3.19 YARN HA架构及(RM/NM) Restart讲解
一、ResourceManager HA
ResourceManager(RM)负责跟踪集群中的资源,以及调度应用程序(例如,MapReduce作业)。
在Hadoop 2.4之前,ResourceManager是YARN集群中的单点故障。
高可用性功能以Active / Standby ResourceManager对的形式添加冗余,以消除此单点故障。
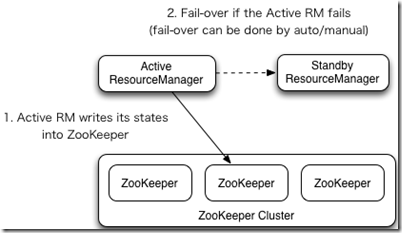
RM故障转移:
ResourceManager HA通过主动/备用架构实现 - 在任何时间点,其中一个RM处于活动状态,并且一个或多个RM处于待机模式,
等待活动发生任何事情时接管。转换为活动的触发器来自管理员(通过CLI)或启用自动故障转移时的集成故障转移控制器。
手动转换和故障转移:
如果未启用自动故障转移,则管理员必须手动将其中一个RM转换为活动。要从一个RM故障转移到另一个RM,
它们应首先将Active-RM转换为待机状态,并将Standby-RM转换为Active。所有这些都可以使用“ yarn rmadmin ”CLI完成。
自动故障转移:
RM可以选择嵌入基于Zookeeper的ActiveStandbyElector来决定哪个RM应该是Active。当Active关闭或无响应时,另一个RM自动被选为Active,然后接管。
请注意,不需要像HDFS那样运行单独的ZKFC守护程序,因为嵌入在RM中的ActiveStandbyElector充当故障检测器和领导者选择器而不是单独的ZKFC守护程序。
二、ResourceManagerRestart
以下为在官方文档中的内容:
1、概述
ResourceManager是管理资源和调度在YARN上运行的应用程序的中央权限。因此,它可能是Apache YARN集群中的单点故障。
`本文档概述了ResourceManager Restart,这是一项增强ResourceManager以在重新启动时保持正常运行的功能,并且还使ResourceManager的停机时间对最终用户不可见。
ResourceManager Restart功能分为两个阶段:
ResourceManager重新启动阶段1(非工作保留RM重新启动):增强RM以在可插拔状态存储中保留应用程序/尝试状态和其他凭据信息。
RM将在重新启动时从状态存储重新加载此信息,并重新启动以前运行的应用程序。用户无需重新提交申请。
ResourceManager重启阶段2(工作保留RM重启):重新构建ResourceManager的运行状态,重新组合NodeManagers的容器状态和ApplicationMasters的容器请求。
与第1阶段的主要区别在于,RM重启后,以前运行的应用程序不会被终止,因此应用程序不会因RM中断而丢失其工作。
2、特征
阶段1:非工作保留RM重启
从Hadoop 2.4.0版本开始,仅实现ResourceManager Restart Phase 1,如下所述。
总体概念是,当客户端提交应用程序时,RM会将应用程序元数据(即ApplicationSubmissionContext)保留在可插拔的状态存储中,并保存应用程序的最终状态,
例如完成状态(失败,终止,已完成)和诊断时的诊断应用程序完成。此外,RM还会保存安全密钥,令牌等凭据,以便在安全的环境中工作。任何时候RM关闭,
只要在状态存储中可以获得所需的信息(即应用程序元数据以及在安全环境中运行的凭据),当RM重新启动时,它可以从状态存储中获取应用程序元数据并重新提交申请。
如果应用程序在RM关闭之前已经完成(即失败,被杀死,已完成),RM将不会重新提交申请。
在RM停机期间,NodeManagers和客户端将继续轮询RM,直到RM出现。当RM变为活动状态时,它将向所有通过心跳与之交谈的NodeManager和ApplicationMaster
发送重新同步命令。从Hadoop 2.4.0版本开始,NodeManagers和ApplicationMaster处理此命令的行为是:NMs将终止其所有托管容器并重新注册RM。从RM的角度来看,
这些重新注册的NodeManagers与新加入的NM类似。AM(例如MapReduce AM)在收到重新同步命令时会被关闭。在RM重新启动并加载所有应用程序元数据,
来自状态存储的凭据并将它们填充到内存中之后,它将为尚未完成的每个应用程序创建一个新的尝试(即ApplicationMaster)并像往常一样重新启动该应用程序。
阶段2:保持工作的RM重启
从Hadoop 2.6.0开始,我们进一步增强了RM重启功能,以解决在RM重启时不会杀死在YARN集群上运行的任何应用程序的问题。
除了在第1阶段已经完成的所有基础工作以确保应用程序状态的持久性并在恢复时重新加载该状态,阶段2主要侧重于重构YARN集群的整个运行状态,
其中大部分是状态RM内部调度程序跟踪所有容器的生命周期,应用程序的余量和资源请求,队列的资源使用等。这样,RM不需要终止AM并从头
开始重新运行应用程序它在第1阶段完成。应用程序可以简单地与RM重新同步,并从中断处继续。
RM利用从所有NM发送的容器状态来恢复其运行状态。当NM与重新启动的RM重新同步时,NM不会杀死容器。它继续管理容器,并在重新注册时将容器状态发送到RM。
RM通过吸收这些容器的信息来重建容器实例和相关应用程序的调度状态。与此同时,AM需要将未完成的资源请求重新发送给RM,因为RM可能会在关闭时丢失未完成的请求。
使用AMRMClient库与RM通信的应用程序编写者无需担心AM在重新同步时向RM重新发送资源请求的部分,因为它自动由库本身处理。
三、NodeManager Restart
1、介绍
本文档概述了NodeManager(NM)重启,该功能可以重新启动NodeManager,而不会丢失节点上运行的活动容器。在高级别,
NM在处理容器管理请求时将任何必要的状态存储到本地状态存储。当NM重新启动时,它通过首先加载各个子系统的状态然后让这些子系统使用加载的状态执行恢复来恢复。
ResourceManager HA、ResourceManagerRestart、NodeManager Restart配合使用比较好;
最新文章
- JavaScript基础
- sql 中的Bulk和C# 中的SqlBulkCopy批量插入数据 ( 回顾 and 粗谈 )
- photoshop拾色器如何恢复默认?
- Document树的解析方法
- 在 docker中 运行 mono /jexus server 并部署asp.net mvc站点
- 昨天一日和彭讨论post请求数据的问题
- 使用buildroot编译bind DNS服务器
- linux运维工程师,必须掌握以下几个工具
- 再看JavaScript线程
- JQuery树形目录制作
- ElasticSearch+Kibana 索引操作
- shell-2
- 【Win10】正常上网但ping不通外网
- PYTOGO之旅——环境搭建
- centos下删除MYSQL 和重新安装MYSQL
- 如何用chrome注册版权登记系统
- BZOJ.4320.[ShangHai2006]Homework(根号分治 分块)
- Confluence 6 指派和撤销空间权限
- redis参数改进建议
- NB-IoT移远BC95使用小结