为IEnumerable<T>添加RemoveAll<IEnumerable<T>>扩展方法--高性能篇
最近写代码,遇到一个问题,微软基于List<T>自带的方法是public bool Remove(T item);,可是有时候我们可能会用到诸如RemoveAll<IEnumerable<T>>的方法,坦白的说,就是传入的参数是一个IEnumerable<T>,而不是一个T,这种情景是随时可能用到的。当然我们会轻易的发现List<T>里本身就封装了一个方法public int RemoveAll(Predicate<T> match),但是后面我们的测试性能上来说,真不敢恭维。被逼无耐,只能想办法封装一个IEnumerable<T>扩展方法。可是此时不要忘了写这篇文章的宗旨,封装的目的,就是‘性能’必须要好!
下面我们一步一步讲讲我遇到的经历分享给大家。
假设如下的数据:
1.Source IEnumerable Items:A B C D A E F G H
2.Remove IEnumerable Items:A B C D A E
3.Result IEnumerable Items:F G H
第1行是原有的IEnumerable数据
第2行是要删除(remove)的数据
第3行是最终删除结果的数据
从上面数据,我们分析下如何高效的得到第3行数据呢?记得,一定要‘高效’,失去高效的方法,我认为不是本节讨论的内容,因为没有任何意义,当然,高效是相对的,不是说,今天讲的方法是最高效的,起码很高效,恩~ 请不要骂我,确实是费话!
没错,很多程序员想必和我一样,大多数会这样做
for (int index = ; index < source.Count; index++)
{
var item = source.ElementAt(i);
if (remove.Contains(item))
{
source.Remove(item);
}
}
好吧,这样做,目的是达到了,但是,接下来的测试,让人纠心。
我们来摸拟下数据
新建一个Source IEnumerable 随机产生10万条数据 和Remove IEnumerable 随机产生1万条数据
List<string> source = new List<string>();
List<string> remove = new List<string>(); int i = ;
Random rad = new Random(); while (i < )
{
source.Add(rad.Next(Int32.MaxValue).ToString());
i++;
} i = ; while (i < )
{
remove.Add(rad.Next(Int32.MaxValue).ToString());
i++;
} DateTime now = DateTime.Now;
for (int index = ; index < source.Count; index++)
{
var item = source.ElementAt(i);
if (remove.Contains(item))
{
source.Remove(item);
}
} Console.WriteLine("Remove Running time:" + (DateTime.Now - now).TotalSeconds);
Console.ReadKey();
上述代码消耗的时间是 Remove Running time:16.6678431s
所以遇到这种情况,测试结果表明,消耗的时候太长,我们根本等不起,何况放在程序里就是一个炸弹。
当然,我们摸拟的数据可能太过于庞大,但不得不承一个从客观事实,这个方法效率不是太好!
上面我们讨论过 IEnumerable<T>.RemoveAll<IEnumerable<T>>(IEnumerable<T> Items)方法
费话不多说,直接上来测试下,看看如何。
代码如下:很简单,仅需一行:
List<string> source = new List<string>();
List<string> remove = new List<string>(); int i = ;
Random rad = new Random(); while (i < )
{
source.Add(rad.Next(Int32.MaxValue).ToString());
i++;
} i = ; while (i < )
{
remove.Add(rad.Next(Int32.MaxValue).ToString());
i++;
} DateTime now = DateTime.Now;
source.RemoveAll(m => remove.Contains(m));
Console.WriteLine("RemoveAll Running time:" + (DateTime.Now - now).TotalSeconds);
测试结果所消耗时间是 RemoveAll Running time:16.1175443s
和第一种方法对比,消耗的时间并没有太大提高,几乎一致,唉,真是让人失望。
这个时候,我们来看看linq to object 看看。
DateTime now = DateTime.Now;
/**注册这里ToList()主要是让查询真正的执行,不然,只是生成语句
var r = (from item in source
where !remove.Contains(item)
select item).ToList();
**/
var r = source.Where(item => !remove.Contains(item)).ToList();
Console.WriteLine("RemoveAll Running time:" + (DateTime.Now - now).TotalSeconds);
Console.ReadKey();
测试结果所消耗时间是 RemoveAll Running time:16.1112403s
其实我们仔细的分析下代码 m => remove.Contains(m) 本来还是一种遍历,外层又一层遍历。再回来过看看Linq To Object 实际上也是变相的双层遍历
从时间消耗来说,三种方法时间消耗几乎一致 O(M*N);
到此为至,我们并没有找到真正的高效的方法。‘办法’嘛,总是想靠人想的,不能说,就这样算了吧?
