python RabbitMQ队列/redis
RabbitMQ队列
rabbitMQ是消息队列;想想之前的我们学过队列queue:threading queue(线程queue,多个线程之间进行数据交互)、进程queue(父进程与子进程进行交互或者同属于同一父进程下的多个子进程进行交互);如果两个独立的程序,那么之间是不能通过queue进行交互的,这时候我们就需要一个中间代理即rabbitMQ
消息队列:
- RabbitMQ
- ZeroMQ
- ActiveMQ
- ...........
一. 安装
1. ubuntu下安装rabbitMQ:
1.1 安装: sudo apt-get install rabbitmq-server
1.2 启动rabbitmq web服务:
sudo invoke-rc.d rabbitmq-server stop
sudo invoke-rc.d rabbitmq-server start
启动web管理:sudo rabbitmq-plugins enable rabbitmq_management
1.3 远程访问rabbitmq,自己增加一个用户,步骤如下:
- 创建一个admin用户:sudo rabbitmqctl add_user admin 123123
- 设置该用户为administrator角色:sudo rabbitmqctl set_user_tags admin administrator
- 设置权限:sudo rabbitmqctl set_permissions -p '/' admin '.' '.' '.'
- 重启rabbitmq服务:sudo service rabbitmq-server restart
之后就能用admin用户远程连接rabbitmq server了。
2. 安装python rabbitMQ modul:
- 管理员打开cmd,切换到python的安装路径,进入到Scripts目录下(如:C:\Users\Administrator\AppData\Local\Programs\Python\Python35\Scripts);
- 执行以下命令:pip install pika
- 校验是否安装成功:进入到python命令行模式,输入import pika,无报错代表成功;
二. 代码实现
1. 实现最简单的队列通信

produce
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters("192.168.244.130",15672))
channel = connection.channel()
#声明queue
channel.queue_declare(queue='hello')
channel.basic_publish(exchange="",
routing_key='hello',
body = 'Hello World!')
print("[x] Sent 'Hello World!")
connection.close()
consume
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters("192.168.16.23"))
channel = connection.channel()
channel.queue_declare(queue="holle",durable=True)
def callback(ch,method,properties,body):
print(ch,method,properties)
print("[x] Received %r" %body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue="holle",
no_ack=True)
print('[*] waiting for messages. to exit press ctrl+c')
channel.start_consuming()
2. RabbitMQ消息分发轮询
先启动消息生产者,然后再分别启动3个消费者,通过生产者多发送几条消息,你会发现,这几条消息会被依次分配到各个消费者身上
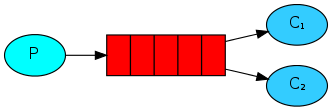
在这种模式下,RabbitMQ会默认把p发的消息公平的依次分发给各个消费者(c),跟负载均衡差不多
通过执行pubulish.py和consume.py可以实现上面的消息公平分发,那假如c1收到消息之后宕机了,会出现什么情况呢?rabbitMQ是如何处理的?现在我们模拟一下:
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel() #声明一个管道(管道内发消息)
channel.queue_declare(queue='cc') #声明queue队列
channel.basic_publish(exchange='',
routing_key='cc', #routing_key 就是queue名
body='Hello World!'
)
print("Sent 'Hello,World!'")
connection.close() #关闭
publish.py
publish
import pika,time
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.queue_declare(queue='cc')
def callback(ch,method,properties,body):
print("->>",ch,method,properties)
time.sleep(15) # 模拟处理时间
print("Received %r"%body)
channel.basic_consume(callback, #如果收到消息,就调用callback函数处理消息
queue="cc",
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收消息
consume.py
consume
在consume.py的callback函数里增加了time.sleep模拟函数处理,通过上面程序进行模拟发现,c1接收到消息后没有处理完突然宕机,消息就从队列上消失了,rabbitMQ把消息删除掉了;如果程序要求消息必须要处理完才能从队列里删除,那我们就需要对程序进行处理一下:
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel() #声明一个管道(管道内发消息)
channel.queue_declare(queue='cc') #声明queue队列
channel.basic_publish(exchange='',
routing_key='cc', #routing_key 就是queue名
body='Hello World!'
