[MySQL FAQ]系列 — 为什么InnoDB表要建议用自增列做主键
2024-09-12 11:01:15
我们先了解下InnoDB引擎表的一些关键特征:
- InnoDB引擎表是基于B+树的索引组织表(IOT);
- 每个表都需要有一个聚集索引(clustered index);
- 所有的行记录都存储在B+树的叶子节点(leaf pages of the tree);
- 基于聚集索引的增、删、改、查的效率相对是最高的;
- 如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择其作为聚集索引;
- 如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引;
- 如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
综上总结,如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的,也就是下面这几种情况的存取效率最高:
- 使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致;
- 该表不指定自增列做主键,同时也没有可以被选为主键的唯一索引(上面的条件),这时候InnoDB会选择内置的ROWID作为主键,写入顺序和ROWID增长顺序一致;
- 除此以外,如果一个InnoDB表又没有显示主键,又有可以被选择为主键的唯一索引,但该唯一索引可能不是递增关系时(例如字符串、UUID、多字段联合唯一索引的情况),该表的存取效率就会比较差。
实际情况是如何呢?经过简单TPCC基准测试,修改为使用自增列作为主键与原始表结构分别进行TPCC测试,前者的TpmC结果比后者高9%倍,足见使用自增列做InnoDB表主键的明显好处,其他更多不同场景下使用自增列的性能提升可以自行对比测试下。
附图:
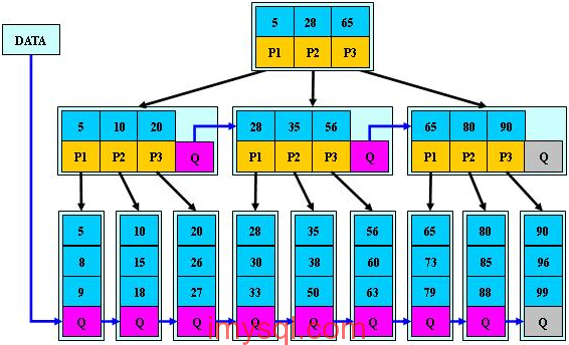
1、B+树典型结构
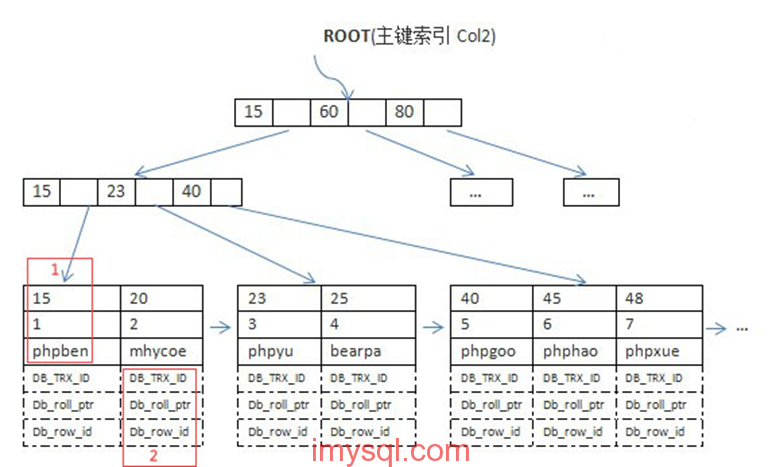
2、InnoDB主键逻辑结构
延伸阅读:
2、B+Tree index structures in InnoDB
3、B+Tree Indexes and InnoDB – Percona
4、MySQL官方手册: Clustered and Secondary Indexes
最新文章
- EQueue 2.0 性能测试报告
- python使用pdkdf2加盐密码
- a版本冲刺第五天
- android服务之录音功能
- python Flask :TypeError: 'dict' object is not callable
- 【原创】MYSQL++源码剖析——前言与目录
- ACM题目————STL练习之字符串替换
- 关于nodejs4.0 npm乱码以及离线全局安装时要注意的问题
- C++实现日期类(Date类)
- svn添加新文件自动忽略
- spring security maven dependency
- Openlayer3之绚丽的界面框架-Materialize
- SQLServer常用分页方式
- 未能加载文件或程序集“SuperMap.Data.dll”
- java之旅_高级教程_java泛型
- 针对SO交期回写的工厂日历功能调整
- Volley框架原理
- Python自动化开发 - 常用模块(二)
- 正则表达式,清除HTML标签,但要保留 <br>和<img>标签,其他的清除
- mybatis框架下使用generator插件自动生成domain/mapping/mapper
热门文章
- 最新版CocoaPods的使用与安装-以导入ReactiveCocoa框架为例
- C++ 异常机制分析
- BZOJ 1853: [Scoi2010]幸运数字
- 【BZOJ-2427】软件安装 Tarjan + 树形01背包
- 【BZOJ-3337】ORZJRY I 块状链表
- 何解決 LinqToExcel 發生「無法載入檔案或組件」問題何解決 LinqToExcel 發生「無法載入檔案或組件」問題
- 用WebBrowser采集渲染后的HTML页面
- 常用sql语句整理[SQL Server]
- LuaLaTeX \documemtclass{standalone} 编译错误
- CF 115B Lawnmower(贪心)