G1垃圾收集或者Java中垃圾收集的名词收集
HotSpot
WTF,热壶?我他奶奶的还热火呢,Heat,you know?
总之HotSpot是一种遵循java虚拟机规范的一种实现啦,当时并不是Sun公司搞出来的,而是另外一家公司,后来被Sun公司收购了,anyway,现在都是Oracle的啦,Oracle表示,别抢,都是我的。
这又涉及到各种JVM的历史~
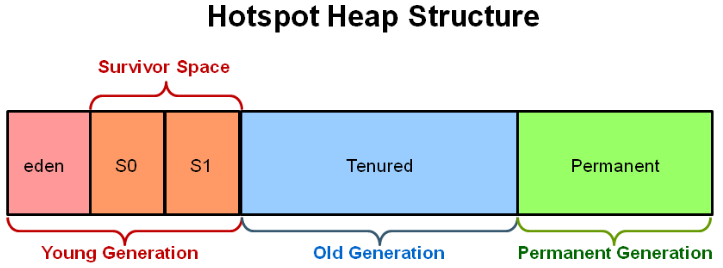
Java内存布局
想要搞懂Java中的垃圾回收,先得明白Java中的内存布局。

图 Java中的内存使用
现在来解读一下上的这张图。
Host Operating System:宿主机的内存。
JVM:是Java虚拟机所占用的内存。
Java Stack:是Java使用的栈区,方法的调用就是在这个部分完成的。其中包括了局部变量、方法和引用变量。
Perm Gen:是永久代
Java Heap:是Java的堆,所有的实例对象都是在堆中分配内存空间的。
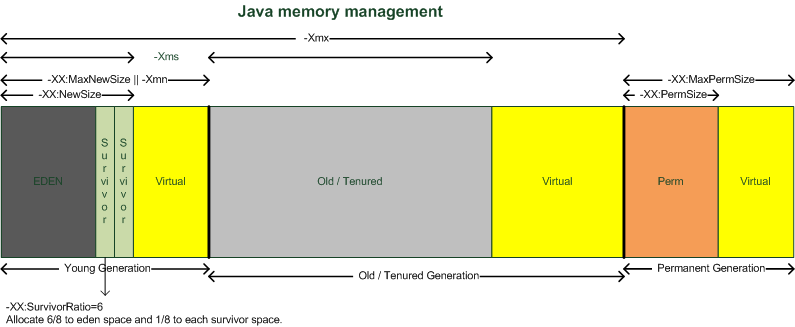
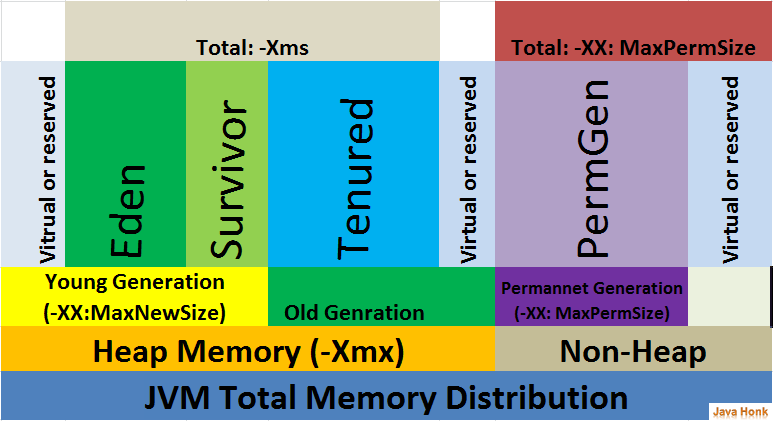
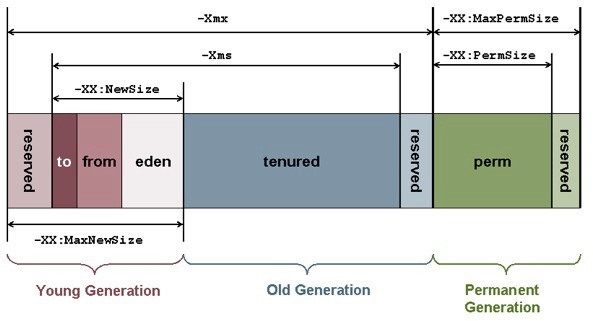
Java虚拟机的选项:
-Xss:每个线程所分配的栈内存,它的大小是和OS以及JVM相关的,通常其范围在256KB~1M之间。
-XX:最大的永久代大小
-Xmx:JVM最大的堆内存
-Xms:初始堆的大小
其他内存(other mem):包括了NIO的缓冲,JIT代码缓存,类加载器,Socket缓冲,JNI,GC内部信息等。
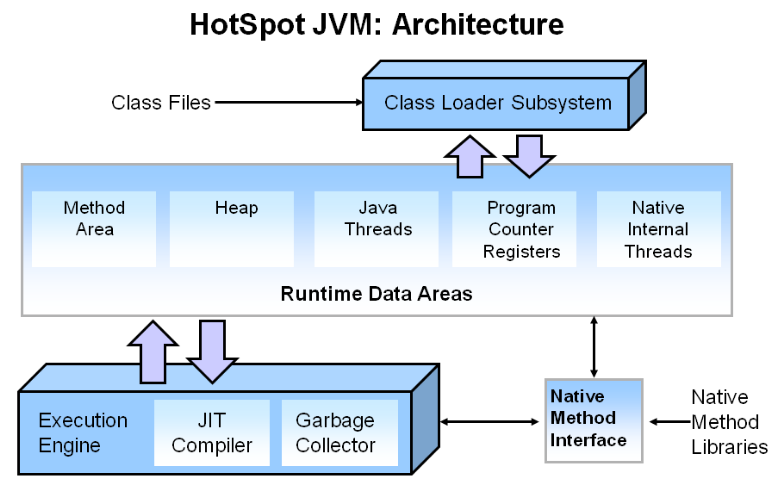
图 HotSpot JVM的架构
Class Files:文件
Class Loader Subsystem:类加载子系统
运行时数据区
Method Area:方法区
Heap:Java堆
Java Threads:Java线程
Program Counter Registers:程序计数器寄存器
Native Internal Threads:本地方法栈线程
执行引擎:
JIT Compiler:JIT编译器
Garbage Collector:垃圾收集器
Native Method Interface:本地方法接口
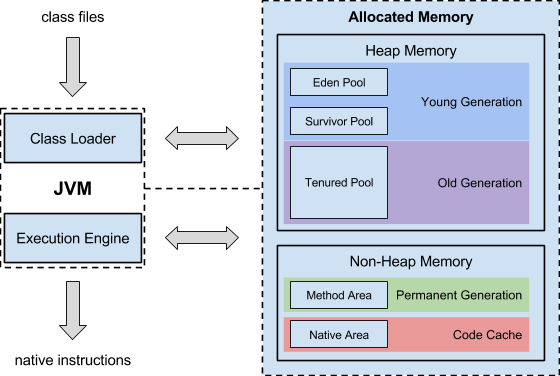
图 JVM架构图
这个图也比较有意思,
第一条线是:Class File ---> 类加载器 ---> 进入到了JVM中 ---> 执行引擎 ---> 本地代码指令
第二条是内存:非堆与堆
Java堆
Java堆是Java中所有对象分配的场所,方法中的变量,它只是一个变量而已,也可以看成一个句柄。真正的对象都是放在堆中的。
 这个图画的还挺好的,从Minor GC到Major GC再到Out of Memory,挺清楚的。
这个图画的还挺好的,从Minor GC到Major GC再到Out of Memory,挺清楚的。
还有很多的配置项也标注了,但是没有必要刻意地去记这些。
对象的生命周期(针对于内存中的变化)
- 大部分的对象都会在Eden空间中分配;
- 当Eden满了之后会触发一次minor GC;
- 可达的对象会移到Survivor空间;
- 这里有两个Survivor空间,存活下来的对象就在这两个Survivor空间中轮流复制。
以上过程在本文下面的一般垃圾回收过程中阐述地更加清晰。