)
print("Sent 'Hello,World!'")
connection.close() #关闭
publish.py
publish
import pika,time
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.queue_declare(queue='cc')
def callback(ch,method,properties,body):
print("->>",ch,method,properties)
#time.sleep(15) # 模拟处理时间
print("Received %r"%body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback, #如果收到消息,就调用callback函数处理消息
queue="cc",
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收消息
consume.py
consume
通过把consume.py接收端里的no_ack=True去掉之后并在callback函数里面添加ch.basic_ack(delivery_tag = method.delivery_tag,就可以实现消息不被处理完不能在队列里清除。
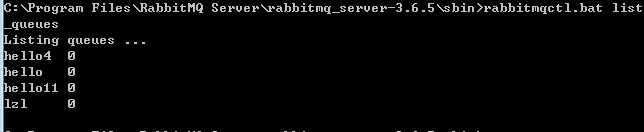
查看消息队列数:
3. 消息持久化
如果消息在传输过程中rabbitMQ服务器宕机了,会发现之前的消息队列就不存在了,这时我们就要用到消息持久化,消息持久化会让队列不随着服务器宕机而消失,会永久的保存下去
发送端:
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel() #声明一个管道(管道内发消息)
channel.queue_declare(queue='cc',durable=True) #队列持久化
channel.basic_publish(exchange='',
routing_key='cc', #routing_key 就是queue名
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode = 2 #消息持久化
)
)
print("Sent 'Hello,World!'")
connection.close() #关闭
发送端
import pika,time
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.queue_declare(queue='cc',durable=True)
def callback(ch,method,properties,body):
print("->>",ch,method,properties)
time.sleep(15) # 模拟处理时间
print("Received %r"%body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback, #如果收到消息,就调用callback函数处理消息
queue="cc",
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收消息
接收端
4. 消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了
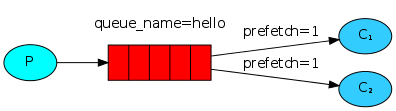
channel.basic_qos(prefetch_count=1)
带消息持久化+公平分发:
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel() #声明一个管道(管道内发消息)
channel.queue_declare(queue='cc',durable=True) #队列持久化
channel.basic_publish(exchange='',
routing_key='cc', #routing_key 就是queue名
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode = 2 #消息持久化
)
)
print("Sent 'Hello,World!'")
connection.close() #关闭
publish.py
publis
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel() #声明一个管道(管道内发消息)
channel.queue_declare(queue='cc',durable=True) #队列持久化
channel.basic_publish(exchange='',
routing_key='cc', #routing_key 就是queue名
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode = 2 #消息持久化
)
)
print("Sent 'Hello,World!'")
