2019-03-14 Python爬虫问题 爬取网页的汉字打印出来乱码
2024-09-04 14:48:19
html = requests.get(YieldCurveUrl, headers=headers)
html=html.content.decode('UTF-8')
# print(html)
soup = BeautifulSoup(html, 'lxml')
之前是这样的
html = requests.get(YieldCurveUrl, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
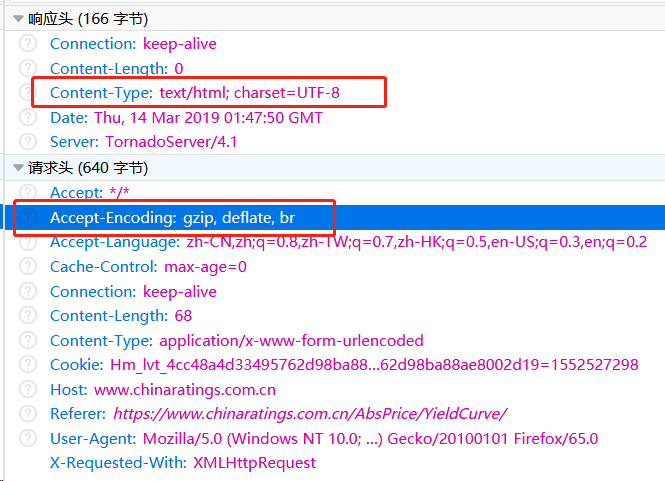
出现乱码,一般是两种原因,charset使用了geb2312的编码方式,而非utf-8
这里用的是utf-8,所以问题出在使用了gzip的压缩方式
最新文章
- slave IO流程之二:注册slave请求和dump请求
- Hive 实战(1)--hive数据导入/导出基础
- 使用Gradle运行集成测试
- NGUI 基础知识
- Ubuntu 12.04 DNS服务器的配置方法
- Struts2(二)---将页面表单中的数据提交给Action
- eclipse启动无响应,停留在Loading workbench状态
- Spring-MongoDB简单操作
- display:inline-block的空白bug问题
- HDOJ 3547 DIY Cube 解题报告
- Mac OS X Yosemite 10.10 配置 Apache+PHP 教程注意事项
- HashMap与HashTable联系与区别
- WIN7下制作的ubunbu U盘安装无法使用
- WPF Canvas小例子
- 关于js对象值的传递
- ICC_lab总结——ICC_lab6:版图完成
- CentOS安装Nginx 报错“configure: error: the HTTP rewrite module requires the PCRE library”解决办法
- 解决:mysql is blocked because of many connection errors;
- 优化表单数据的JS校验
- [BZOJ2654] tree (kruskal & 二分答案)