HTML 解析类库HtmlAgilityPack
1. HtmlAgilityPack简介
网站中首先遇到的问题是爬虫和解析HTML的问题,一般情况在获取页面少量信息的情况下,我们可以使用正则来精确匹配目标。不过本身正则表达式就比较复杂,同时正则表达式的精确程度很难拿捏,太精确和原网页耦合太严重,页面代码稍改动就会使正则无效;太宽泛的正则由可能会匹配目标过多。所以我们今天介绍的是通过解析HTML结构来获取目标的方式——HtmlAgilityPack。
HtmlAgilityPack是一个解析HTML的类库,支持用XPath来解析HTML,可以像XML一样来解析HTML。
HtmlAgilityPack的代码托管在codeplex上:http://htmlagilitypack.codeplex.com/,不过建议通过Nuget来获取最新版本。
2. XPath简介
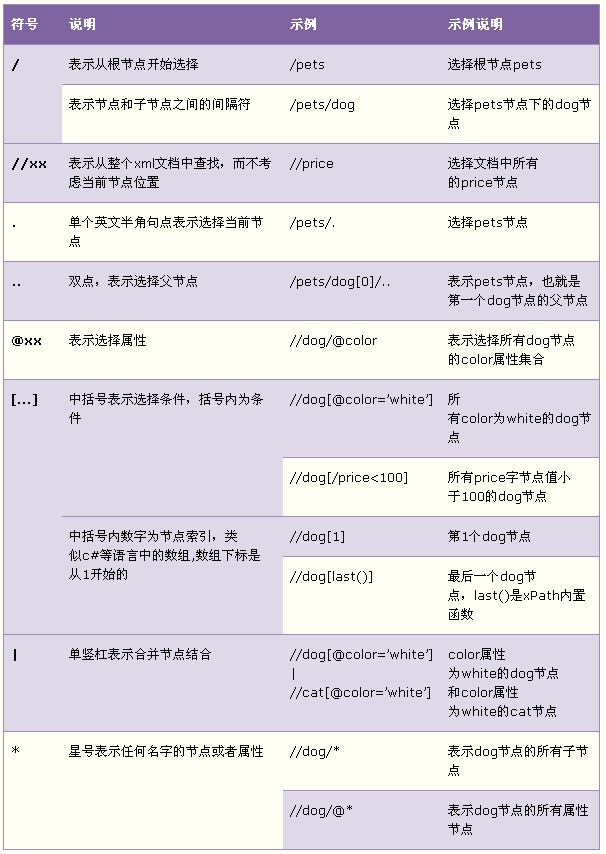
XPath即为XML路径语言,它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。下图列举了XPath主要的路径表达式:
这种针对XML的路径能在解析HTML中用的原因是HtmlAgilityPack将下载下来的HTML页面进行规格化处理,让原本对语义支持并不好的HTML文档格式变为更严谨的Xhtml格式,甚至可以转换为XML格式;并使用XPath来选择、处理dom中的element。下图表示HTML格式化之后的节点示意图:

3. HtmlAgilityPack中常用的API
在HtmlAgilityPack中常用到的类有HtmlDocument、HtmlNodeCollection、HtmlNode和HtmlWeb。
首先是加载HTML,如果是已经存在的静态HTML代码,可以用HtmlDocument的Load()或LoadHtml()来加载,如果是网络上的URL则需要用HtmlWeb的Get()或Load()方法来加载。
不管是哪种加载方式,我们得到的都是HtmlDocument的实例。此时我们需要得到的是HtmlNode或者HtmlNodeCollection对象,使用HtmlDocument的DocumentNode属性,它整个HTML文档的根节点,它本身也是一个HtmlNode。
得到文档根节点后即可使用前一节介绍的XPath得到你想要的文档中任意一个节点的信息。
下面是一个典型的获得有效内容的例子:
|
1
2
3
4
|
HtmlWeb htmlWeb = new HtmlWeb();HtmlDocument htmlDoc = htmlWeb.Load("http://www.baidu.com");HtmlNode htmlNode = htmlDoc.DocumentNode.SelectSingleNode("//title");string title = htmlNode.InnerText; |
由于使用最多的类是HtmlNode,这里将它常用的属性和方法列在下面,方便各位查阅。
属性:
Attributes 获取节点的属性集合
ChildNodes 获取子节点集合(包括文本节点)
FirstChild 获取第一个子节点
HasAttributes 判断该节点是否含有属性
HasChildNodes 判断该节点是否含有子节点
Id 获取该节点的Id属性
InnerHtml 获取该节点的Html代码
InnerText 获取该节点的内容,与InnerHtml不同的地方在于它会过滤掉Html代码,而InnerHtml是连Html代码一起输出
LastChild 获取最后一个子节点
Name Html元素名
NextSibling 获取下一个兄弟节点
ParentNode 获取该节点的父节点
PreviousSibling 获取前一个兄弟节点
XPath 根据节点返回该节点的XPath
方法:
HtmlNode AppendChild(HtmlNode newChild); 将参数元素追加到为调用元素的子元素(追加在最后)
void AppendChildren(HtmlNodeCollection newChildren); 将参数集合中的元素追加为调用元素的子元素(追加在最后)
HtmlNode PrependChild(HtmlNode newChild); 将参数中的元素作为子元素,放在调用元素的最前面
void PrependChildren(HtmlNodeCollection newChildren); 将参数集合中的所有元素作为子元素,放在调用元素前面
HtmlNode Clone(); 本节点克隆到一个新的节点
HtmlNode CloneNode(bool deep); 节点克隆到一个新的几点,参数确定是否连子元素一起克隆
HtmlNode CloneNode(string newName); 克隆的同时更改元素名
HtmlNode CloneNode(string newName, bool deep); 克隆的同时更改元素名。参数确定是否连子元素一起克隆
void CopyFrom(HtmlNode node); 创建重复的节点和其下的子树。
void CopyFrom(HtmlNode node, bool deep); 创建节点的副本。
static HtmlNode CreateNode(string html); 静态方法,允许用字符串创建一个新节点
IEnumerable<HtmlNode> DescendantNodes(); 获取所有子代节点
IEnumerable<HtmlNode> DescendantNodesAndSelf(); 获取所有的子代节点以及自身
IEnumerable<HtmlNode> Descendants(); 获取枚举列表中的所有子代节点
IEnumerable<HtmlNode> Descendants(string name); 获取枚举列表中的所有子代节点,注意元素名要与参数匹配
IEnumerable<HtmlNode> DescendantsAndSelf(); 获取枚举列表中的所有子代节点以及自身
IEnumerable<HtmlNode> DescendantsAndSelf(string name); 获取枚举列表中的所有子代节点以及自身,注意元素名要与参数匹配
HtmlNode Element(string name); 根据参数名获取一个元素
IEnumerable<HtmlNode> Elements(string name); 根据参数名获取匹配的元素集合