仔仔想想,List<T> 在遍历上,是很慢的,而采用诸如字典Dictionary<T> 查找某个键(Key)值(Value),性能是非常高效的,因为它是基于'索引'(下面会详细的说明)的,理论上讲在时间消耗是O(1)。即然这样,我们回过头来再看看我们的例子
1.Source IEnumerable Items:A B C D A E F G H
2.Remove IEnumerable Items:A B C D A E
3.Result IEnumerable Items:F G H
众所周知,字典Key 是唯一的,如果我们把Remove IEnumverable Items 放入字典Dictionary<Remove Items>里,用一个Foreach遍历所用项,在时间上理论上应该是O(N),然后再对Source IEnumberable Items遍历对比Dictionary<Remove Items>IEnumverable Items ,如果两者是相同的项那么continue for遍历,否则,把遍历到的Source IEnumberable Items 项存入一个数组里,那么这个数组里,即是我们需要的Result IEnumberable items结果项了。这个方式有点像‘装脑袋’。哈哈~,不要高兴的太早,由于Remove IEnumverable Items 是允许有重复的项,那么放在字典里,不是有点扯了吗?不用怕,看来,我们直接玩字典得换个方式,把字典的Key放入 Remove Item,把Value存入一个计数器值作为标计,以此如果存在多项重复的重置value=1,不重复出现的项直接赋值1。仔仔想想,方法可行。

上面是一个示意图,A B C D E 作为Key 其中Value值匀为1。
我们看到,A重复了两次,那么在字典里value 标计匀重置为1,B出现了一次,标计为1,这样做不是多此一举吗?
要知道字典是通过Key寻找键值的,速度远远超过foreach 遍历List强的多。
好了,我们按照上面的思路写出方法:
public static IEnumerable<T> RemoveAll<T>(this IEnumerable<T> source, IEnumerable<T> items)
{
var removingItemsDictionary = new Dictionary<T, int>();
var _count = source.Count();
T[] _items = new T[_count];
int j = ;
foreach (var item in items)
{
if (!removingItemsDictionary.ContainsKey(item))
{
removingItemsDictionary[item] = ;
}
}
for (var i = ; i < _count; i++)
{
var current = source.ElementAt(i);
if (!removingItemsDictionary.ContainsKey(current))
{
_items[j++] = current;
}
}
return _items;
}
方法很简单吧,其实我们主要想利用字典的Key 快速匹配,至于值就没那么重要了。
字典的索引时间上是O(1),遍历source时间是O(M) 总计时间理论上应该上O(M+N)而不是O(M*N)。
上面的代码,我们为了让调用方便,故去扩展IEnumerable<T>,下面我们来测试下看看时间有没有提高多少?
IEnumerable<string> dd = source.RemoveAll(remove);
这次,哈哈,既然仅仅只用了0.016001...s,上面几个例子用了16s 相差太大了,足足提高了1000倍之多,果然采用字典方式,性能上来了,这样的代码,放在项目才具有实际意义!
