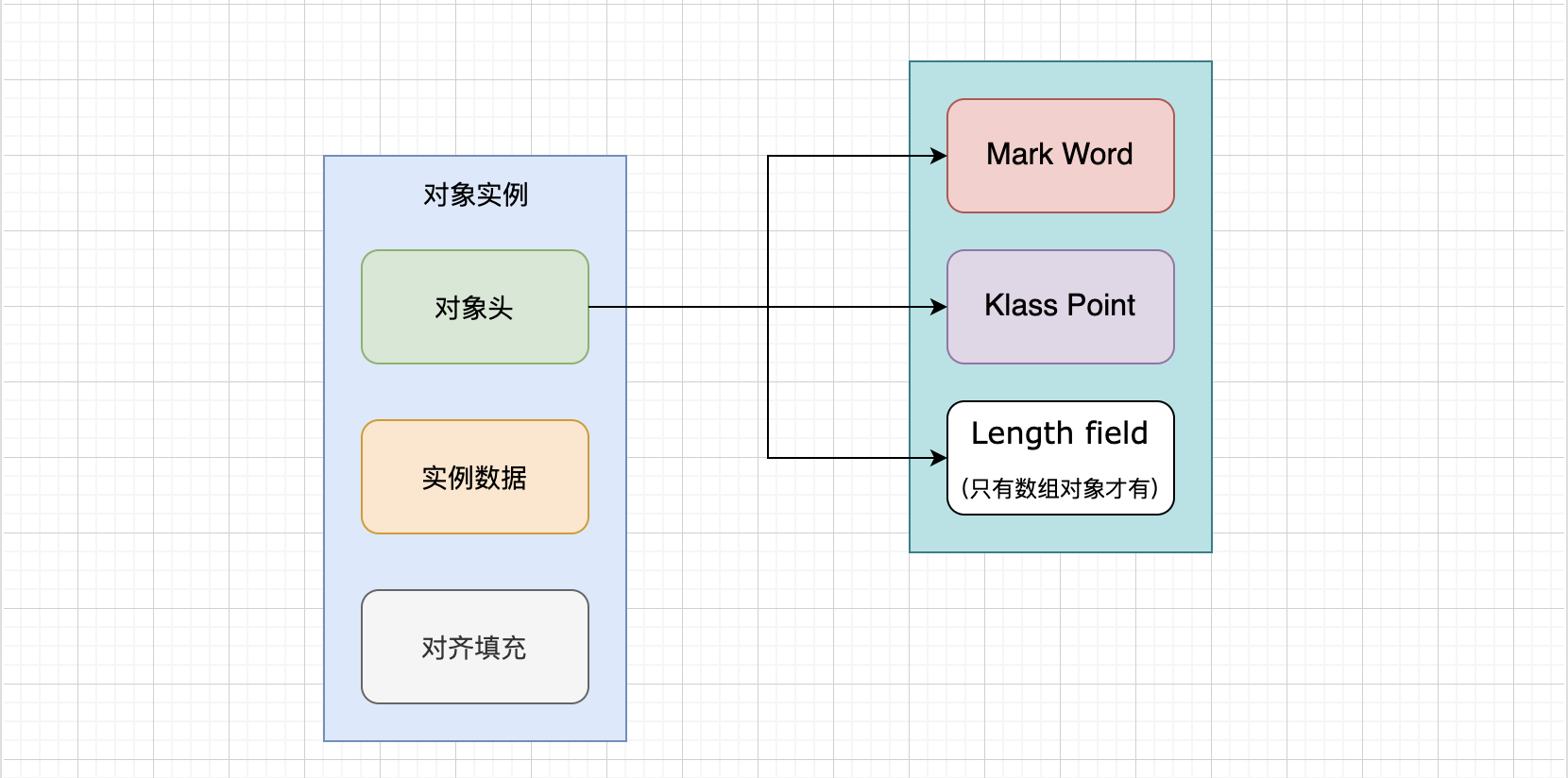
图像来源:Java对象的内存布局 - JaJian - 博客园 (cnblogs.com)
从上面的这张图里面可以看出,对象在内存中的结构主要包含以下几个部分:
- Header (对象头)
- Mark Word(标记字段):用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等
- Klass Pointer(Class对象指针):即类型指针,是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例
- 数组长度:如果对象是数组类型,记录数组长度
- Instance Data(对象实际数据):如果对象有属性字段,则这里会有数据信息。如果对象无属性字段,则这里就不会有数据。根据字段类型的不同占不同的字节,例如boolean类型占1个字节,int类型占4个字节等等
- Padding (对齐):如果上面的数据所占用的空间不能被8整除,padding则占用空间凑齐使之能被8整除。被8整除在读取数据的时候会比较快
为什么要对齐数据?