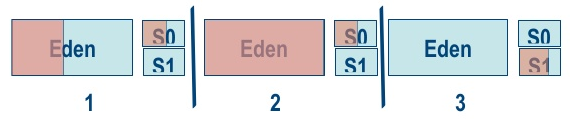
图 对象的生命周期
垃圾回收中有两个假设,官方称之为the Weak Generational Hypothesis:
- 大部分的对象都只会存活很短的一段时间;
- 少量的引用会从老的对象转移到新的对象。
基于这两个假设便有了分代收集的思想。
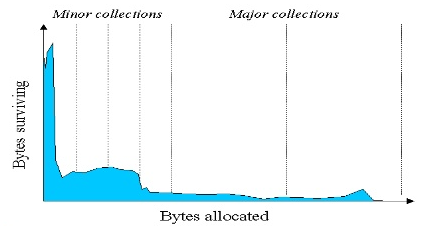
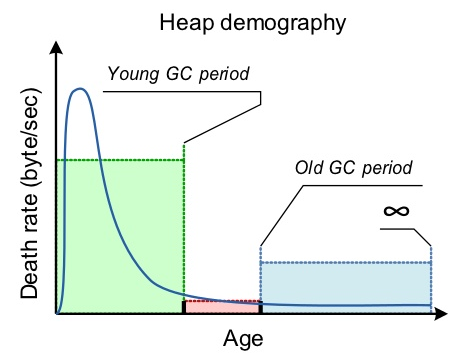
Java中垃圾收回的总结:
- 为了更好的进行垃圾收集,Java堆被分为三个generation。分别是年轻代,老年代和永久代。
- 在年轻代中存活下来的对象会进入老年代。
- Minor GC将Eden空间中的对象转移到Survivor1和Survivor2中,然后转移到老年代。
- 不管什么时候Major GC发生,应用线程都会停止,这将降低应用的性能。
- JVM命令行选项-Xmx和-Xms用来设定Java堆的最大和最小尺寸。理想的比例是1:1或者1:5。
- 在Java中暂时无法手动进行垃圾收集。
垃圾收集器
垃圾收集的概念很早了,不要以为就是Java中最早出现的。这玩意儿60年代就有了。垃圾收集器作用很简单,就是收集内存中不用了的、过时的对象,从从程序设计的角度来说,垃圾收集器就是线程,我可没有说几个线程,因为我也不知道,哈哈。


