python之scrapy模拟登陆人人网
2024-10-06 18:54:23
1、settings.py主要配置信息,包括USER_AGENT等
# -*- coding: utf-8 -*- # Scrapy settings for renren project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'renren' SPIDER_MODULES = ['renren.spiders']
NEWSPIDER_MODULE = 'renren.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36' # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'renren.middlewares.RenrenSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'renren.middlewares.RenrenDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'renren.pipelines.RenrenPipeline': 300,
#} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
2、rr.py,主要模拟登陆
# -*- coding: utf-8 -*-
import scrapy
import time
import re
class RrSpider(scrapy.Spider):
name = 'rr'
allowed_domains = ['renren.com']
start_urls = ['http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=201961933877'] def start_requests(self):
base_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp='
s = time.strftime("%S")
ms = int(round(time.time() % (int(time.time())), 3) * 1000)
date_time = '' + str(s) + str(ms)
login_url = base_url + date_time
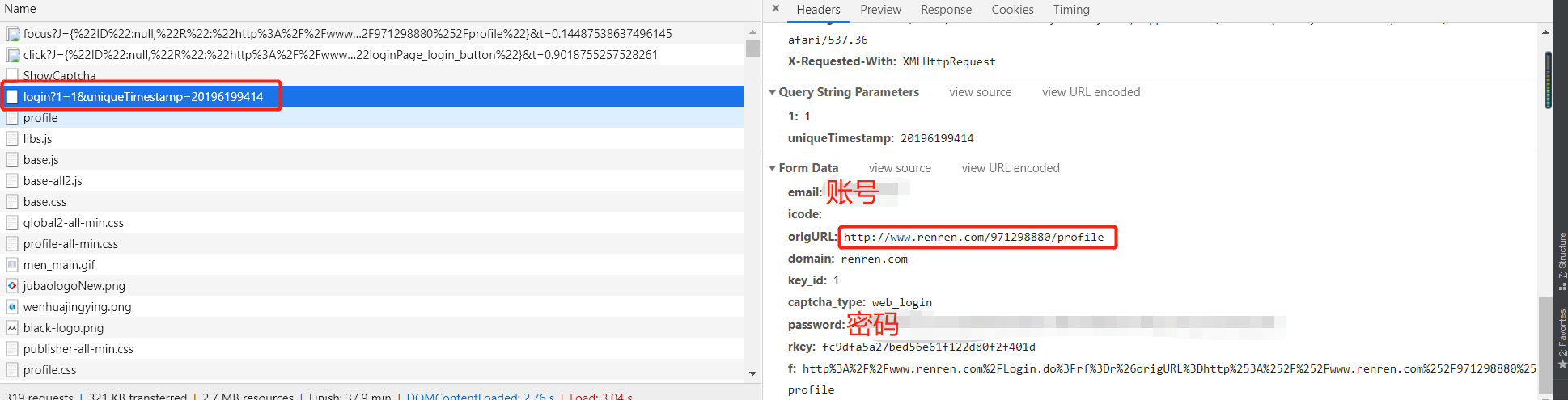
data = {'email': '',
'icode': '',
'origURL': 'http://www.renren.com/home',
'domain': 'renren.com',
'key_id': '',
'captcha_type': 'web_login',
'password': '41980c8f91e2c872910598a9e0a147d05934506893ef022c5b42357a67e0a3be',
'rkey': 'fc9dfa5a27bed56e61f122d80f2f401d',
'f':'http%3A%2F%2Fwww.renren.com%2FLogin.do%3Frf%3Dr%26origURL%3Dhttp%253A%252F%252Fwww.renren.com%252F971298880%252Fprofile'
}
yield scrapy.FormRequest(url=login_url, formdata=data, callback=self.parse_login, dont_filter=True) def parse_login(self, response):
yield scrapy.Request(url='http://www.renren.com/971298880/profile', callback=self.parse_text, dont_filter=True) def parse_text(self, response):
print(response.body.decode())
3、登陆信息
最新文章
- Android图片加载与缓存开源框架:Android Glide
- SQL温故系列两篇(一)
- jQuery对象与DOM对象之间的转换(转)
- Codeforces Round #366 (Div. 2) A
- linux 环境变量的设置【转】
- Tourism Planning(HDU 4049状压dp)
- linux ssh 配置 添加用户 另外一种方法
- angular2自学笔记---官网项目(一)
- jquery next nextAll nextUntil siblings的区别
- 有关ospf抓包
- 常用linux命令及其设置
- python之科学函数课——Numpy
- ubuntu14.04升级mysql5.5至mysql5.7
- Centos7更改网卡名称Eth0并配置静态IP
- Java J2EE读取配置文件
- Linux Shell脚本入门--wget 命令用法详解
- Hive desc
- Method for balancing binary search trees
- SSM框架文件远程服务器下载
- 线程组ThreadGroup
热门文章
- com.android.ddmlib.adbcommandrejectedexception:未经授权的设备。
- MySQL中添加、删除约束
- Appium Desired Capabilities-Android Only
- JDBC上
- 好不容易当上技术管理者,却时常担心被下属diss技术水平,怎么办?
- [TJOI2019]唱、跳、rap和篮球——容斥原理+生成函数
- getSuperclass与getGenericSuperclass区别
- <<代码大全>>阅读笔记之二 变量名的力量
- BZOJ 3630: [JLOI2014]镜面通道 (网络流 +计算几何)
- 【AndroidStudio-添加RecyclerView包】 AndroidStudio添加v7包中的RecyclerView