浅谈TreeMap以及在java中的使用
2024-10-08 22:47:00
本文为博主原创文章,转载请附带博客地址:https://www.cnblogs.com/xbjhs/p/8280714.html
treemap结构是红黑树
1.先介绍一下平衡二叉树
其特点是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。也就是说该二叉树的任何一个子节点,其左右子树的高度都相近。
2.红黑树(Red Black Tree) 是一种自平衡二叉查找树
(1)检索效率O(log n)
(2)红黑树的五点规定:
a每个节点都只能是红色或者黑色
b根节点是黑色
c每个叶节点(NIL节点,空节点)是黑色的。
d从每个叶子到根的所有路径上不能有两个连续的红色节点。
e从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
3.java中的定义:public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable
treeMap继承AbstractMap,实现NavigableMap、Cloneable、Serializable三个接口。而AbstractMap表明TreeMap为一个Map即支持key-value的集合。
4.java中的应用:
(1)TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) ,TreeMap是非同步的
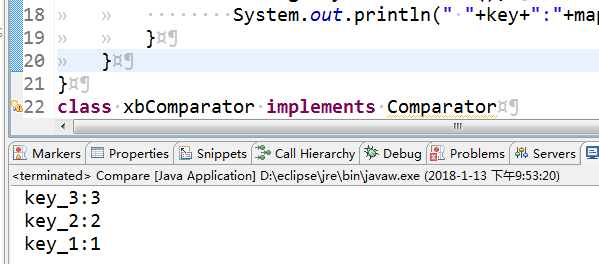
(2)TreeMap中默认的排序为升序,如果要改变其排序可以自己写一个Comparator
eg:
import java.util.Comparator;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap; public class Compare {
public static void main(String[] args) {
TreeMap<String,Integer> map = new TreeMap<String,Integer>(new xbComparator());
map.put("key_1", 1);
map.put("key_2", 2);
map.put("key_3", 3);
Set<String> keys = map.keySet();
Iterator<String> iter = keys.iterator();
while(iter.hasNext())
{
String key = iter.next();
System.out.println(" "+key+":"+map.get(key));
}
}
}
class xbComparator implements Comparator
{
public int compare(Object o1,Object o2)
{
String i1=(String)o1;
String i2=(String)o2;
return -i1.compareTo(i2);
}
}
(3)Tree的遍历
a遍历键值对
Integer value = null;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
value = (Integer)entry.getValue();
}
b遍历键
String key = null;
Integer value= null;
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
value= (Integer)map.get(key);
}
c遍历value
Integer value = null;
Collection c = map.values();
Iterator iter= c.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}
注:使用entrySet遍历方式要比keySet遍历方式快
entrySet遍历方式获取Value对象是直接从Entry对象中直接获得,时间复杂度T(n)=o(1);
keySet遍历获取Value对象则要从Map中重新获取,时间复杂度T(n)=o(n);keySet遍历Map方式比entrySet遍历Map方式多了一次循环,多遍历了一次table,当Map的size越大时,遍历的效率差别就越大。
最新文章
- RPC原来就是Socket——RPC框架到dubbo的服务动态注册,服务路由,负载均衡演化
- windows下安装php5.5的redis扩展
- nfs基本配置
- Java设计模式-命令模式(Command)
- iOS之block块
- 非sqlite和nigix的开源c项目
- java之两个字符串的比较
- oracle参数优化
- Hive 1、什么是Hive,Hive有什么用
- 在jQuery中Ajax的Post提交中文乱码的解决方案
- poj 1080
- 用memcached的时候找key找不到,写了个命令来找找
- IE各个版本的差异性
- [ZJOI 2006]物流运输
- Django-CRM项目学习(二)-模仿admin实现stark
- matplotlib 命令行画图保存
- 【jdbc】连接数据库从浅入深
- nginx负载均衡优化配置
- SQL-记录创建篇-006
- 384. Shuffle an Array数组洗牌