对象计数
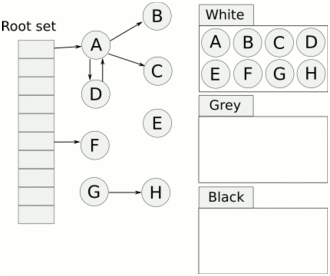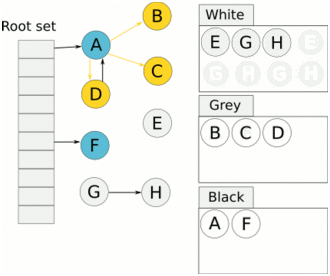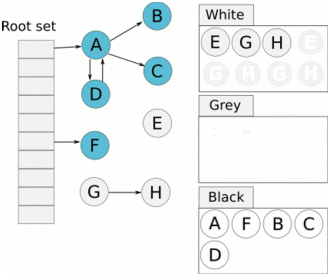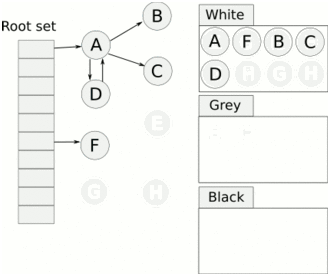
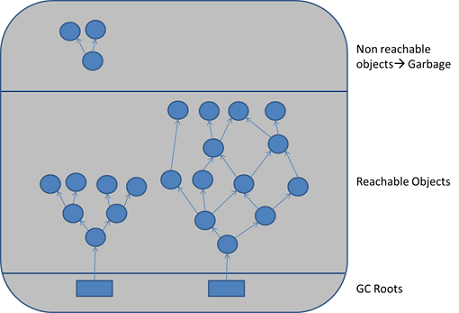
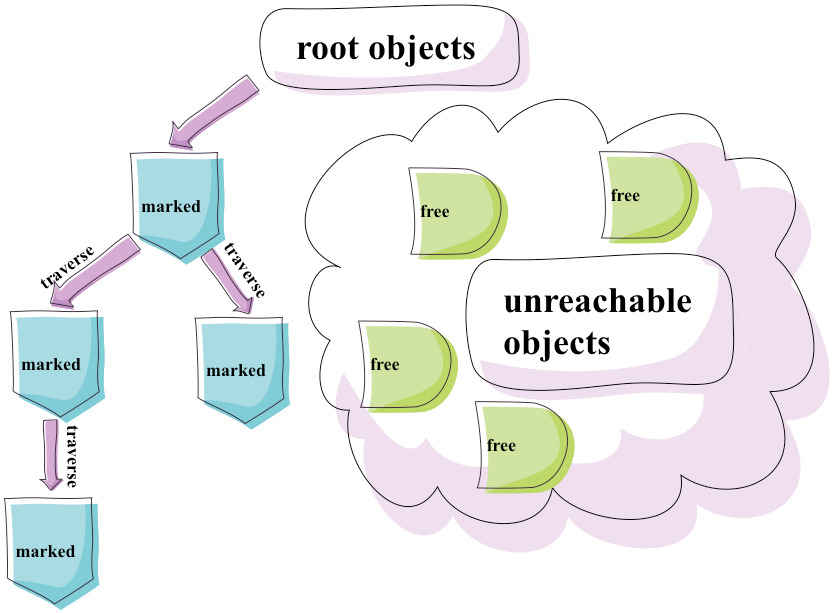
串行垃圾收集
串行和并行的区别就是只用一个单线程工作,实现起来比并行的复杂度低,需要很少的外部运行时数据结构,占用的空间大小(footprint)也是所有HotSpot垃圾收集器中最低的。
和并行相同的是:中断时间可能很长,随着堆的大小以及活跃的数据量变化,中断时间会线性增加或减少。
另外串行收集引发的长暂停更明显,因为只有一个线程完成垃圾收集工作。

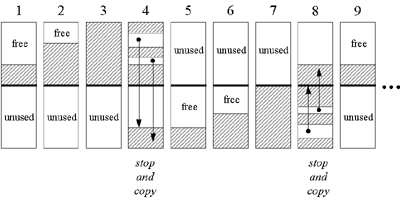
图 串行垃圾收集示意图

图 在新生代和老年代中的串行垃圾收集
因为占用很少的内存,HotSpot客户端虚拟机中默认使用串行垃圾收集器,同时用于大量嵌入式场景中。
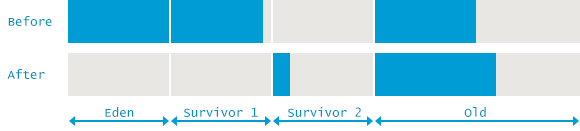
图 串行垃圾收集内存变化
并行垃圾收集
并行的意思是这是个多线程的垃圾收集过程。如果说一个垃圾收集过程被称之为并行的,那么就会有多个线程进行垃圾收集。
对于HotSpot中的垃圾收集器而言,几乎所有的多线程GC都是又JVM的内部线程处理的。
例外的是G1垃圾收集器,G1中的某些垃圾收集工作可以由应用线程来承担!