字段内存对齐的其中一个原因,是让字段只出现在同一CPU的缓存行中。如果字段不是对齐的,那么就有可能出现跨缓存行的字段。也就是说,该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。这两种情况对程序的执行效率而言都是不利的。其实对其填充的最终目的是为了计算机高效寻址。
3. Mark Word
HotSpot虚拟机的对象头包括两部分信息,第一部分是“Mark Word”,用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,这部分数据的长度在32位和64位的虚拟机(暂 不考虑开启压缩指针的场景)中分别为32个和64个Bits,官方称它为“Mark Word”。对象需要存储的运行时数据很多,其实已经超出了32、64位Bitmap结构所能记录的限度,但是对象头信息是与对象自身定义的数据无关的额 外存储成本,考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。
我们打开openjdk的源码包(openjdk/jdk8: Read-only mirror of https://hg.openjdk.java.net/jdk8 (github.com)),对应路径hotspot/src/share/vm/oops,Mark Word对应到C++的代码markOop.hpp,可以从注释中看到它们的组成:
// Bit-format of an object header (most significant first, big endian layout below):
//
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
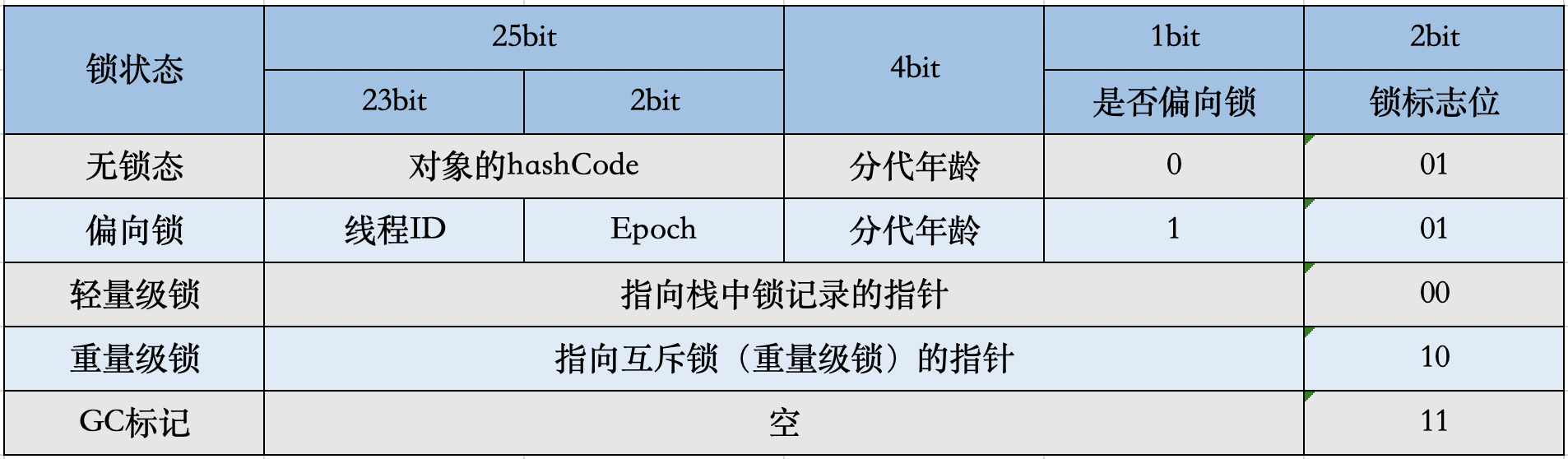
Mark Word在不同的锁状态下存储的内容不同,在32位JVM中是这么存的:
在64位JVM中是这么存的:
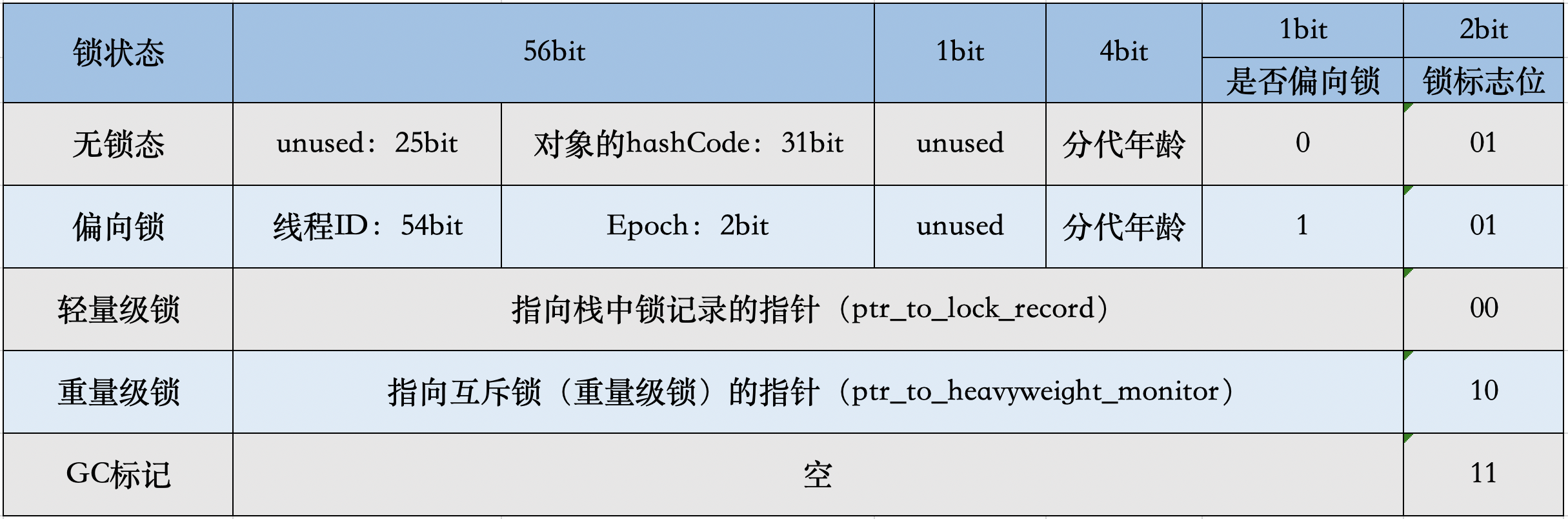
图像来源:Java对象的内存布局 - JaJian - 博客园 (cnblogs.com)
- 注意:如果对象是数组类型,则需要三个机器码,因为JVM虚拟机可以通过Java对象的元数据信息确定Java对象的大小,但是无法从数组的元数据来确认数组的大小,所以用一块来记录数组长度
虽然它们在不同位数的JVM中长度不一样,但是基本组成内容是一致的:
- 锁标志位(lock):区分锁状态,11时表示对象待GC回收状态, 只有最后2位锁标识(11)有效。
- biased_lock:是否偏向锁,由于无锁和偏向锁的锁标识都是 01,没办法区分,这里引入一位的偏向锁标识位。
- 分代年龄(age):表示对象被GC的次数,当该次数到达阈值的时候,对象就会转移到老年代。
- 对象的hashcode(hash):运行期间调用System.identityHashCode()来计算,延迟计算,并把结果赋值到这里。当对象加锁后,计算的结果31位不够表示,在偏向锁,轻量锁,重量锁,hashcode会被转移到Monitor中。
- 偏向锁的线程ID(JavaThread):偏向模式的时候,当某个线程持有对象的时候,对象这里就会被置为该线程的ID。 在后面的操作中,就无需再进行尝试获取锁的动作。
- epoch:偏向锁在CAS锁操作过程中,偏向性标识,表示对象更偏向哪个锁。
- ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针。当锁获取是无竞争的时,JVM使用原子操作而不是OS互斥。这种技术称为轻量级锁定。在轻量级锁定的情况下,JVM通过CAS操作在对象的标题字中设置指向锁记录的指针。
- ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针。如果两个不同的线程同时在同一个对象上竞争,则必须将轻量级锁定升级到Monitor以管理等待的线程。在重量级锁定的情况下,JVM在对象的ptr_to_heavyweight_monitor设置指向Monitor的指针。
我们通常说的通过synchronized实现的同步锁,真实名称叫做重量级锁。但是重量级锁会造成线程排队(串行执行),且会使CPU在用户态和核心态之间频繁切换,所以代价高、效率低。为了提高效率,不会一开始就使用重量级锁,JVM在内部会根据需要,按如下步骤进行锁的升级:
- 初期锁对象刚创建时,还没有任何线程来竞争,对象的Mark Word是下图的第一种情形,这偏向锁标识位是0,锁状态01,说明该对象处于无锁状态(无线程竞争它)。
- 当有一个线程来竞争锁时,先用偏向锁,表示锁对象偏爱这个线程,这个线程要执行这个锁关联的任何代码,不需要再做任何检查和切换,这种竞争不激烈的情况下,效率非常高。这时Mark Word会记录自己偏爱的线程的ID,把该线程当做自己的熟人。如下图第二种情形。
- 当有两个线程开始竞争这个锁对象,情况发生变化了,不再是偏向(独占)锁了,锁会升级为轻量级锁,两个线程公平竞争,哪个线程先占有锁对象并执行代码,锁对象的Mark Word就执行哪个线程的栈帧中的锁记录。如下图第三种情形。
- 如果竞争的这个锁对象的线程更多,导致了更多的切换和等待,JVM会把该锁对象的锁升级为重量级锁,这个就叫做同步锁,这个锁对象Mark Word再次发生变化,会指向一个监视器对象,这个监视器对象用集合的形式,来登记和管理排队的线程。如下图第四种情形。
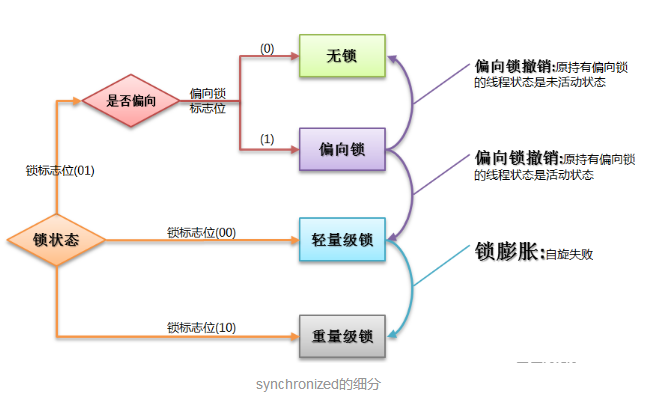
偏向锁Biased Locking:Java6引入的一项多线程优化,偏向锁,顾名思义,它会偏向于第一个访问锁的线程,如果在运行过程中,同步锁只有一个线程访问,不存在多线程争用的情况,则线程是不需要触发同步的,这种情况下,就会给线程加一个偏向锁。 如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会消除它身上的偏向锁,将锁恢复到标准的轻量级锁。
自旋锁:自旋锁的目的是为了占着CPU的资源不释放,等到获取到锁立即进行处理。一直在自旋也是占用CPU的,如果自旋的线程非常多,自旋次数也非常大CPU可能会跑满,所以需要升级。
重量级锁:内核态的锁,资源开销较大。内部会将等待中的线程进行wait处理,防止消耗CPU。
4. Klass Pointer
对象头的另外一部分是类型指针,这一部分用于存储对象的类型指针,该指针指向它的类元数据,JVM通过这个指针确定对象是哪个类的实例。该指针的位长度为JVM的一个字大小,即32位的JVM为32位,64位的JVM为64位。如果应用的对象过多,使用64位的指针将浪费大量内存,统计而言,64位的JVM将会比32位的JVM多耗费50%的内存。为了节约内存可以使用选项+UseCompressedOops开启指针压缩,其中,oop即ordinary object pointer普通对象指针。开启该选项后,下列指针将压缩至32位:
- 每个Class的属性指针(即静态变量)
- 每个对象的属性指针(即对象变量)
