SPARK_sql加载,hive以及jdbc使用
sql加载


格式

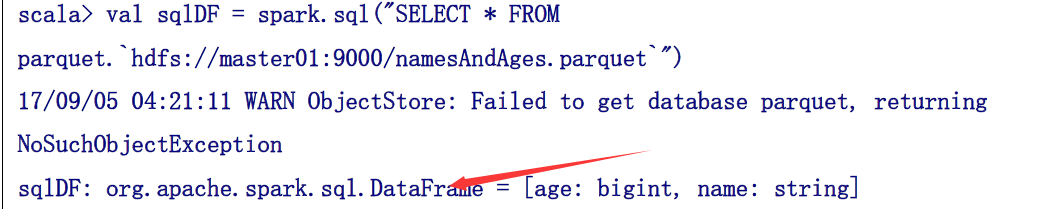
或者下面这种直接json加载

或者下面这种spark的text加载
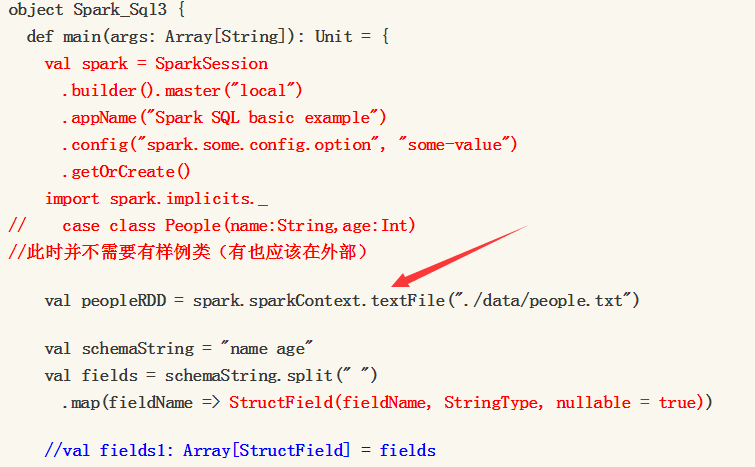

以及rdd的加载



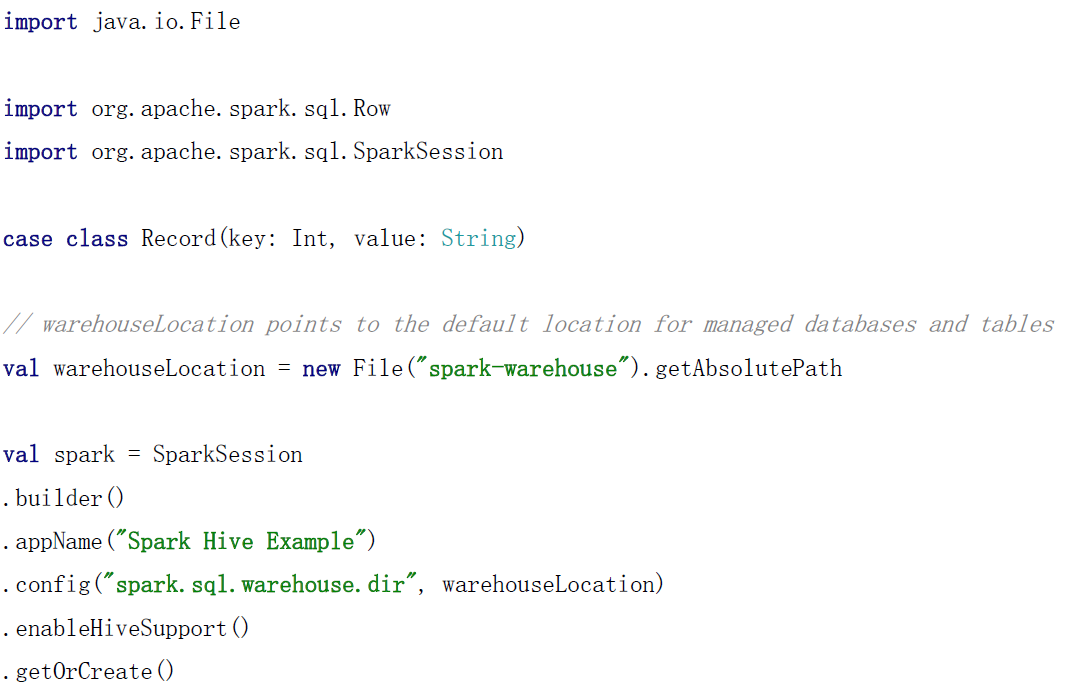
上述记得配置文件加入.mastrt("local")或者spark://master:7077