图 多个线程并行垃圾收集
并行垃圾收集器是一种stop-the-world的收集器,每发生垃圾收集的时候,会挂起所有的应用线程并用多个线程进行垃圾收集工作。
优点是垃圾收集可以不受任何中断,非常高效地完成。也是"最小化垃圾收集工作开销时间的最好方式"。
个别情况,因垃圾回收导致的应用中断也可能非常长。
并行垃圾收集被引入,主要是为了应对服务器端要求吞吐量最优化的场景,因此并行垃圾收集器已经成了HotSpot服务器端虚拟机的缺省收集器。
随着Java堆尺寸和老年代中存活对象的数量和大小的增长,老年代的垃圾收集时间变得越来越长,硬件线程出现了,使得可以增加多线程记性老年代收集与多线程的年轻代收集同时使用,增强了并行垃圾收集,降低了收集和压缩堆的时间开销。现在所说的并行垃圾收集就包括了多线程的老年代和多线程的年轻代。

图 串行和并行垃圾收集对比
并行垃圾收集的适用场景:
1. 对应用吞吐量的要求远远高于对延迟的要求,比如批处理应用
2. 如果能满足应用的最差延迟要求,并行垃圾收集器将提供最佳的吞吐量。最差延迟包含两个:最差延迟时间和中断发生频率。
在大多数的应用中,应用线程的数量往往超过GC线程的数量。
一次full GC必须标记整个Java堆空间,同时还要压缩老年代空间,结果使得随着Java堆空间的增大,暂停时间也会随之增加。
并发标记清除(CMS)垃圾收集器
并发的意思是在Java应用执行的过程中,垃圾收集活动也在进行。
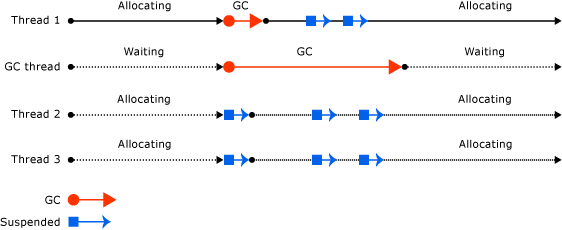
图 并发垃圾收集
完全串行或者并行的垃圾收集器都有其弊端,比如中断时间太长,漫长的GC中断数量,因此希望在牺牲一些吞吐量的情况下来缓解此种情况。CMS垃圾收集器被开发出来了。
在CMS垃圾收集过程中,年轻代的垃圾收集与并行垃圾收集器很类似,它们是并行而且会stop-the-world,也就是说在年轻代的垃圾收集时所有的Java应用线程都会停止。并行垃圾收集和CMS垃圾收集的区别在于老年代。CMS试图在老年代收集的时候避免应用线程长时间的中断。为此,CMS老年代收集在应用线程执行的时候偷偷摸摸的干了很多不为人知的事情。绝大多数情况下CMS是并发的,老年代的某些过程会暂停应用线程,比如初始标记和重新标记阶段。
有一个特殊的情况是,老年代正在进行的时候,突然发生了年轻代的收集,这时候老年代的垃圾收集会让位于年轻代,直到后者结束后马上恢复。
CMS CG的缺省年轻代垃圾收集是ParNew。
使用CMS垃圾收集的一个挑战是要在Java堆空间用完之前完成并发收集工作。需要找到一个合适的时机来完成这个,而且CMS会比并行GC要多占用10%~20%的Java堆空间。这也是为了缩短垃圾收集所付出的代价。
还有一个就是,CMS垃圾收集器的另一个挑战就是如何如理老年代中的碎片,也就是老年代的碎片太小无法容纳年轻代中的对象,因为CMS的并发收集循环中并不进行压缩,哪怕是局部的压缩。
一旦无法找到可用空间,就会使CMS回过来串行GC,触发一次full收集,导致一个漫长的暂停。
解决:避免生成大尺寸对象。
CMS做到了你在嗑瓜子,你妈仍旧可以打扫房间~