connection.close() #关闭
publish.py
consume
5. Publish\Subscribe(消息发布\订阅)
之前的例子都基本都是1对1的消息发送和接收,即消息只能发送到指定的queue里,但有些时候你想让你的消息被所有的Queue收到,类似广播的效果,这时候就要用到exchange了,
Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息:
- fanout: 所有bind到此exchange的queue都可以接收消息
- direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
- topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
- headers: 通过headers 来决定把消息发给哪些queue
5.1 fanout接收所有广播:
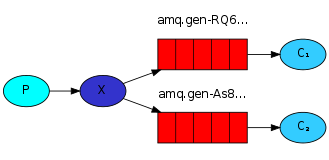
import pika
import sys credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) channel = connection.channel() channel.exchange_declare(exchange='logs',
type='fanout') message = "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='', #广播不用声明queue
body=message)
print(" [x] Sent %r" % message)
connection.close() publish.py
publish
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,
# exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue
channel.queue_bind(exchange='logs', # 绑定转发器,收转发器上面的数据
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
consume.py
consume
5.3 更细致的消息过滤 topic:

import pika
import sys credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) channel = connection.channel() channel.exchange_declare(exchange='topic_logs',
type='topic') routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close() publish.py publish.py
publish
import pika
import sys credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) channel = connection.channel() channel.exchange_declare(exchange='topic_logs',
type='topic') result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1) for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming() consume.py
sonsume
5.4 RPC(Remote procedure call )双向通信:
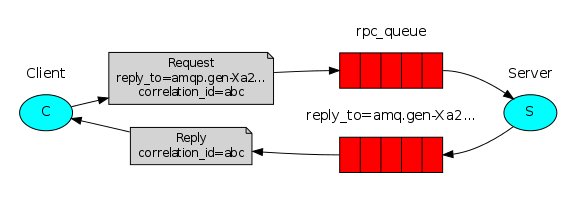
import pika
import time credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2) def on_request(ch, method, props, body):
n = int(body) print(" [.] fib(%s)" % n)
response = fib(n) ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests")
channel.start_consuming() rpc server
rpc_server
import pika
import uuid class FibonacciRpcClient(object):
def __init__(self):
credentials = pika.PlainCredentials('admin', '')
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue) def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response) fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response) rpc client
rpc_client
Redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
一、Redis安装和基本使用
|
1
2
3
4
|
wget http://download.redis.io/releases/redis-3.0.6.tar.gztar xzf redis-3.0.6.tar.gzcd redis-3.0.6make |
启动服务端
|
1
|
src/redis-server |
启动客户端
|
1
2
3
4
5
|
src/redis-cliredis> set foo barOKredis> get foo"bar" |
二、Python操作Redis
|
1
2
3
4
5
6
7
|
sudo pip install redisorsudo easy_install redisor源码安装详见:https://github.com/WoLpH/redis-py |
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
|
1
2
3
4
5
6
7
8
|
#!/usr/bin/env python# -*- coding:utf-8 -*-import redisr = redis.Redis(host='10.211.55.4', port=6379)r.set('foo', 'Bar')print r.get('foo') |
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
|
1
2
3
4
5
6
7
8
9
10
|
#!/usr/bin/env python# -*- coding:utf-8 -*-import redispool = redis.ConnectionPool(host='10.211.55.4', port=6379)r = redis.Redis(connection_pool=pool)r.set('foo', 'Bar')print r.get('foo') |
3、操作
String操作,redis中的String在在内存中按照一个name对应一个value来存储。如图:

set(name, value, ex=None, px=None, nx=False, xx=False)
set name alex
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name, value)
setnx aaa juck
设置值,只有name不存在时,执行设置操作(添加)
set(name, value, time)
set ccc ccc ex 30
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象
mset(*args, **kwargs)
批量设置值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
get(name)
获取值
mget(keys, *args)
批量获取
如:
mget('k','k2')
或
r.mget(['k', 'k2'])
getset(name, value)
getset k2 k2
设置新值并获取原来的值
最新文章
- SQL学习整理_1
- PHP简介
- ThinkPad L440 FN键设置
- 动态平衡二叉搜索树的简易实现,Treap 树
- 在CentOS上安装SQLServer
- JS预解析
- MyBatis绑定错误[Invalid bound statement (not found)]
- aspcms中if判断语句的运用
- oracle的sql函数
- 关于学习汇编的一些规则的理解(div mul cf of)
- JS正则表达式验证账号、手机号、电话、邮箱、货币
- 找出二叉树中和为n的路径
- C# Using的用法
- React Native 系列(七) -- ListView
- python检查IP地址正确性
- C#设计模式之十九状态模式(State Pattern)【行为型】
- 阻止form空表单提交----JavaScript
- SyntaxHighlighter 代码高亮极简单配置
- 第26月第22天 iOS瘦身之armv7 armv7s arm64选用 iOS crash
- Linux命令第四篇