SQL疑难杂症【4 】大量数据查询的时候避免子查询
2024-09-01 14:13:28
前几天发现系统变得很慢,在Profiler里面发现有的SQL执行了几十秒才返回结果,当时的SQL如下:

可以看得出来,在652行用了子查询,恰巧目标表(QS_WIP)中的记录数为100000000+,通过如下SQL可以得到:
SELECT ROWS FROM SYSINDEXES WHERE ID=OBJECT_ID('QS_WIP') AND INDID <2
大量的数据导致子查询的效率非常慢,应用系统一度提示"time out",经过优化,改为如下写法,执行效率明显提升:
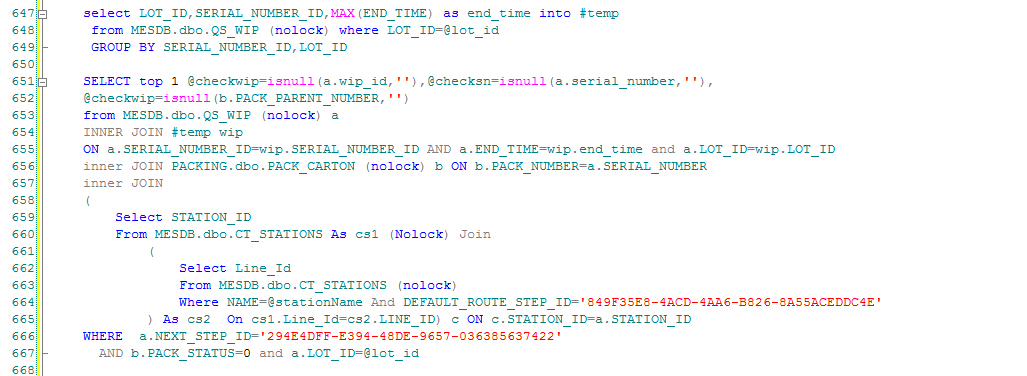
先将子查询里面的内容提取出来作为一个临时表,再次join的时候就快了。
最新文章
- Ubuntu环境变量(.profile)加载顺序
- ASP.NET MVC 解析模板生成静态页一(RazorEngine)
- Spring中bean的作用域scope详解
- Socket.io和Redis写Realtime App 之express初试
- MVC - 16.MVC过滤器
- ArcGIS删除部分数据后全图范围不正确
- Java学习-038-JavaWeb_007 -- JSP 动作标识 - plugin
- .NET中如何使用反序列化JSON字符串/序列化泛型对象toJsonStr
- Java泛型方法定义及泛型类型推断
- WPFS数据绑定(要是后台类对象的属性值发生改变,通知在“client界面与之绑定的控件值”也发生改变须要实现INotitypropertyChanged接口)
- DataFrame使用总结1(超实用)
- 关于extern的用法
- [HNOI2009]最小圈(分数规划+SPFA判负环)
- [OI]Noip 2018总结(普及)
- 014 链表中倒数第k个结点
- ArcGIS API for JS 测量线长(各折线段)
- CDN随笔
- python中get pass用法
- centos7安装python3和pip3
- 修改hadoop FileUtil.java,解决权限检查的问题