bool GetAttributeValue(string name, bool def); 帮助方法,用来获取此节点的属性的值(布尔类型)。如果未找到该属性,则将返回默认值。
int GetAttributeValue(string name, int def); 帮助方法,用来获取此节点的属性的值(整型)。如果未找到该属性,则将返回默认值。
string GetAttributeValue(string name, string def); 帮助方法,用来获取此节点的属性的值(字符串类型)。如果未找到该属性,则将返回默认值。
HtmlNode InsertAfter(HtmlNode newChild, HtmlNode refChild); 将一个节点插入到第二个参数节点的后面,与第二个参数是兄弟关系
HtmlNode InsertBefore(HtmlNode newChild, HtmlNode refChild); 讲一个节点插入到第二个参数节点的后面,与第二个参数是兄弟关系
static bool IsCDataElement(string name); 确定是否一个元素节点是一个 CDATA 元素节点。
static bool IsClosedElement(string name); 确定是否封闭的元素节点
static bool IsEmptyElement(string name); 确定是否一个空的元素节点。
static bool IsOverlappedClosingElement(string text); 确定是否文本对应于一个节点可以保留重叠的结束标记。
void Remove(); 从父集合中移除调用节点
void RemoveAll(); 移除调用节点的所有子节点以及属性
void RemoveAllChildren(); 移除调用节点的所有子节点
HtmlNode RemoveChild(HtmlNode oldChild); 移除调用节点的指定名字的子节点
HtmlNode RemoveChild(HtmlNode oldChild, bool keepGrandChildren);移除调用节点调用名字的子节点,第二个参数确定是否连孙子节点一起移除
HtmlNode ReplaceChild(HtmlNode newChild, HtmlNode oldChild); 将调用节点原有的一个子节点替换为一个新的节点,第二个参数是旧节点
HtmlNodeCollection SelectNodes(string xpath); 根据XPath获取一个节点集合
HtmlNode SelectSingleNode(string xpath); 根据XPath获取唯一的一个节点
HtmlAttribute SetAttributeValue(string name, string value); 设置调用节点的属性
string WriteContentTo(); 将该节点的所有子级都保存到一个字符串中。
void WriteContentTo(TextWriter outText); 将该节点的所有子级都保存到指定的 TextWriter。
string WriteTo(); 将当前节点保存到一个字符串中。
void WriteTo(TextWriter outText); 将当前节点保存到指定的 TextWriter。
void WriteTo(XmlWriter writer); 将当前节点保存到指定的则 XmlWriter。
4. 实战
基础的都熟悉了,我们来做练习。代码片段如下:
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(html);//加载html
string pageNumberPath = @"//*[@id='J_topPage']/span/i";
HtmlNode pageNumberNode = doc.DocumentNode.SelectSingleNode(pageNumberPath);
if (pageNumberNode != null)
{
string sNumber = pageNumberNode.InnerText;
for (int i = ; i < int.Parse(sNumber) + ; i++)
{
string pageUrl = string.Format("{0}&page={1}", category.Url, i);
try
{
List<Commodity> commodityList = GetCommodityList(category, pageUrl.Replace("&page=1&", string.Format("&page={0}&", i)));
commodityRepository.SaveList(commodityList);
}
catch (Exception ex)//保证一页的错误不影响另外一页
{
logger.Error("Crawler的commodityRepository.SaveList(commodityList)出现异常", ex);
}
}
5. 后记
HtmlAgilityPack 的确是一个功能强大的HTML解析类库,我目前仅仅使用了它的一小部分功能,但是已经能完全满足我的需求。如果童鞋们有类似需求,可以试试。
最新文章
- linux----------ab--性能测试工具
- http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html(转载)(原作者:AstralWind)
- hdu1150 匈牙利
- 关于Android开发中的证书和密钥等问题
- UML元素分析
- bzoj1797
- OD: Memory Attach Technology - Exception
- MTKdroidToolsV2.53 MTK安卓提取线刷资料的工具 使用教程
- Difference between TCP and UDP
- 【转】实用 .htaccess 用法大全
- 【javascript】详解javascript闭包 — 大家准备好瓜子,我要开始讲故事啦~~
- Web前端-CSS必备知识点
- Windows 下 Mysql8.0.12 的安装方法
- Python复习笔记(二)变量进阶
- C# Sublime text3 环境配置(二)
- oracle 问题
- 《JavaScript面向对象编程指南》
- 有关在 Word 中撰写博客的帮助
- python标准库介绍——28 sha 模块详解
- rabbitmq学习(四):利用rabbitmq实现远程rpc调用