图 串行垃圾收集VS并行垃圾收集VS并发垃圾收集
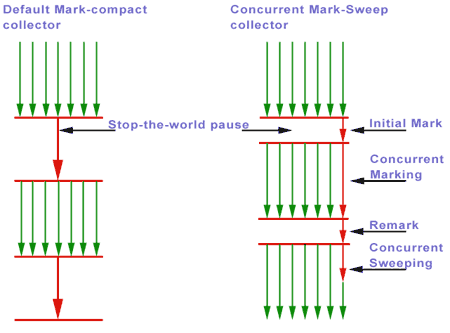
图 标记压缩VS并发标记清除

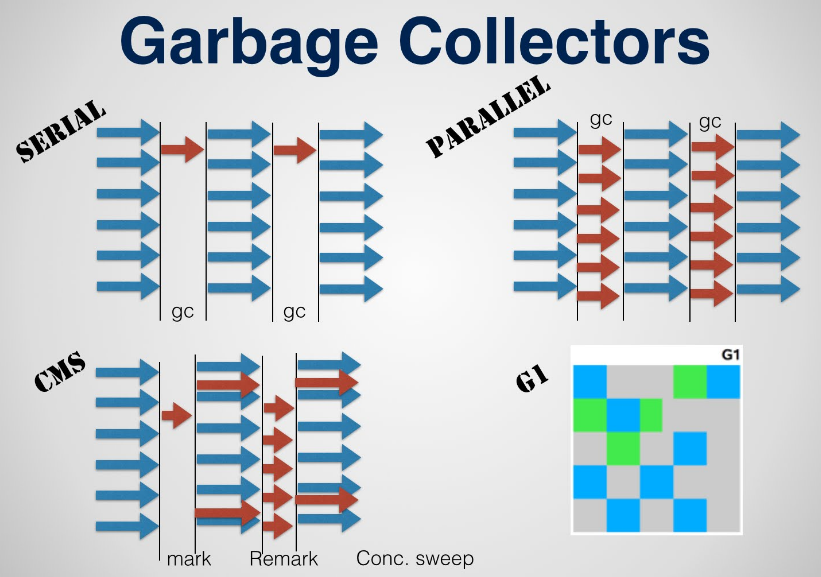
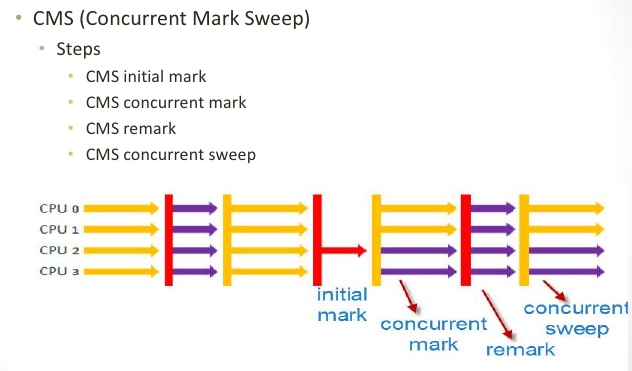