其实仔细分析上面代码还是有问题的
T[] _items = new T[_count]; //这里只是粗略的一次性定义了一个_count大小的数组,这样的数据远远超出真正使用的数组
通过上面的分析,产生了很多项NULL的多余项,如果要是能够自动扩展大小,那就更好不过了。
这个时候,想起了链表形式的东西。
为了在进更一步的提高下性能,众所周知,hashcode为标志一个数据的'指标',如果我们能够判断hashcode是否相等,也许可以提高一点性能,如果看到字典的源码,很多人会很快想起,是如何构造了一个类似Set<T>的'数据组'。
试想下,如果我们现在有一个‘特殊字典’,特殊在,我们添加相同的key的时候,返回的是false,而只有不重复的项才可以成功的添加进来,这样我们所得的‘数组’就是我们想要的。
可能我说的有点抽像,就像下面这样
public static IEnumerable<TSource> Iterator<TSource>(this IEnumerable<TSource> first, IEnumerable<TSource> second, IEqualityComparer<TSource> comparer)
{
Set<TSource> iteratorVariable = new Set<TSource>(comparer);
foreach (TSource local in second)
{
iteratorVariable.Add(local);
}
foreach (TSource iteratorVariable1 in first)
{
if (!iteratorVariable.Add(iteratorVariable1))//这儿是过滤性添加,如果添加失败,说明此项已添加 return false
{
continue;
}
yield return iteratorVariable1;//yield语句为我们有机会创造枚举数组
}
}
其中yield iteratorVariable1 产生的即是我们想要的‘数组’,这里只所以那么强悍,归功于Set<TSource>
我先把所有的代码贴出来,然后一点一点的讲解,不至于片面的头晕
Set<T>构造器:Slots
internal class Set<TElement>
{ private IEqualityComparer<TElement> comparer;
private int count;
private int freeList;
private Slot<TElement>[] slots;
private int[] buckets; public Set()
: this(null)
{ } public Set(IEqualityComparer<TElement> comparer)
{
if (comparer == null)
{
comparer = EqualityComparer<TElement>.Default;
}
this.comparer = comparer;
this.slots = new Slot<TElement>[];
this.buckets = new int[];
this.freeList = -;
} private bool Find(TElement value, bool add)
{
int hashCode = this.InternalGetHashCode(value);
for (int i = this.buckets[hashCode % this.buckets.Length] - ; i >= ; i = this.slots[i].next)
{
if ((this.slots[i].hashCode == hashCode) && this.comparer.Equals(this.slots[i].value, value))
{
return true;
}
}
if (add)
{
int freeList;
if (this.freeList >= )
{
freeList = this.freeList;
this.freeList = this.slots[freeList].next;
}
else
{
if (this.count == this.slots.Length)
{
this.Resize();
}
freeList = this.count;
this.count++;
}
int index = hashCode % this.buckets.Length;
this.slots[freeList].hashCode = hashCode;
this.slots[freeList].value = value;
this.slots[freeList].next = this.buckets[index] - ;
this.buckets[index] = freeList + ;
}
return false;
} private void Resize()
{
int num = (this.count * ) + ;
int[] numArray = new int[num];
Slot<TElement>[] destinationArray = new Slot<TElement>[num];
Array.Copy(this.slots, , destinationArray, , this.count);
for (int i = ; i < this.count; i++)
{
int index = destinationArray[i].hashCode % num;
destinationArray[i].next = numArray[index] - ;
numArray[index] = i + ;
}
this.buckets = numArray;
this.slots = destinationArray;
} public bool Add(TElement value)
{
return !this.Find(value, true);
} internal int InternalGetHashCode(TElement value)
{
if (value != null)
{
return (this.comparer.GetHashCode(value));
}
return ;
}
} internal struct Slot<TElement>
{
internal int hashCode;
internal TElement value;
internal int next;
}
当数组不够时进行扩容(在当前的基础上*2的最小质数(+1)),然后进行重新hashcode碰撞形成链表关系:
private void Resize()
{
int num = (this.count * ) + ;
int[] numArray = new int[num];
Slot<TElement>[] destinationArray = new Slot<TElement>[num];
Array.Copy(this.slots, , destinationArray, , this.count);
for (int i = ; i < this.count; i++)
{
int index = destinationArray[i].hashCode % num;
destinationArray[i].next = numArray[index] - ;
numArray[index] = i + ;
}
this.buckets = numArray;
this.slots = destinationArray;
}
估计看到上面的代码,能晕倒一大片,哈哈~晕倒我不负责哦。
下面我们来分析一些原理,然后再回过头看上面的代码,就很清淅了,必竟写代码是建立在一种思想基础上而来的嘛!