dataset的生成

下面是dataframe

下面是dataset





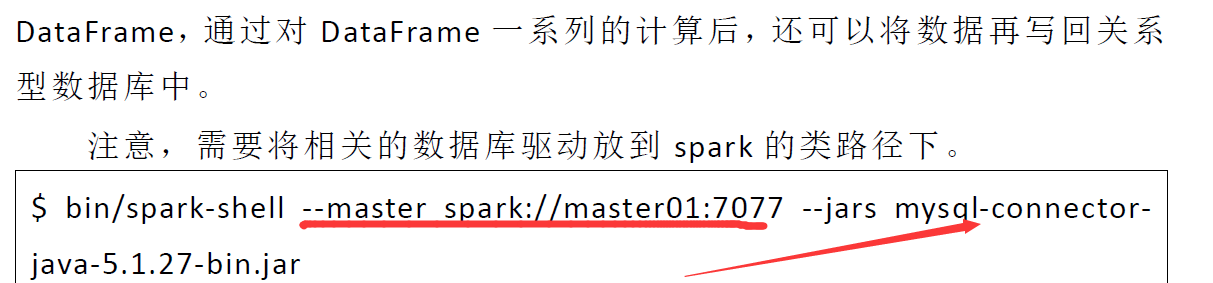
$ bin/spark-shell --master spark://master01:7077 --jars mysql-connector-java-5.1.27-bin.jar
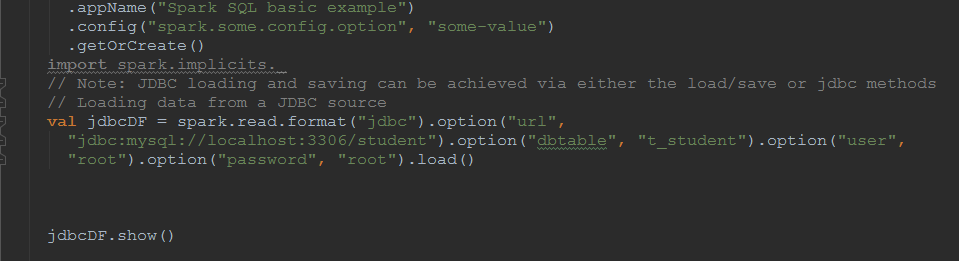
加载连接的两种方式

// Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
// Loading data from a JDBC source
val jdbcDF = spark.read.format("jdbc").option("url",
"jdbc:mysql://master01:3306/mysql").option("dbtable", "db").option("user",
"root").option("password", "hive").load()
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "hive")
val jdbcDF2 = spark.read .jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties)
保存数据的两种方式
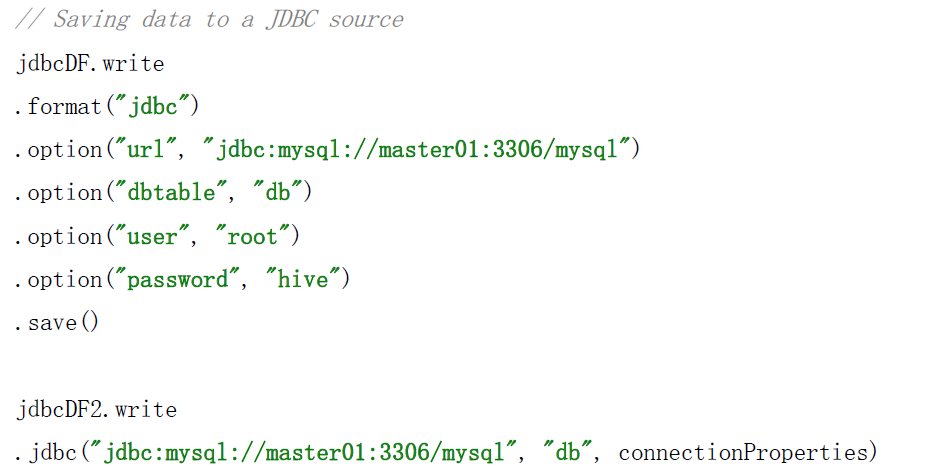
// Saving data to a JDBC source
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:mysql://master01:3306/mysql")
.option("dbtable", "db")
.option("user", "root")
.option("password", "hive")
.save()
jdbcDF2.write .jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties)

// Specifying create table column data types on write
jdbcDF.write
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties)





最新文章
- 初步认识Node 之Node为何物
- 延时调用--deferred.js原码分析
- unity3D5旧动画系统注意事项
- NK3C框架(MyBatis、Durid)连接SQL Server
- day15_集合第一天
- JS实例
- js根据id、pid把数据转为树结构
- 【转】MyBatis学习总结(七)——Mybatis缓存
- ssh 即使主机,同nohup背景脚本
- python爬虫数据解析之BeautifulSoup
- Python 爬虫 之 阅读呼叫转移(一)
- python 10大算法之二 LogisticRegression 笔记
- [树上倍增+二分答案][NOIP2012]运输计划
- python模块:time
- Intro to Jedis – the Java Redis Client Library
- 数据库设计和ER模型-------之ER模型的基本概念(第二章)
- kendoUpload
- 深入理解Linux网络技术内幕——内核基础架构和组件初始化
- Python【zip-map-filter】三个内置函数
- oracle RAC的客户端HA配置