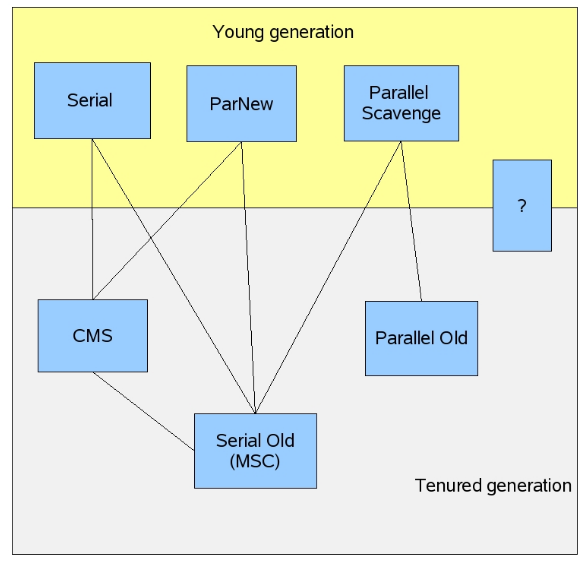 图 不同垃圾收集器的组合方案
图 不同垃圾收集器的组合方案
Garbage First,请问啥叫Garbage First?
尼玛都是Garbage了,还first,second,我不是针对谁,在座的各位都是垃圾!!!
增量垃圾回收
增量GC是一种GC(废话),它的存在是为了解决标记清除的长停顿问题(就是由于垃圾太多,虚拟机大哥清理了好久都没干完,不能腾出空来干正事)。
它有一个原则:
- 垃圾永远是垃圾,不管GC跑了几遍都是垃圾
还有一个策略:
新生的对象不是垃圾
当虚拟机访问一个对象的时候,该对象及其相关的对象不是垃圾。
增量GC名称的由来跟全量GC相对,就是每次只处理一小部分的对象。
上面的算法缩短了「GC平均中断时间」,但是在对实时性要求很高的程序中,对「GC最高中断时间」的要求更高。比如,自动驾驶软件,如果某次GC中断了0.1s,那么损失可能是致命的。
增量回收就是将GC分成几部分来执行。设置「GC最多中断10ms」这样的条件限制来使GC的终端时间视作可预测的。
但是,在两段的GC程序之间,引用关系可能发生了变化。所以,这种GC算法也要写屏障,来记录引用关系的变化。虽然这种方式控制了中断最高时间,但是由于中断次数增加,GC总时间是增加的。
垃圾收集器的度量
垃圾收集中关键性能的度量有如下几个指标:
- 吞吐率(Throughput):没有花在垃圾收集时间上的百分比,长时间运行的时候才考虑这个。
- 暂停时间(Pause):因为GC发生而导致应用无法响应的时间。
- 垃圾收集的频率(Frequency):垃圾收集多久发生一次,这个和应用的执行情况有关。
- 及时性(Promptness):从对象死亡到其占用的内存被回收花的时间。
- 占用的空间(Footprint):程序的working set,以使用的内存页和缓存来度量的。
收集周期
大概意思就是每过多长时间进行一次垃圾收集任务。
G1中的三种垃圾收集周期:年轻代收集周期、多级并发标记周期和混合收集周期
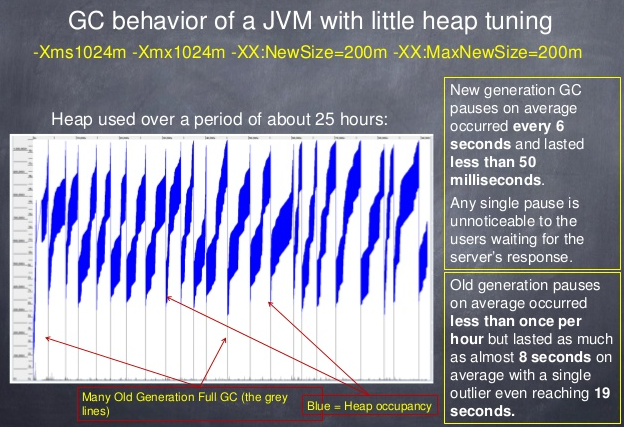
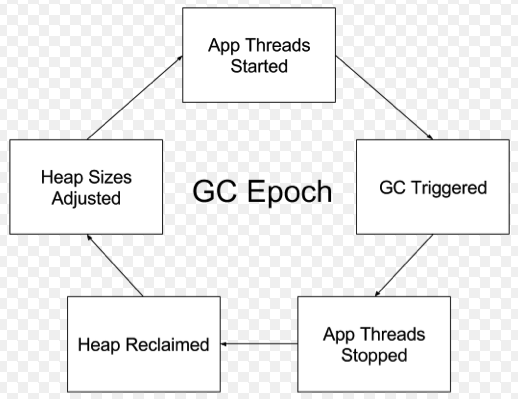
stop-the-world式垃圾收集、暂停
stop-the-world的意思是,在进行垃圾收集的时候所有的Java应用线程都被挂起,只进行垃圾收集。
就像你正在家里玩,你妈说要做大扫除了,然后把你赶出去,说:”先出去玩一会,等我弄完了你再回来!“
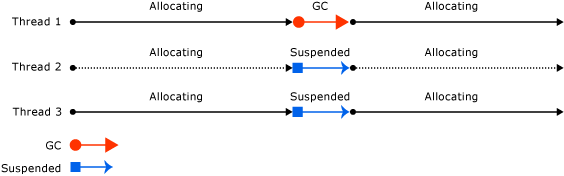
图 一个线程引发了stop-the-world垃圾收集,导致其他线程也挂起
并行的垃圾收集引入HotSpot时,只有对年轻代会使用并行stop-the-world收集器。老年代的回收是使用一个单线程的stop-the-world收集器。
一般垃圾收集过程
现在你理解了Java堆是分成了不同的generation之后,是时候这些空间之间是怎么转变和交互的了。以下描述了对象在JVM中是如何分配和老化的。
1. 任何新的对象都会在eden空间上进行分配。所有的survivor空间开始都是空的。

2. 当eden空间满了之后,会触发一次minor gc。
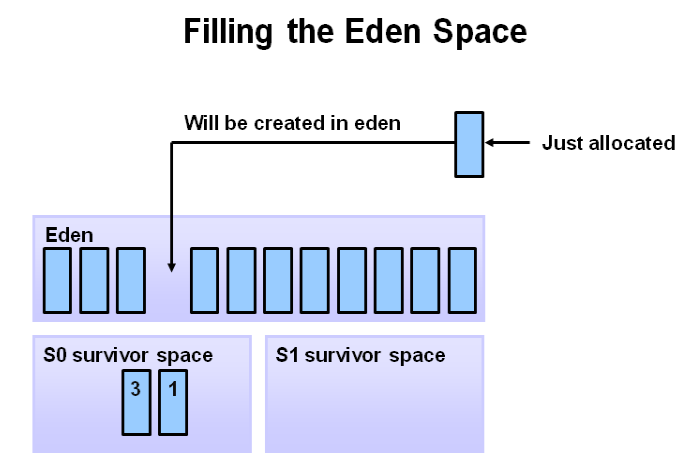
3. 引用的对象会移到第一个survivor空间。当eden空间被清理的时候未被引用的对象会被回收。