public Set(IEqualityComparer<TElement> comparer)
{
if (comparer == null)
{
comparer = EqualityComparer<TElement>.Default;
}
this.comparer = comparer;
this.slots = new Slot<TElement>[];
this.buckets = new int[];
this.freeList = -;
}
我们看到,Dictionary在构造的时候做了以下几件事:
- 初始化一个this.buckets = new int[7]
- 初始化一个this.slots= new slots<T>[7]
- count=0和freeList=-1
- comparer = EqualityComparer<TElement>.Default 作为比较两个T是否相等的比较器
首先,我们构造一个:
Set<TSource> iteratorVariable = new Set<TSource>(NULL);

添加项时候的变化
Add(4,”4″)后:
根据Hash算法: 4.GetHashCode()%7= 4,因此碰撞到buckets中下标为4的槽上,此时由于Count为0,因此元素放在slots中第0个元素上,添加后Count变为1

Add(11,”11″)
根据Hash算法 11.GetHashCode()%7=4,因此再次碰撞到Buckets中下标为4的槽上,由于此槽上的值已经不为-1,此时Count=1,因此把这个新加的元素放到slots中下标为1的数组中,并且让Buckets槽指向下标为1的slots中,下标为1的slots之下下标为0的slots。

Add(18,”18″)
我们添加18,让HashCode再次碰撞到Buckets中下标为4的槽上,这个时候新元素添加到count+1的位置,并且Bucket槽指向新元素,新元素的Next指向slots中下标为1的元素。此时你会发现所有hashcode相同的元素都形成了一个链表,如果元素碰撞次数越多,链表越长。所花费的时间也相对较多。

Add(19,”19″)
再次添加元素19,此时Hash碰撞到另外一个槽上,但是元素仍然添加到count+1的位置。
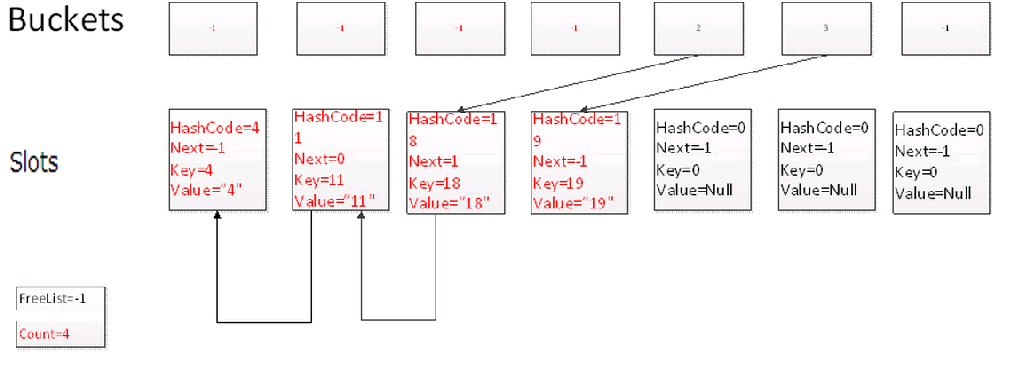
删除项时的变化:
Remove(4)
我们删除元素时,通过一次碰撞,并且沿着链表寻找3次,找到key为4的元素所在的位置,删除当前元素。并且把FreeList的位置指向当前删除元素的位置
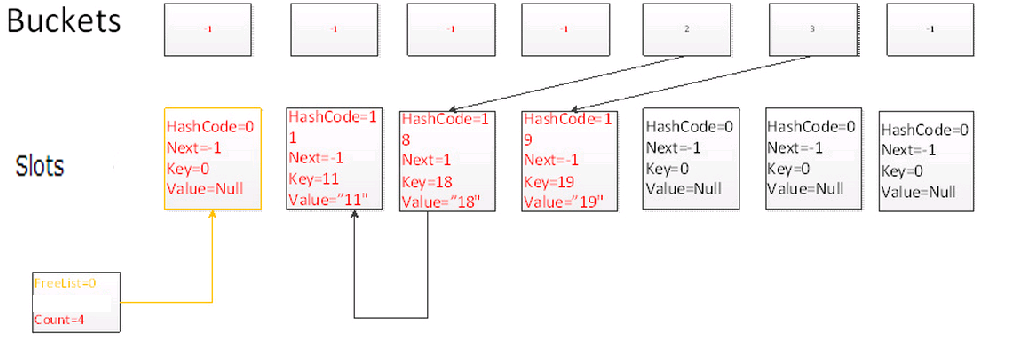
Remove(18)
删除Key为18的元素,仍然通过一次碰撞,并且沿着链表寻找2次,找到当前元素,删除当前元素,并且让FreeList指向当前元素,当前元素的Next指向上一个FreeList元素。
此时你会发现FreeList指向了一个链表,链表里面不包含任何元素,FreeCount表示不包含元素的链表的长度。
