Spark之命令
Spark之命令
1.spark运行模式有4种:
a.local 多有用测试,
b. standalone:spark 集群模式,使用spark自己的调度方式。
c. Yarn: 对MapreduceV1升级的经典版本,支持spark。
d.Mesos:类似Yarn的资源调度框架,提供了有效的、跨分布式应用或框架的资源隔离和共享,可以运行hadoop、spark等框架
2.spark local 模式(shell )
Spark local模式(shell运行)
windows:
执行spark-shell.cmd Linux:
执行spark-shell 参数指定: • MASTER=local[4] ADD_JARS=code.jar ./spark-shell • MASTER=spark://host:port • 指定executor内存:export SPARK_MEM=25g
3. spark standalone 模式
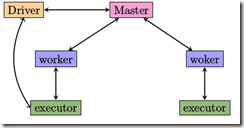
Spark standalone加载数据(shell运行spark-shell)
读取本地文件:
var file = sc.textFile("/root/test.txt").collect
加载远程hdfs文件:
var files = sc.textFile("hdfs://192.168.2.2:8020/user/superman").collect
(读取hdfs数据时使用的还是inputFormat)
standalone WordCount
sc.textFile("/root/test.txt").flatMap(_.split("\\t")).map(x=>(x,1)).reduceByKey(_+_).collect
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
Spark standalone保存结果集数据
保存数据到本地:
result.saveAsTextFile("/root/tmp") (tmp文件夹必须不存在)
保存数据到远程hdfs文件:
result.saveAsTextFile("hdfs://192.168.122.212:8020/user/superman/tmp")
(tmp文件夹必须不存在)
设置输出结果集文件数量:
result.repartition(1).saveAsTextFile
任务提交
spark-submit (推荐)
其它也可⾏,如sbt run, java -jar 等等
提交:spark on standalone spark-submit --class SsdTest /zzy/original-spark2-1.0-SNAPSHOT.jar hdfs://hadoop13:9000/hello hdfs://hadoop13:9000/out1.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
Spark on YARN
需要配置hadoop_conf_dir,hadoop_home
任务提交:
(standalone)spark-submit --class SsdTest /zzy/original-spark2-1.0-SNAPSHOT.jar hdfs://hadoop13:9000/hello hdfs://hadoop13:9000/out1.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
命令格式:
spark –submit –class path.your.class --master yarn-cluster [options] <app jar> [app options] spark-submit --class you.jar /
--master yarn-cluster\
--driver-memory 4g\
--executor-memory 2g\
--executor -cores 1\
lib\spark-examples*.jar\
10提交:on yarn
spark-submit --class classname inputyour.jar input your.text outpath spark-submit --class SaprkOnYarn original-spark2-1.0-SNAPSHOT.jar /hello out2(hadop默认是/usr/root文件夹).csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
4.RDD,可恢复分布式数据集,弹性分布式数据集
5.spark 对比mapreduce优势的总结
spark具有所有优点,并不是依靠一个人或者是一个团队的力量,而是站在巨人的肩膀上
1.依靠scala强有力的函数式变成
2.actor通信模式,akka做底层架构
3.MR架构思想
4.数据共享快,省去了mapreduce的shuffle过程中至少三次存入磁盘所带来的额外开销
5.spark的DAG(执行过程首先省城一张有向无环图)做的好,越靠近编译器,就性能越好,优化也更好。
6.任务使用线程启动并执行,比mapreduce使用进程执行任务要有很大优势
7.delay scheduling ---延迟执行
6.Spark Streaming
流失系统的特点:
1.低延迟。
2.高性能
3.分布式
4.可扩展。伴随着业务的发展,我们的数据量、计算量可能会越来越大,所以系统是可扩展的。
5.容错。这是分布式系统中通用问题。一个节点挂了不能影响应用。
对比storm
1.同一套系统,安装spark之后就一切都有了
2.spark 较强的容错能力,storm 使用较广,更稳定
3.storm是用Clojure语言去写的,它的很多扩展都是用java去写的
4.任务执行方面和storm 的区别是:
i.spark streaming 数据进来是一小段时间的RDD,数据进来之后切成一小块一小块进行处理
ii.storms是基于record形式来的,进来的是一个tuple,一条进来就处理一下
5.中间过程实质上就是spark引擎,只不过sparkstreaming 在spark之后引擎之上动了一点手脚:对进入spark引擎之前的数据进行了一个封装,方便进行基于时间片的小批量作业,交给spark 进行计算。
最新文章
- 强大的支持多文件上传的jQuery文件上传插件Uploadify
- LinckedhashMap原理
- MyElipes遇到 source not found解决方案(查看.class文件源码一劳永逸的解决方法)
- OpenStack 企业私有云的若干需求(7):电信行业解决方案 NFV
- Angular JS学习之表达式
- WINDONWS7+VS2012+Cocos2d-x
- JavaScript ---属性
- 用SQL server导出到oracle,查询时提示“表或视图不存在ORA-00942”错误
- File和URL的getPath()方法区别
- 【LeetCode】66 & 67- Plus One & Add Binary
- Lucene学习笔记: 四,Lucene索引过程分析
- USACO3.23Spinning Wheels
- linux运维安全工具集合[持续更新中..]
- delphi NativeXml的中文支持 乱码
- 使用HTML5/CSS3制作便签贴
- php遍历目录输出目录及其下的所有图片文件
- onekey_fourLED
- 判断手机电脑微信 js
- swap与dd命令使用详解
- leetcode算法:Distribute Candies