- 普通对象数组的每个元素指针
当然,也不是所有的指针都会压缩,一些特殊类型的指针JVM不会优化,比如指向PermGen的Class对象指针(JDK8中指向元空间的Class对象指针)、本地变量、堆栈元素、入参、返回值和NULL指针等。
5. 使用JOL验证
JOL(Java对象布局)是Tiny Toolbox,用于分析JVM中的对象布局。这些工具使用Unsafe、JVMTI和Serviceability Agent (SA) ,可重复解码实际对象布局,占用件和引用。这使得JOL比依赖于堆转储,规格假设等的其他工具更准确。
5.1. 创建maven项目
笔者使用IDEA创建一个maven项目
5.2. 添加maven依赖包
在pom.xml中添加:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
5.3. 创建类并输出JOL信息
创建一个空的新类并输出JOL信息:
import org.openjdk.jol.info.ClassLayout;
public class JolTest {
public static class T {
}
public static void main(String[] args) {
T t = new T();
System.out.println(ClassLayout.parseInstance(t).toPrintable());
}
}
输出信息:
JolTest$T object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 20 (01000011 11000001 00000000 00100000) (536920387)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
可以看到有 OFFSET、SIZE、TYPE DESCRIPTION、VALUE 这几个名词头,它们的含义分别是
- OFFSET:偏移地址,单位字节;
- SIZE:占用的内存大小,单位为字节;
- TYPE DESCRIPTION:类型描述,其中object header为对象头;
- VALUE:对应内存中当前存储的值,二进制32位;
输出信息图示:

可以看到,t对象实例共占据16byte,对象头(object header)占据12byte(96bit),其中 mark word占8byte(64bit),klass pointe 占4byte,另外剩余4byte是填充对齐的
这里由于默认开启了指针压缩 ,所以对象头占了12byte,具体的指针压缩的概念这里就不再阐述了,感兴趣的读者可以自己查阅下官方文档。jdk8版本是默认开启指针压缩的,可以通过配置vm参数开启关闭指针压缩,-XX:-UseCompressedOops
再次输出JOL信息:
JolTest$T object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 70 35 a4 17 (01110000 00110101 10100100 00010111) (396637552)
12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
关闭指针压缩重新打印对象的内存布局,可以发现总SIZE变大了,从下图中可以看到,对象头所占用的内存大小变为16byte(128bit),其中 mark word占8byte,klass pointe 占8byte,无对齐填充