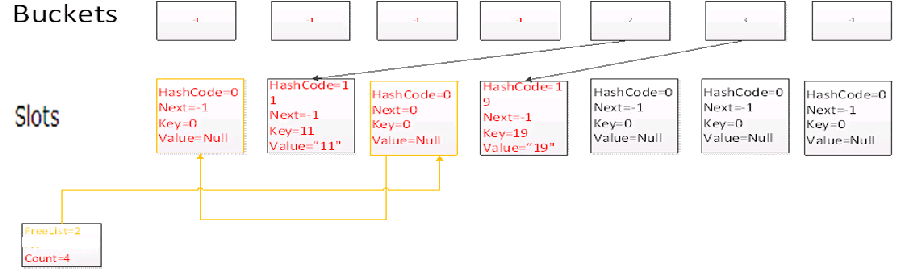
Add(20,”20″)
再添加一个元素,此时由于FreeList链表不为空,因此字典会优先添加到FreeList链表所指向的位置,添加后,FreeList链表长度变为1

部分图片参考自互联网,哈哈,然后重画,写文章真心不容易,太耗时间,此时四个小时已过去。
通过以上,我们可以发现Set<T>在添加,删除元素按照如下方法进行:
- 通过Hash算法来碰撞到指定的Bucket上,碰撞到同一个Bucket槽上所有数据形成一个单链表
- 默认情况slots槽中的数据按照添加顺序排列
- 删除的数据会形成一个FreeList的链表,添加数据的时候,优先向FreeList链表中添加数据,FreeList为空则按照count依次排列
- 字典查询及其的效率取决于碰撞的次数,这也解释了为什么Set<T>的查找会很快。
简单来说就是其内部有两个数组:buckets数组和slots数组,slots有一个next用来模拟链表,该字段存储一个int值,指向下一个存储地址(实际就是bukets数组的索引),当没有发生碰撞时,该字段为-1,发生了碰撞则存储一个int值,该值指向bukets数组.
一,实例化一个Set<string> iteratorVariable = new Set<string>(null);
a,调用Set默认无参构造函数。
b,初始化Set<T>内部数组容器:buckets int[]和slots<TElement>[],分别分配长度7;
二,向Set<T>添加一个值,Set.add("a","abc");
a,计算"a"的哈希值,
b,然后与bucket数组长度(7)进行取模计算,假如结果为:2
c,因为a是第一次写入,则自动将a的值赋值到slots[0]的key,同理将"abc"赋值给slots[0].value,将上面b步骤的哈希值赋值给slots[0].hashCode,
slots[0].next 赋值为-1,hashCode赋值b步骤计算出来的哈希值。
d,在bucket[2]存储0。
三,通过key获取对应的value, var v=Set["a"];
a, 先计算"a"的哈希值,假如结果为2,
b,根据上一步骤结果,找到buckets数组索引为2上的值,假如该值为0.
c, 找到到slots数组上索引为0的key,
1),如果该key值和输入的的“a”字符相同,则对应的value值就是需要查找的值。
2) ,如果该key值和输入的"a"字符不相同,说明发生了碰撞,这时获取对应的next值,根据next值定位buckets数组(buckets[next]),然后获取对应buckets上存储的值在定位到slots数组上,......,一直到找到为止。
3),如果该key值和输入的"a"字符不相同并且对应的next值为-1,则说明Set<T>不包含字符“a”。
至此,我们再回过头来,看看代码,我想不攻自破!不明白的请多多想想,不要老问!