4. 在下一次minor GC的时候,eden空间上的回收过程是一样的。未被引用的对象占用的空间被回收,而引用的对象则会被移到survivor空间。然而,在这种情况下他们会被移到第二个survivor空间(S1)。除此之外,上一次minor GC中,survivor空间(S0)中的对象的年龄会增加,然后移到S1中。一旦所有的对象都被转移到S1中,S0和eden空间都将被清理。这里要注意到S1中有不同年龄的对象。
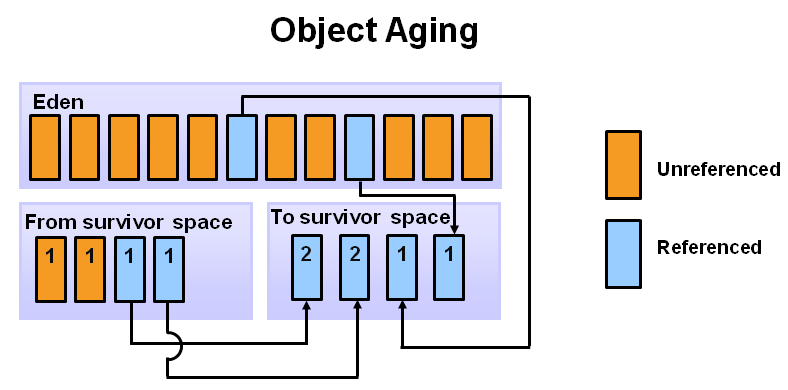
5. 在下一次minor GC的时候,会重复相同的过程。然而这次survivor的空间会交换。引用的对象被移到S0中。存活的对象年龄有增加了。Eden和S1都被清理了。
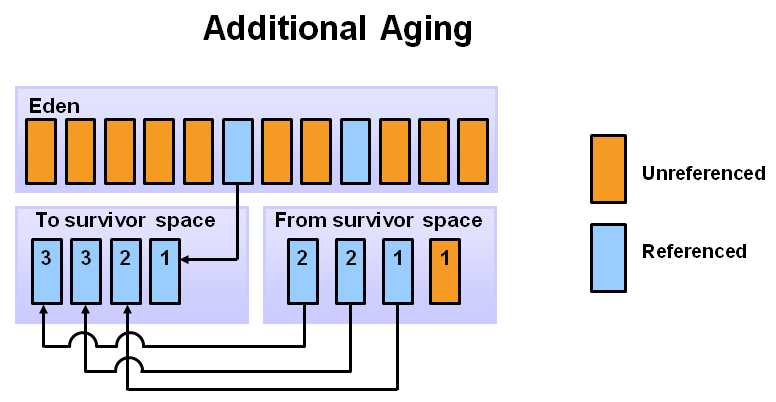
6. 这次演示的是promotion。在一次minor CG之后,当老化的对象达到了某个年龄的阈值(比如8),那么这些老化的对象会从年轻代转移到老年代中。
 7. 当minor GC继续被触发,不断有对象提升到老年代中。
7. 当minor GC继续被触发,不断有对象提升到老年代中。
 8. 当整个程序中有很多的年轻代对象,最终导致老年代中发生了major GC,将会清理并压缩老年代空间。
8. 当整个程序中有很多的年轻代对象,最终导致老年代中发生了major GC,将会清理并压缩老年代空间。
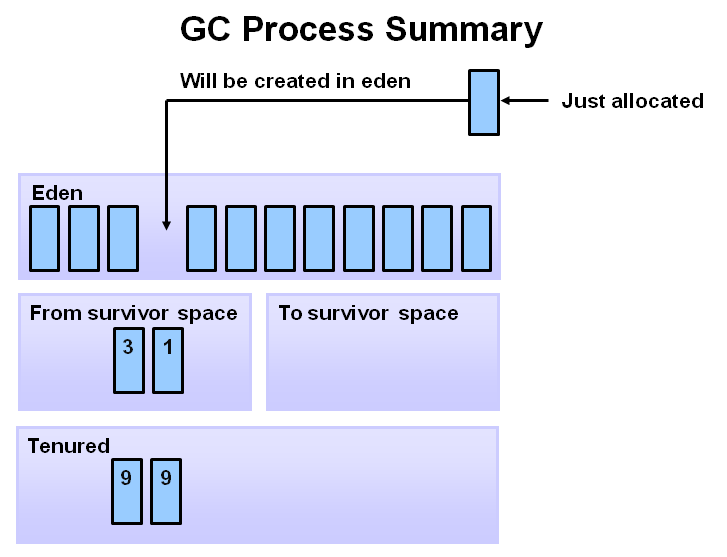 这里居然没有讲full GC,差评啊。
这里居然没有讲full GC,差评啊。
增量垃圾收集器
标记、重新标记
G1之前垃圾收集需要考虑的问题
- 老年代垃圾收集器的大部分操作都必须扫描整个老年代空间,比如标记、清除以及压缩。这意味着执行工作的时间将随着Java堆空间的变化而线性的增加或减少。
- 年轻代和老年代是独立的连续内存块,所以要先决定年轻代和老年代存放在虚拟地址空间的位置。
垃圾收集常见的动作
标记、清除、压缩、复制
压缩(Compact)
在对老年代进行回收的同时还会进行压缩动作。压缩可以将邻近的对象移动到一起,消除它们之间被浪费的空间,形成一个理想的布局。然而,压缩花费的时间可能非常长,这通常和Java堆的大小以及老年代中存活的对象的数量和大小有关。
如下图,就是一个典型的带压缩的垃圾收集器:

图 带压缩的垃圾收集器
看吧,我没说错吧~~~
好了,不开玩笑了,下面这个描述的是对Java内存进行压缩

图 压缩过程示意
上图中,第二个步骤是清除不再使用的对象,也就是sweep,有扫的意思;第三步则是对一块内存进行压缩的过程。
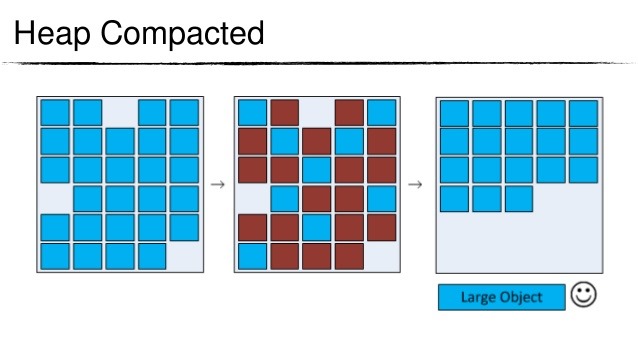
图 Java堆的压缩
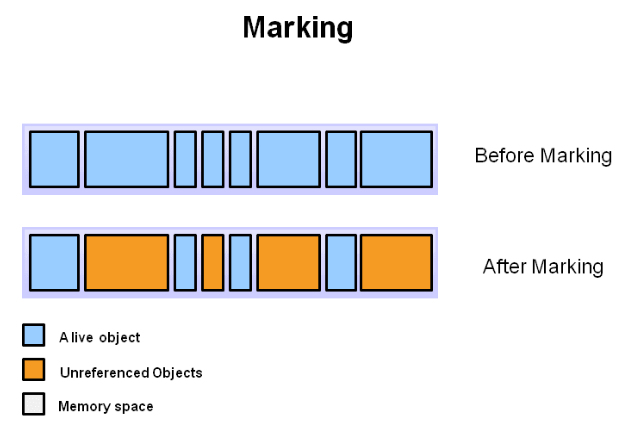
标记(Mark)




复制(Copy)
Java堆中的对象经历着从Eden ---> Survivor ---> Tenured这三个内存空间的进化。
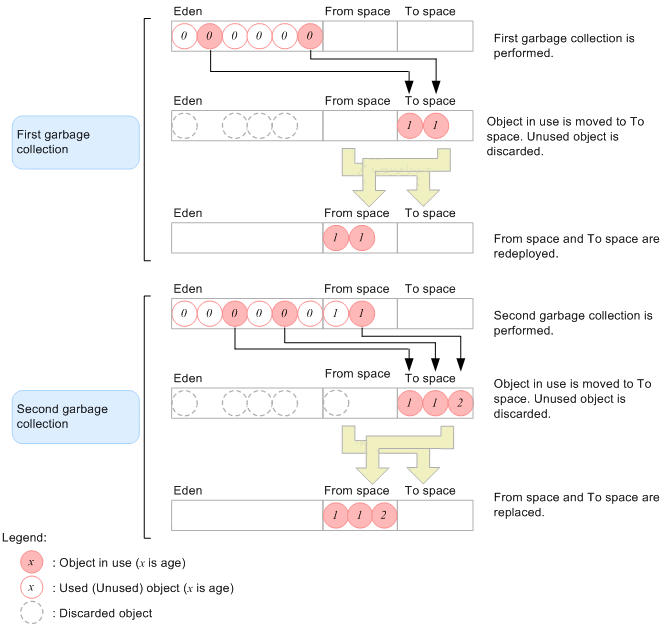
清除(SWEEP)

并行的多级并发标记、清除阶段
HotSpot堆布局方式、各代相邻
分区、巨型分区、空闲分区、空闲分区列表
回退暂停Full GC
垃圾收集遇到转移失败时候的安全保护机制
转移失败、担保失败
引用的自转发
混合GC
GC效率定义
收集集合
本地分配缓冲区(TLAB),TLAB分配为啥会快一些?
暂停时间
最新文章
- magnetom模板制作
- bootstrap API地址
- ecshop 多语言切换
- C++:基类和派生类
- JAVADOC 常见使用方法 帮助文档
- UberX及以上级别车奖励政策(优步北京第四组)
- extjs4 分页工具栏pagingtoolbar的每页显示数据combobox下拉框
- 【完全背包】HDU 1284 钱币兑换问题
- SSH整合缓存之-Memcached作为hibernate的二级缓存
- DL4NLP——词表示模型(二)基于神经网络的模型:NPLM;word2vec(CBOW/Skip-gram)
- OKCoin期货现货API[Python3版]
- 异常-----freemarker.template.TemplateException: Expected collection or sequence. datas evaluated instead to freemarker.core.HashLiteral$SequenceHash on line 7, column 18 in inc/select.ftl.
- Xaml Controls Gallery 的五个没有用的控件
- day03 数据类型与运算符
- Python学习之旅(二十)
- pop
- UML中类结构图示例
- ActiveReports 报表应用教程 (12)---交互式报表之贯穿钻取
- BZOJ3879:SvT(后缀数组,单调栈,ST表)
- ASP.NET MVC3-第02节-添加一个Controller (C#)