CUDA编程模型之内存管理
CUDA编程模型假设系统是由一个主机和一个设备组成的,而且各自拥有独立的内存。

主机:CPU及其内存(主机内存),主机内存中的变量名以h_为前缀,主机代码按照ANSI C标准进行编写
设备:GPU及其内存(设备内存),设备内存中的变量名以d_为前缀,设备代码使用CUDA C标准进行编写
一个典型的CUDA程序实现流程:
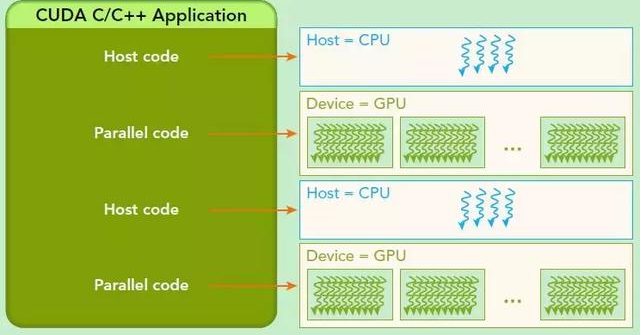
1.把数据从CPU内存拷贝到GPU内存
- 在CPU上申请内存:float *h_A;
h_A=(float*)malloc(nBytes);
- 在GPU上申请内存:float *d_A;
cudaMalloc((float**)&d_A,nBytes);
- 数据传输:cudaMemcpy(d_A,h_A,nBytes,cudaMemcpyHostToDevice);
2.调用核函数对存储在GPU内存中的数据进行操作
3.将数据从GPU内存传送回到CPU内存
- 数据传输:cudaMemcpy(h_C,d_C,nBytes,cudaMemcpyDeviceToHost);
- 释放GPU内存:cudaFree(d_A);
- 释放CPU内存:free(h_A);
说明:
1.GPU内存分配:cudaMalloc函数
函数原型:cudaError_t cudaMalloc(void** devPtr, size_t size)
该函数负责向设备分配一定字节的线性内存,并以devPtr的形式返回指向所分配内存的指针。
2.主机和设备之间的数据传输:cudaMemcpy函数
函数原型:cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind)
该函数以同步方式执行,从src指向的源存储区复制一定数量的字节到dst指向的目标存储区。复制方向由kind指定。
kind有四种选择:cudaMemcpyHostToHost、cudaMemcpyHostToDevice、cudaMemcpyDeviceToHost、cudaMemcpyDeviceToDevice
如果GPU内存分配成功,函数返回cudaSuccess;否则返回cudaErrorMemoryAllocation
可以使用CUDA运行时函数将错误代码转化为可读的错误信息:char* cudaGetErrorString(cudaError_t error)
3.释放GPU内存:cudaFree函数
函数原型:cudaError_t cudaFree(void* devPtr)
最新文章
- 【C#】安装windows服务
- NOIP2001 一元三次方程求解[导数+牛顿迭代法]
- [Unity3D]添加音效说明
- XE3随笔18:实例 - 解析 Google 关键字搜索排名
- [CentOS]安装命令行终端Terminator工具
- Java_一些特殊的关键字详(?)解
- Linux内核态用户态相关知识
- permission denied部署django 遇到没有python_egg_cache的问题解决
- Windows8 正式版最简单的去除桌面水印方法
- nyoj组合数
- Linux环境快速部署Zookeeper集群
- ANT 配置和安装 1
- eclipse调试hadoop2.2.0源码笔记
- 【linux】之查看磁盘占用情况
- JavaScript之破解数独(附详细代码)
- Redis实现分布式锁原理与实现分析
- Git诞生
- kettle Spoon.bat运行闪退
- mxnet img2rec的使用,生成数据文件
- Linux下修改当前用户的最大线程数和 open files