再次测试下看下结果(这些方法我用扩展方法,没事的朋友可以自已写下,代码在上面已经贴出,这里主要看的比较直观些)
DateTime now = DateTime.Now;
Set<string> iteratorVariable = new Set<string>(null);
foreach (var local in remove)
{
iteratorVariable.Add(local);
}
foreach (var local in source)
{
if (!iteratorVariable.Add(local))
{
continue;
}
}
Console.WriteLine("Running time:" + (DateTime.Now - now).TotalSeconds);
Console.ReadKey();
想来想去,还是把它改成扩张方法吧,不然有人会问我,如何改?
var r = source.Iterator(remove, null);
仅仅还是一句话,实现了上述等同的方法!
所消耗时间Running time:0.0112076..s
看到没,与上面的例子性能上相差不大。但是也远远超过了前面三个例子。而且也是自动扩容的,引入了hashcode碰撞,这是一种思想,很多.net字典也是基于这种原理实现的。没事的同学可以看看.net 相关源码。
最后我想说的一件事,在个方法其它等同于Except<IEnumerable<T>>(),在Linq .net 3.5+微软已经给我们实现。
请不要骂我,刚开始我也不知道这个方法,写着写着想起来了。微软的进步,正悄悄的把我们省了很多事。然后,依据微软的方法进行改进而来。
到这里,不知不觉的你已经学会了一种‘算法’。即使微软提供了我们现成的方法,也不足为奇!必竟思想的提练是我们最终的目标!
参考资料
1. MSDN, IEquatable<T>, http://msdn.microsoft.com/en-us/library/ms131187.aspx;
2. MSDN IEqualityComparer, http://msdn.microsoft.com/en-us/library/ms132151.aspx;
3.MSDN IEqualityComparer,https://msdn.microsoft.com/en-us/library/ms132072(v=vs.110).aspx
4.Enumerable.Except<TSource> Method(IEnumerable<TSource>, IEnumerable<TSource>),https://msdn.microsoft.com/en-us/library/bb300779(v=vs.110).aspx
出处:http://www.cnblogs.com/laogu2/ 欢迎转载,但任何转载必须保留完整文章,在显要地方显示署名以及原文链接。如您有任何疑问或者授权方面的协商,请给我留言。
最新文章
- Atitit.eclipse 4.3 4.4  4.5 4.6新特性
- NOIP2009解题报告
- oracle线程数更改
- 【C语言探索之旅】 开宗明义及第一课:什么是编程?
- CSS控制文本在一行内显示,若有多余字符则使用省略号表示
- 微端游戏启动器LAUNCHER的制作之MFC版一(序和进程通信)
- ubuntu 笔记
- 基于MySQL + Node.js + Leaflet的离线地图展示,支持百度、谷歌、高德、腾讯地图
- 2017-07-20聊聊《C#本质论》
- phpstorm设置背景图片
- VMware设置桥接上网
- jquery的ajax()函数中文传值出现乱码完美解决方案
- 快速学会在JSP中使用EL表达式
- AJAX-XMLHttpRequest和本地文件
- Python全栈开发之21、django
- jQuery layer弹出层插件 http://layer.layui.com/直接上官网学
- mfc 鼠标、键盘响应事件
- javascript:;与javascript:void(0)
- [Leetcode] subsets ii 求数组所有的子集
- [CF773D]Perishable Roads
热门文章
- 前端开发中SEO的十二条总结
- 页面嵌入dom与被嵌入iframe的攻防
- Objective-C三种定时器CADisplayLink / NSTimer / GCD的使用
- HTML 事件(三) 事件流与事件委托
- HTML5 input元素新的特性
- 隐马尔科夫模型python实现简单拼音输入法
- 实现一个类 RequireJS 的模块加载器 (二)
- spring源码分析之<context:property-placeholder/>和<property-override/>
- 消息队列性能对比——ActiveMQ、RabbitMQ与ZeroMQ(译文)
- Cesium简介以及离线部署运行