创建一个数组对象:
import org.openjdk.jol.info.ClassLayout;
public class JolTest {
public static class T {
}
public static void main(String[] args) {
// T t = new T();
int[] t = {};
System.out.println(ClassLayout.parseInstance(t).toPrintable());
}
}
输出信息:
[I object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 6d 01 00 20 (01101101 00000001 00000000 00100000) (536871277)
12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
16 0 int [I.<elements> N/A
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
输出信息图示:

可以看到这时总SIZE为共16byte,对象头占16byte,其中Mark Work占8byte,Klass Point 占4byte,array length 占4byte,因为里面没有数据,所以数组对象的实例数据占据0byte,无填充
6. 参考资料
[1]java对象在内存中的结构(HotSpot虚拟机) - duanxz - 博客园 (cnblogs.com)
[2]Java对象的内存布局 - JaJian - 博客园 (cnblogs.com)
[3]openjdk/jdk8: Read-only mirror of https://hg.openjdk.java.net/jdk8 (github.com)
[4]openjdk/jol: https://openjdk.java.net/projects/code-tools/jol/ (github.com)
最新文章
- Java中的关键字 transient
- 洛谷 P2735 电网 Electric Fences Label:计算几何--皮克定理
- HTML引入外部文件,解决统一管理导航栏问题。
- 为什么要使用class.forname在DriverManager.getConnection之前
- BZOJ 3546 Life of the Party (二分图匹配-最大流)
- JSON数据格式以及与后台交互数据转换实例
- Linux 串行终端,虚拟终端,伪终端,控制终端,控制台终端的理解
- Entity Framework with MySQL 学习笔记一(拦截)
- 代码高亮插件Codemirror使用方法及下载
- Linux 查看支持的语言,日期,时间,计算器
- HttpClient的get和post方式提交数据的使用
- IOS开发根据字体大小等获取文字所占的高度
- idea 炫酷插件
- python异步编程--回调模型(selectors模块)
- 【shell脚本】通过遍历文件的一种批量执行shell命令的方法。
- P4385 [COCI2009]Dvapravca
- d3js网络拓扑关系特效可视化展现
- 理解同步,异步,阻塞,非阻塞,多路复用,事件驱动IO
- static_cast 和 dynamic_cast
- SQL语句往Oracle数据库中插入日期型数据(to_date的用法)