浅析Java中的集合
先了解一下集合与数组的区别:
数组是java中存储基本数据类型、引用类型的一种容器,但是数组的长度固定,不适合在对象数量未知的情况下使用。
集合只能存储引用类型的数据,长度可变,可在多数情况下使用。
集合框架
根据集合框架图,可以知道,集合总共分为 lterator、Collection、Map三大类,如下图
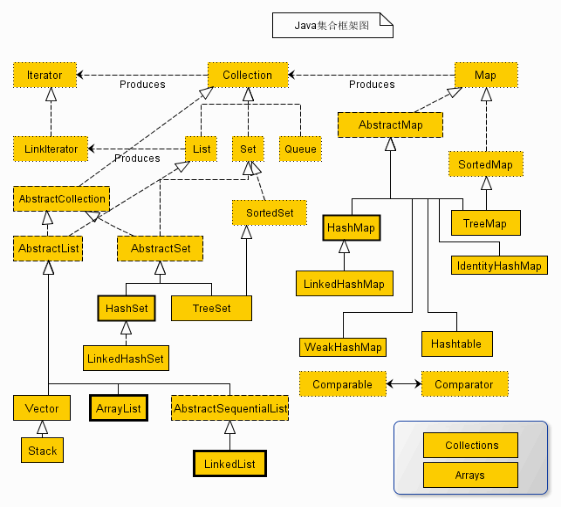
Collection接口是集合类的根接口,Java中没有提供这个接口的直接的实现类。但是却让其被继承产生了两个接口,就是Set和List。Set中不能包含重复的元素。List是一个有序的集合,可以包含重复的元素,提供了按索引访问的方式。
Map是Java.util包中的另一个接口,它和Collection接口没有关系,是相互独立的,但是都属于集合类的一部分。Map包含了key-value对。Map不能包含重复的key,但是可以包含相同的value。
Iterator,所有的集合类,都实现了Iterator接口,这是一个用于遍历集合中元素的接口,主要包含以下三种方法:
1.hasNext()是否还有下一个元素。
2.next()返回下一个元素。
3.remove()删除当前元素。
常用的集合类型:
1、List(有序、可重复)
List里存放的对象是有序的,同时也是可以重复的,List关注的是索引,拥有一系列和索引相关的方法,查询速度快。因为往list集合里插入或删除数据时,会伴随着后面数据的移动,所有插入删除数据速度慢。
2、Set(无序、不能重复)
Set里存放的对象是无序,不能重复的,集合中的对象不按特定的方式排序,只是简单地把对象加入集合中。
3、Map(键值对、键唯一、值不唯一)
Map集合中存储的是键值对,键不能重复,值可以重复。根据键得到值,对map集合遍历时先得到键的set集合,对set集合进行遍历,得到相应的值。
List分为Vector、ArrayList、LinkedList三种实现
ArrayList是一个可以处理变长数组的类型,这里不局限于“数”组,ArrayList是一个泛型类,可以存放任意类型的对象。
LinkedList是基于链表结构的所以它做增、删、改操作效率更高,也正是如此查询的效率比ArrayList要低。
另外,由于ArrayList、LinkedList的所有方法都是默认在单一线程下进行的,因此ArrayList、LinkedList不具有线程安全性。若想在多线程下使用,应该使用Colletions类中的静态方法synchronizedList()对ArrayList、LinkedList进行调用即可。
Vector也是一个类似于ArrayList的可变长度的数组类型,它的内部也是使用数组来存放数据对象的。值得注意的是Vector与ArrayList唯一的区别是,Vector是线程安全的,即它的大部分方法都包含有关键字synchronized,因此,若对于单一线程的应用来说,最好使用ArrayList代替Vector,因为这样效率会快很多(类似的情况有StringBuffer与StringBuilder);而在多线程程序中,为了保证数据的同步和一致性,可以使用Vector代替ArrayList实现同样的功能。
三者对比:
1、Vector、ArrayList都是以类似数组的形式存储在内存中,LinkedList则以链表的形式进行存储。
2、List中的元素有序、允许有重复的元素,Set中的元素无序、不允许有重复元素。
3、Vector线程同步,ArrayList、LinkedList线程不同步。
4、LinkedList适合指定位置插入、删除操作,不适合查找;ArrayList、Vector适合查找,不适合指定位置的插入、删除操作。
5、ArrayList在元素填满容器时会自动扩充容器大小的50%,而Vector则是100%,因此ArrayList更节省空间。
Set主要有HashSet、TreeSet
HashSet按照Hash算法存储集合中的元素,具有很好的存取和查找性能。当向HashSet中添加一些元素时,HashSet会根据该对象的HashCode()方法来得到该对象的HashCode值,然后根据这些HashCode的值来决定元素的位置。
TreeSet是SortedSet接口的实现类,TreeSet可以保证了集合元素处于排序状态(所谓排序状态,就是元素按照一定的规则排序,比如升序排列,降序排列)。
Map中主要有HashMap、HashTable、TreeMap
HashMap是最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为Null(多条会覆盖);允许多条记录的值为 Null。非同步的。
HashTable是同步的,而HashMap是非同步的,效率上比HashTable要高。HashMap允许空键值,而HashTable不允许。
TreeMap能够把它保存的记录根据键(key)排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
最新文章
- css3实现3D立体翻转效果
- LFI漏洞利用总结
- 温故而知新,jquery选择器$=
- 10.31Daily Scrum
- 【Entity Framework】 Entity Framework资料汇总
- bugfree如何修改Bug7种解决方案的标注方法
- UVA 12113 Overlapping Squares
- treeview 与tabControl组合使用
- 关于win10和sqlserver的兼容性
- JAVA基础总结2
- winform listview用法
- DVWA安装问题(phpStudy)
- JavaScript一看就懂(1)作用域
- paiza
- Vue.js + Nuxt.js 项目中使用 Vee-validate 表单校验
- Vue之项目搭建
- Docker inspect - format格式化输出 - 运维笔记
- java之旅_高级教程_java泛型
- 在PHP5.4上使用Google翻译的API报错
- jmeter对需要登录的接口进行性能测测试